
朴素Bayes分类实践
一、回顾概率论
1、条件概率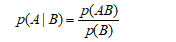 ,这个公式说白了就是不同样本空间下的概率问题!
,这个公式说白了就是不同样本空间下的概率问题!
2、全概率公式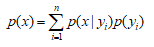 ,证明不难。
,证明不难。
3、贝叶斯公式 ,这个公式可厉害了,根据原有的数据,由因知果,再执果索因。根据上述公式,推导过程简单的不要不要的。
,这个公式可厉害了,根据原有的数据,由因知果,再执果索因。根据上述公式,推导过程简单的不要不要的。
二、自制文本分类
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 11 07:56:14 2018
@author: Administrator
"""
#创建词汇表
def loadDataSet():
email=[ ['菜鸟','包裹'] , ['邮政','物流','您的','快递','投递','揽投员'],['快件','货号','有效证件','取件','速运'] ,
['您','验证码','本人','操作','请','忽略','短信'],['十分钟','有效'],['验证码','请','完成','验证'],
['尊敬','恭喜','用户','抽奖','机会'],['身份证','贷款','提现'],['您好','您','账户','额度','提现'],
['温馨提醒','您','账户','余额','当前','正常','使用','尽快','交费'],['订单','您','已购']]
label=['快递','验证码','垃圾短信','个人账户']
index=[0,0,0,1,1,1,2,2,2,3,3];
return email,label,index;
#去重获得词汇集,每类词汇集
def vocalTable(dataset,index):
vocaSet=set([]);
vocaClassifier=[] #各类词汇集
typey=set(index)
length=len(typey)
for i in range(0,length): #h创建空集合放对应类型词汇
vocaClassifier.append(set([]));
for i in range(0,len(dataset)):
vocaSet=vocaSet|set(dataset[i]);
vocaClassifier[ index[i] ]= vocaClassifier[ index[i] ] | set(dataset[i]);
vocaSetlist(vocaSet);
for i in range(0,length): #h创建空集合放对应类型词汇
vocaClassifier[i]=list(vocaClassifier[i]);
return list(vocaSet),vocaClassifier,typey
#计算概率
#email,label,index=loadDataSet()
#vocaSet,vocaClassifier,typey=vocalTable(email,index)
def calPossiblity(typey,indexy,vocaClassifier,email): #typey 指 y的类型数值,indexy指数据集
#计算 p(y=Ck)
p_y_k=[];
N=len(typey)
for i in typey:
cnt=0
for j in indexy:
if(j==i):
cnt+=1
p_y_k.append(cnt/N);
#计算 p( x=xij | y=ck )
length=len(typey);
numtype=[]; #每一类的词汇数量
numword=[]; #每类词汇数量
for i in range(0,length):
x=[];
for j in range(0,len(vocaClassifier)):
x.append(0);
numtype.append(0);
numword.append(x);
for i in range(0,len(email)):
for j in email[i]:
for k in range(0,len(vocaClassifier[i])):
if( vocaClassifier[i][k] == j ):
numword[i][j]+=1;
break;
numtype[ indexy[i] ]+=len(email[i])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号