python3爬虫 -----华东交大校园新闻爬取与数据分析
~~~~~~~~~~~~~~~~步骤~~~~~~~~~~~~~~~~~~~
~~ ~~
1):获取新闻代码如下
1 import requests 2 import requests.exceptions 3 import re 4 import json 5 6 #请求头,防止防爬虫的网页 7 headers={ 8 "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 9 } 10 11 #获取一张网页上的内容 12 def get_one_page(url): 13 try: 14 res = requests.get(url, headers=headers) 15 if res.status_code == 200: 16 return res.text 17 return None 18 except Exception: 19 return None 20 21 #根据网页上的内容,再析取新闻标题 22 def parse_one_page(html): 23 pattern=re.compile('<td align="left".*?<a href.*?>(.*?)</a>.*?</td>',re.S) 24 items=re.findall(pattern,html) 25 return items 26 # for item in items: 27 # yield { 28 # "title":item.split() 29 # } 30 31 32 #写入文件 33 def write_to_file(content): 34 with open('news_ecjtu.txt','a',encoding='utf-8') as f: 35 f.write(json.dumps(content,ensure_ascii=False)+'\n') 36 f.close() 37 38 39 def main(page): 40 if(page): 41 page+=1 42 url='http://xw.ecjtu.jx.cn/1083/list'+str(page)+'.htm' 43 else: 44 url='http://xw.ecjtu.jx.cn/1083/list.htm' 45 html=get_one_page(url) 46 47 for item in parse_one_page(html): 48 write_to_file(item) 49 50 51 if __name__ == '__main__': 52 for i in range(10): #582 53 main(i)
2):获取结果如下
"中国铁总和江西省政府正式签署共建我校协议" "江西省第十五届运动会我校捷报频传" "多措并举促进毕业生更高质量更充分就业" "【公益广告】“时代楷模”王传喜" "我校2位学生荣获“茅以升铁道教育希望之星奖”" "学校推进落实《大型科研设备规划》" "校领导到基础实验与工程实践中心调研:培育工匠精神 实现智能化管理" "青年师生学习宣传贯彻团十八大精神" ~~~~~~~~~样例~~~~~~~~~~
3):分析新闻关键词词频
CountVectorizer,通过fit_transform函数将文本中的词语转换为词频矩阵
功能代码如下:
1 # -*- coding :utf-8 -*- 2 # CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵, 3 # 矩阵元素weight[i][j] 表示j词在第i个文本下的词频,即各个词语出现的次数; 4 # 通过get_feature_names() 5 # 可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果。 6 # TfidfTransformer也有个fit_transform函数,它的作用是计算tf-idf值。 7 8 9 import jieba 10 import jieba.posseg 11 import os 12 import sys 13 from sklearn import feature_extraction 14 from sklearn.feature_extraction.text import TfidfTransformer 15 from sklearn.feature_extraction.text import CountVectorizer 16 import sys 17 18 19 from numpy import * 20 21 def read_from_file(file_name): 22 with open(file_name,'r',encoding='utf-8') as f: 23 words=f.read() 24 return words 25 26 27 def main(path1,name,path2): 28 29 with open(path1+name+".txt",'r',encoding="utf-8") as f: 30 f_list=f.read() 31 dataList=f_list.split('\n') 32 data=[] 33 words=read_from_file("D:\\PyCharm_Project\\My_project\\Dictionary\\chineseStop_word") 34 for line in dataList: 35 