
.net 数据缓存(二)之Redis部署
现在的业务系统越来复杂,大型门户网站内容越来越多,数据库的数据量也越来愈大,所以有了“大数据”这一概念的出现。但是我们都知道当数据库的数据量和访问过于频繁都会影响系统整体性能体验,特别是并发量高的系统。为此,我们通过数据缓存来,减轻数据库的压力。为此,随着时间的步伐,各式各样的缓存技术的出现,让我们对于这些技术有些眼花缭乱。不是说功能最全的最先进,就是适合自己。我们要看看自己系统的定位去评估自己的系统适合使用哪种缓存机制。当然,也可以通过定义缓存接口,以后方便缓存机制的替换。下面我们来了解下缓存的概念、分类及发展趋势。
一、 部署环境a、Redis版本3.0.5 选取原因:只有3.0以后的版本才官方支持分布式集群
b、服务器操作系统CentOS 7 选取原因:Redis官方版本是Linux环境下的
二、 知识准备1、概念准备首先要知道为什么要对做缓存分布式集群,一是我们知道本地缓存压力大时,不能不满足需求,自然会考虑到把缓存放到网络服务器上,根据业务需求增大,这样可以进行水平扩展;二是我们知道当分布式部署方案的节点服务器各自承担自己负责的工作,与其他节点相互独立,这是当某台节点宕机或者网络异常,就会导致不能访问,这样我们如果将各个节点,进行单独的集群式部署,可以达到安全性要求了。
集群的目的我们初步了解了,但是我之前的之前的理解,用两三台个服务器,这样不就算是集群了么。其实不然,Redis起初已经提供了主/从模式,这最多只能算是备份,一台服务器挂了,另一台服务器顶上,而没有达到真正意思上的集群。真正意义上的集群,不是备份,而且含有均衡的作用。那怎么达到均衡呢?我们建议所有的生产环境至少部署5个节点,因为在较小的集群中,单点故障意味着复制的需求很可能得不到满足。这将导致性能下降并且增加数据丢失的风险。另外,小于5个节点的集群将使得75%至100%的节点需要响应每个请求,这将导致不必要的负载从而降低性能。
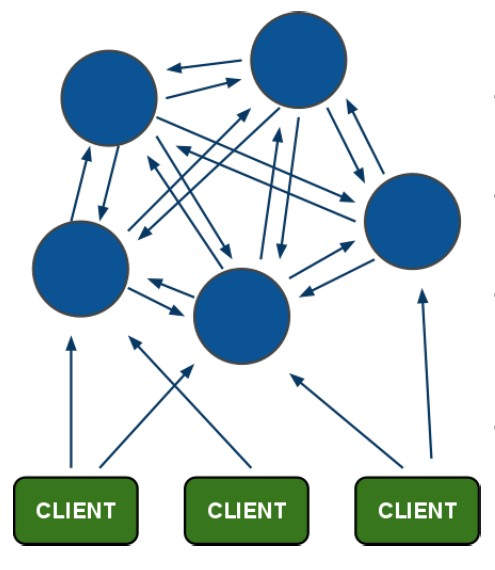
2、拓扑预览
![]() 集群部署拓扑图
集群部署拓扑图![]() 容错图三、 部署实践1、安装好CentOS7(为让不熟悉的Linux的园友能够不陌生,能够在图形化界面完成尽量在图形化界面操作完成)
容错图三、 部署实践1、安装好CentOS7(为让不熟悉的Linux的园友能够不陌生,能够在图形化界面完成尽量在图形化界面操作完成)
2、在redis.io下载最新redis源码包,然后右键解压![]() 3、编译和安装
3、编译和安装注意这个,一定要登录root用户才行。桌面用户一般是没有root权限的。(由于我已经编译和安装过界面,会有不同)
4、 配置redis的配置文件a、建立6个文件夹b、建立配置文件(将端口号修改后,复制粘贴到建立好的每个文件夹中)c、启动6个redis-serverd、实现集群这我们需要使用一个(redis-trib.rb)程序,需要ruby环境支持
e、执行集群命令e、检验结果总结,之前看别人写的,总认为知道了,但是真的自己动起手来,总是遇到这样或者那样的问题。遇到问题不可怕,就怕解决不了问题。Linux不懂,redis概念也不太清楚,当命令敲起来,慢慢豁然开朗。学习=理论+实践,这次又有很大的体会了。
参考一:官方中文翻译集群教程












本文由z-albert原创并发布于博客园,欢迎转载,未经本人同意不可以修改原文内容且必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。如有问题,欢迎留言,也可以通过y442926727@qq.com 联系我,非常感谢。
由于本人技术能力和文字表达能力有限,若有描述错误或描述不清,恳请批评指正!有兴趣者可加群:144063225参与交流
更多内容,敬请观注博客:http://www.cnblogs.com/z-albert/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号