
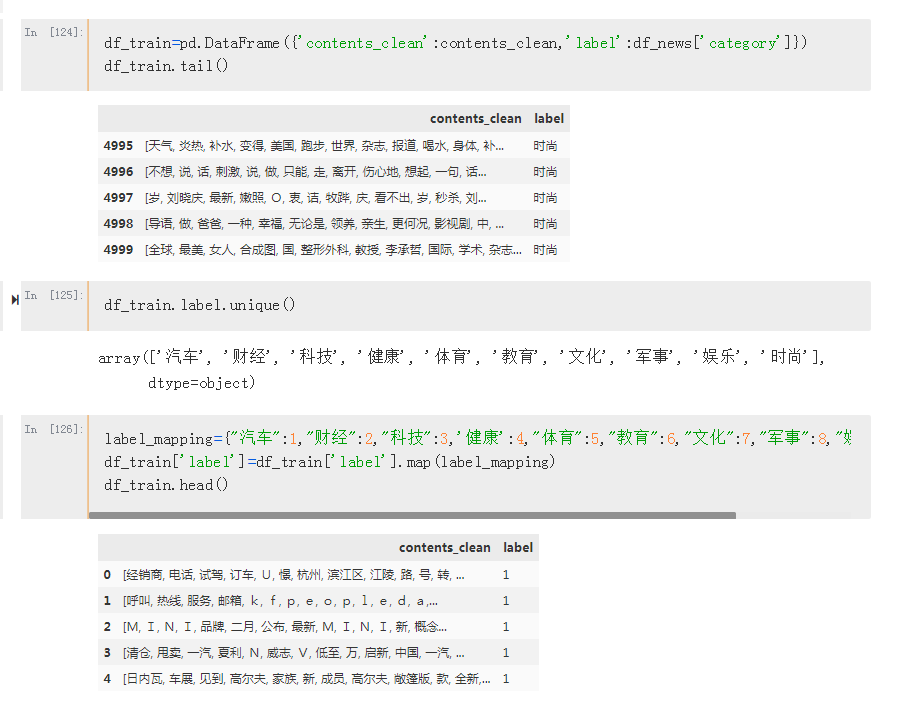
基于搜狗实验室的新闻数据分析
详细代码和数据(part02/python文本分析/news_sougou)可以查看这个:https://github.com/HappyZXY/machineLearning
数据源:
http://www.sogou.com/labs/resource/ca.php
来自若干新闻站点2012年6月-----7月期间国内、国际、体育、社会、娱乐等18个频道的新闻算数据,提供url和正文信息
格式说明:
数据格式为
<doc>
<url>页面URL<url>
<docno>页面ID</docno>
<contenttitle>页面标题</contenttitle>
<content>页面标题</content>
</doc>
注:content字段是去除了HTML标签,保存的是新闻正文文本
panda速查手册


1 #数据读取与导出 2 import pandas as pd 3 import numpy as np 4 pd.read_csv(filename,sep='')#从csv文件导入数据 5 pd.read_csv(filename,sep='',header=none)#导入没有头的文件 6 #构造DataFrame数据 7 df=pd.DataFrame([[1,2,3],[4,5,6]],columns=['f1','f2','f3']) 8 9 #导出数据 10 df.to_csv(filename,index=False) 11 12 #数据查看 13 df.head(n)#查看数据的前n行 14 df.tail(n)#查看DataFrame对象的最后n行 15 df.shape()#查看行数和列数 16 df.info()#查看索引、数据类型和内存信息 17 df.describe()# 查看数值型列的汇总统计 18 s=df['user_id']#根据列名以Serise的形式返回列 19 df[['user_id','item_id']]#以DataFrame形式返回多列 20 s.iloc['index_one']#按索引选取 数据 21 df.iloc[0,:]#返回第一行 22 df.iloc[0,0]#返回第一列的第一个元素 23 df.sample(frac=0.5)#采样 