data.append(" ".join(jieba.cut(line))) 36 37 38 39 freqWord=CountVectorizer(stop_words='english') #将所得的词转换为词频矩阵 40 41 # 第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵 42 tfidf=TfidfTransformer().fit_transform(freqWord.fit_transform(data)) 43 44 words=freqWord.get_feature_names() #获得词袋模型中所有的词语 45 weight=tfidf.toarray() 46 tfidfDict={} 47 48 for i in range(len(weight)): 49 for j in range(len(words)): 50 getWord=words[j] 51 getValue=weight[i][j] 52 if getValue !=0: 53 if getWord in tfidfDict.keys(): 54 tfidfDict[getWord]+=float(getValue) 55 else: 56 tfidfDict.update({getWord:getValue}) 57 sortted_tfidf=sorted(tfidfDict.items(),key=lambda d:d[1],reverse=True) 58 59 print('Start Kmeans:') 60 from sklearn.cluster import KMeans 61 clf = KMeans(n_clusters=10) 62 s = clf.fit(weight) 63 print(s) 64 65 # 20个中心点 66 print(clf.cluster_centers_) 67 68 # 每个样本所属的簇 69 print(clf.labels_) 70 i = 1 71 while i <= len(clf.labels_): 72 print(i, clf.labels_[i - 1]) 73 i = i + 1 74 75 # 用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数 76 print(clf.inertia_) 77 with open(path2+name+'result.csv',"w",encoding="utf-8") as f: 78 for i in sortted_tfidf: 79 f.write(i[0]+'\t'+str(i[1])+'\n') 80 81 82 if __name__ == '__main__': 83 # names={'story','story2'} 84 # for name in names: 85 # main(name) 86 path1="D:\\PyCharm_Project\\My_project\\news\\" 87 name="news_ecjtu" 88 path2="D:\\PyCharm_Project\\My_project\\parseResult\\" 89 main(path1,name,path2)
效果如下:
我校 7.0208354759542715 学院 3.8223325570171203 2018 3.815764749721242 教育 3.399237761450319 调研 3.2971327488479263 工作 3.1346706185473137 合作 2.9082744591115333 毕业生 2.6176374142071013 公益广告 2.4443878020399605 时代 2.4443878020399605 楷模 2.4443878020399605 来校 2.3190139465687243 校领导 2.1889679172246517 作风 2.1637628125695234 江西省 2.16162847305444 高校 2.128702943062588 建设 2.0958223398319404 张黎明 2.0646025671476895 校友 1.9667841510938553 推进 1.9569110239878906 学校 1.7725392141069154 提升 1.732203497544248 学生 1.6831009269305646 评估 1.6419528753463422 创业 1.6353791486937332 落实 1.6293337473008869 特色 1.6019056409789132 大学生 1.581282636609164 交通 1.5618754858859953 全省 1.5235338340894855 万明 1.4743835231840472 花椒 1.451354632105049 师生 1.4082883987540953 招生 1.3684278178093492 发展 1.3471490121262661 作品展 1.3273917270546678 做好 1.31886337322391 工程 1.310089644126616 宣传 1.3097551321730325 毕业 1.2968027899458847 创新 1.291911022554044 走访 1.287239425873281 参加 1.2846089388204354 全国 1.2521245761589734 带队 