24 25 #数据整理 26 pd.isnull()#检查DataFrame对象中的控制,并返回一个Boolean数组 27 df.dropna(axis=0)#删除所有包含空值的行 28 df.dropna(axis=1)#删除所有包含空值的列 29 df.dropna(axis=1,thresh=n)#删除所有小于n个非空值的行 30 df.fillna(x)#用x替换DataFrame对象中的所有的空值 31 df.fillna(df.median)#中位数填充 32 s.replace(1,'one')#用'one'代替所有等于1的值 33 df.columns= ['a','b','c']#重命名列名 34 df.rename(columns=lambda x:x+1)#批量重命名列名 35 df.rename(index=lambda x:x+1 )#批量重命名索引 36 37 #数据处理 38 df[df[col]>0.5]#选择col列的值大于0.5的行 39 df.sort_values(by='col',ascending=True)#按照列col排序数据,默认升序排序 40 41 #数据合并 42 df1.append(df2)#将df2中的行添加到df1的尾部 43 pd.concat([df1,df2],axis=1)#按列合并 44 pd.concat([df1,df2],axis=0)#按行合并 45 46 df.corr()#返回所有列与列之间的相关系数 47 df.count()#返回每一列中的非空值的个数 48 df.dtypes()#查看数据类型 49 df['uesr_id'].hist()#查看变量分布 50 df.isnull().sum()#查看每一列缺失值的情况 51 df['user_id'].unique()#查看数据取值 52 53 54 a.sort_index(axis=1,ascending=False)#axis=1表示对所有的columns进行排序 55 a.sort(column='x')#对DataFrame中的值进行排序 56 选取对象 57 a['x']#选取特定的列, 58 选取行数据,通过切片[]来选择 59 a[0:3]#选取前三行的数据 60 61 loc是通过 行标签来选择数据 62 iloc通过行号索引行数据 63 ix通过行标签或者行号索引行数据(基于loc和iloc的混合) 64 a.loc['one'] #默认表示选取行为'one'的行 65 a.loc[:,'a','b']表示选取所有行以及columns为a,b的列 66 a.loc[['one','two'],['a','b']]表示选取‘one’和‘two’这两行以及columns为ab的列 67 a.loc[0]表示选取第一行的数据 68 69 条件选择 70 a[a.c>0]表示选择c列中大于0 的数据 71 赋值 72 a.loc[:,['a','c']=9 即将a和c列的所有行中的值设置为9 73 74 a.dropna(how='any')表示去掉包含缺失值的行 75 a.fillna(value=x) 表示用值为x 的数来对缺失值 进行填充 76 77 统计某一列x中格格之出现的次数 a['x'].value_counts() 78 79 对数据应用函数 a.apply(lambda x :x.max()-x.mnin())表示 返回所有列中最大值-最小值的差
分词-清洗-统计-词云可视化
首先导入将使用的库和数据 ,这里数据存放在data文件下了,此次试验以val.txt为测试,数据量5000,较小
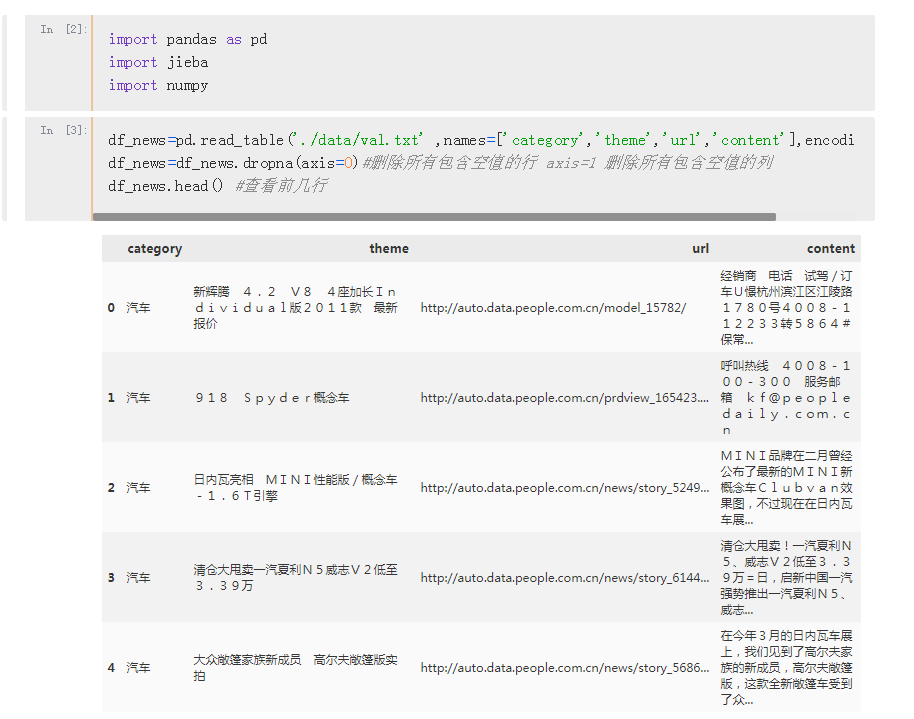

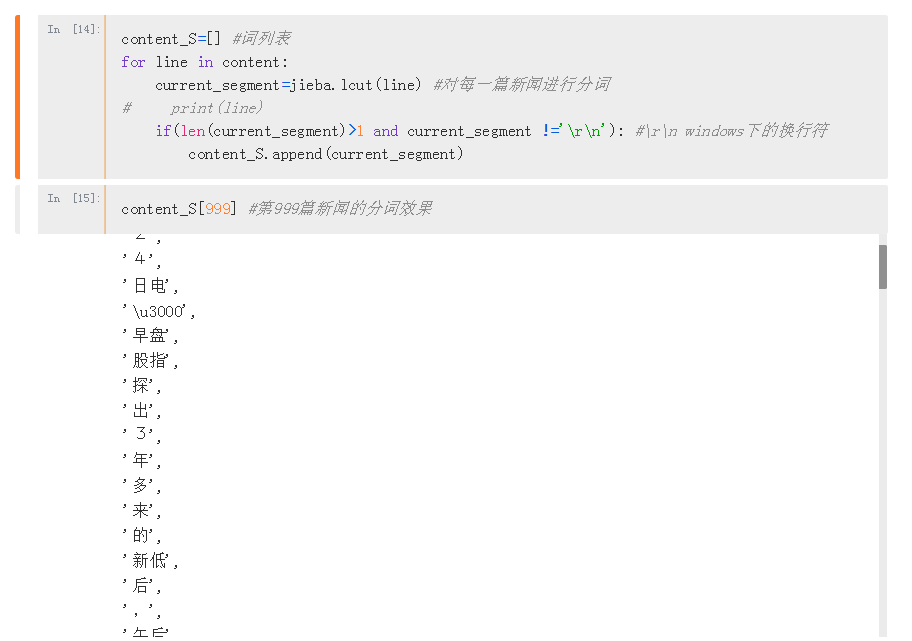
可视化展示每一篇新闻的分词效果
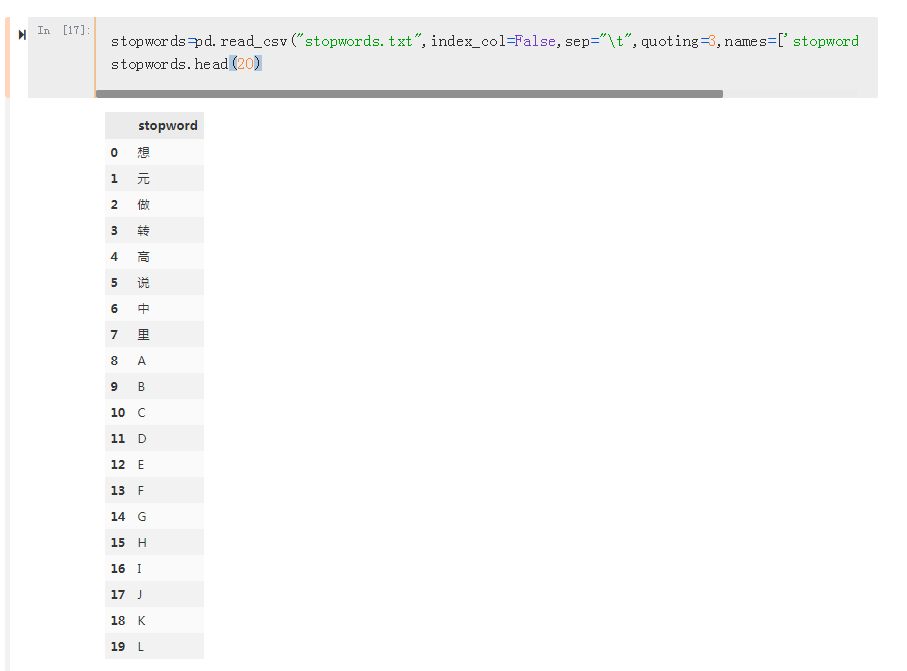
读取停止词,可根据需求适量增加,同样使用panda展示出来 ,这里取样为前20个
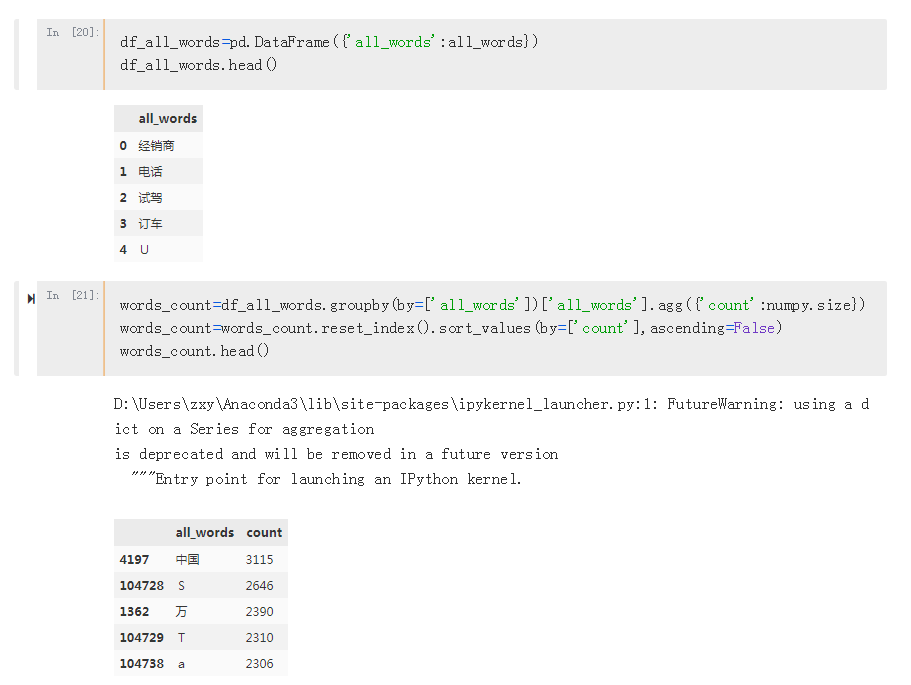
根据停止词表,对每一篇新闻,drop掉所有的意义不大的词,

drop停止词后,可视化显示所有的词,然后根据这些词进行分组统计,查看每一词在文章中出现的次数
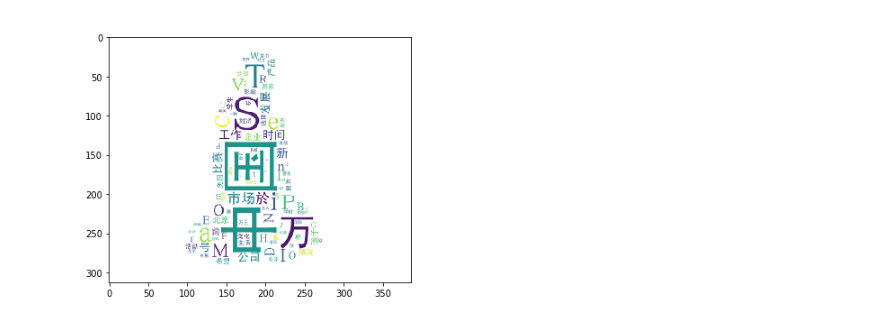
emmmm,又是词云展示一下,老套路了,不多解释,,这里词去除的有些不干净,可自行改进
TF-IDF提取关键词与LDA主题模型
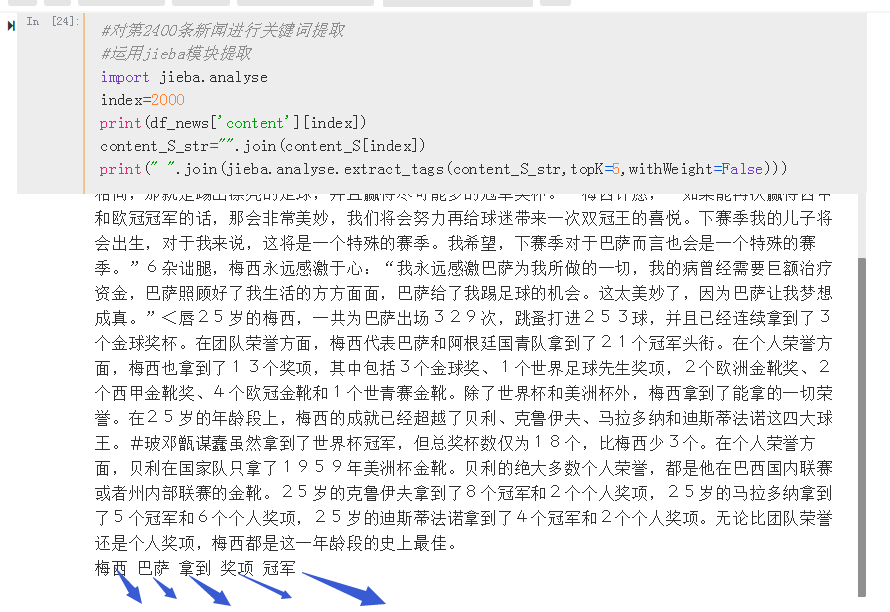
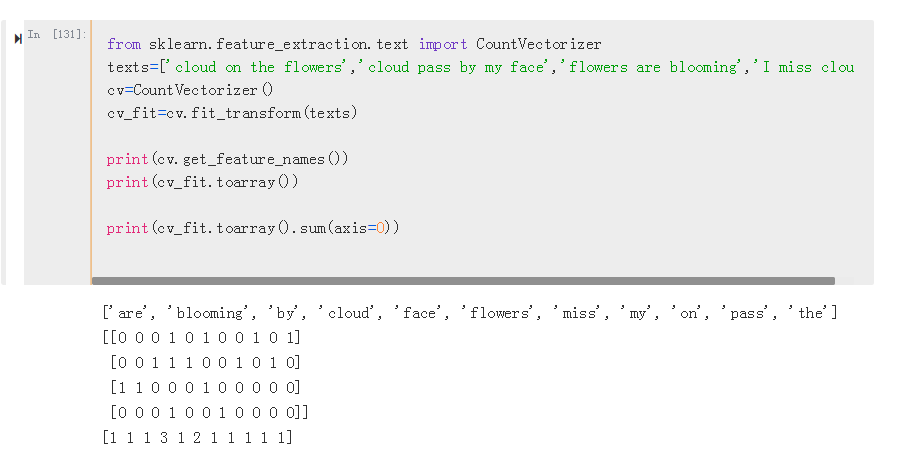
调用jieba.analyse.extract_tags函数,提取出关键词,关于使用方法,官方源码如下
1 def textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False): 2 """ 3 Extract keywords from sentence using TextRank algorithm. 4 Parameter: 5 - topK: return how many top keywords. `None` for all possible words. 6 - withWeight: if True, return a list of (word, weight); 7 if False, return a list of words. 8 - allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v']. 9 if the POS of w is not in this list, it will be filtered. 10 - withFlag: if True, return a list of pair(word, weight) like posseg.cut 11 if False, return a list of words 12 """
LDA主题模型(LDA文档主题生成模型)
LDA(Latent Dirchlet Allocation )是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过一定概率选择了某个主题,并从主题中以一定概率选择某个词语,这样一个过程。文档到主题服从多项式分布,主题到词也服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或者语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文章视为一个词频向量,从而将文本信息转化为易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
LDA生成过程
LDA应用
在实际的运用中,LDA可以直接从gensim调,主要的一些参数有如下几个:
corpus:语料数据,需要包含单词id与词频
num_topics:我们需要生成的主题个数(重点调节)
id2word:是一种id到单词的映射(gensim也有包生成)
passes:遍历文本的次数,遍历越多越准备
alpha:主题分布的先验
eta:词分布的先验
官方实例如下
comment_texts是一个list,每一个元素都是一篇文章,也是list结构
dow2bow是将文本转换为词袋形式
初始化的时候对每一个词都会生成一个id,新的文本进去的时候,返回该文本每一个词的id,和对应的频数,对于那些不存在原词典的,可以控制是否返回。
1 from gensim.test.utils import common_texts 2 from gensim.corpora.dictionary import Dictionary 3 4 # Create a corpus from a list of texts 5 common_dictionary = Dictionary(common_texts) 6 common_corpus = [common_dictionary.doc2bow(text) for text in common_texts] 7 8 # Train the model on the corpus. 9 lda = LdaModel(common_corpus, num_topics=10)
原理到这里,下面继续

可以看出第一个模型的词分布,‘爆料’和‘中’占比较大(这里topn控制了输出的单词个数,对应的单词可以通过之前生成dict找出)
继续输出前20主题的看一下效果





参考文献:
[1] 搜狗实验室 http://www.sogou.com/labs/resource/ca.php 2019-6-29 15:00
[2] 简书.LDA应用和理解 https://www.jianshu.com/p/74ec7d5f6821 2019-7-1 2019-6-29-23:00
[3] 百度百科.LDA https://baike.baidu.com/item/LDA/13489644?fr=aladdin#ref_[1]_13230719 2019-6-30 7:12
[4] 简书.利用TF-IDF与余弦相似性自动提取关键词 2019-7-1 15:30