1.2409721952698711 服务 1.2248869078147047 大学 1.2216528368982398 人工智能 1.1866932552420832 强化 1.143664790062435 管理 1.132810412234202 研究生 1.1220288442489132 举行 1.1002480430262072 成立 1.0979689466014984 办学 1.0631396741720918 人才 1.0413024537617568 青年 1.039299679715829 建筑学 1.0390330826994207 检查 1.0341832074088995 中心 1.0280680758280576 现场 1.010890033456509 专家 1.0100044382096787 孔目 0.9947013515882996 改革 0.9941181774133574 协议 0.9894497085333555 签署 0.9894497085333555 经管 0.9862496233342563 开展 0.9707440311967135 ~~~~~~~~~~~样例~~~~~~~~~~~
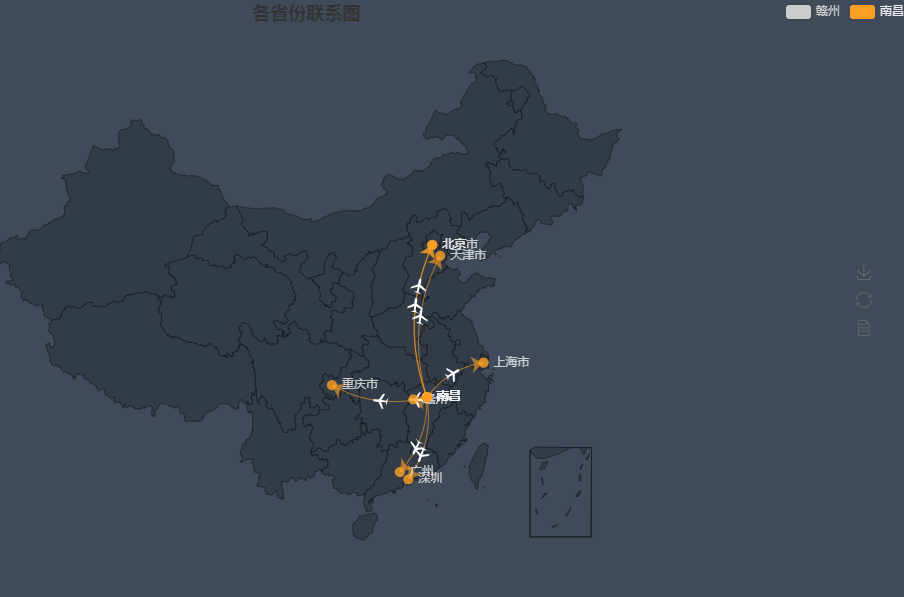
4):可视化学校间联系
注意pyecharts的坑!,,地图显示一半什么的,
1 from sklearn.feature_extraction.text import TfidfVectorizer 2 import jieba 3 4 with open("news_ecjtu.txt", 'r', encoding="utf-8") as f: 5 f_list = f.read() 6 dataList = f_list.split('\n') 7 data = [] 8 for line in dataList: 9 data.append(" ".join(jieba.cut(line))) 10 11 12 tfidf=TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b") 13 weight=tfidf.fit_transform(data).toarray() 14 word=tfidf.get_feature_names() 15 16 dict1 = {} 17 f = open('D:\\PyCharm_Project\\My_project\\Dictionary\\provinces.txt', 'r', encoding="utf-8") 18 i = 0 19 for line in f.readlines(): 20 tmp = line.strip() 21 dict1[tmp] = i 22 23 dict2 = {} 24 f = open('D:\\PyCharm_Project\\My_project\\Dictionary\\Universities.txt', 'r', encoding="utf-8") 25 i=0 26 for line in f.readlines(): 27 tmp = line.strip() 28 dict2[tmp] = i 29 30 31 for key,value in tfidf.vocabulary_.items(): 32 if key in dict1.keys(): 33 dict1[key] = value 34 if key in dict2.keys(): 35 dict2[key]=value 36 37 print(dict1) 38 print(dict2) 39 40 41 42 from pyecharts import GeoLines, Style 43 import echarts_china_cities_pypkg 44 import echarts_china_counties_pypkg 45 import echarts_china_provinces_pypkg 46 47 style = Style( 48 title_top="#fff", 49 title_pos = "center", 50 width=1200, 51 height=600, 52 background_color="#404a59" 53 ) 54 55 style_geo = style.add( 56 is_label_show=True, 57 line_curve=0.2, 58 line_opacity=0.6, 59 legend_text_color="#eee", 60 legend_pos="right", 61 geo_effect_symbol="plane", 62 geo_effect_symbolsize=15, 63 label_color=['#a6c84c', '#ffa022', '#46bee9'], 64 label_pos="right", 65 label_formatter="{b}", 66 label_text_color="#eee", 67 ) 68 69 data_ganzhou = [ 70 ['赣州', '上海'], 71 ['赣州', '北京'], 72 ] 73 74 75 76 77 data_nanchang = [ 78 ['南昌','赣州'], 79 ['南昌','北京'], 80 ['南昌','深圳'], 81 ['南昌','广州'], 82 ] 83 84 85 86 for key,value in dict1.items(): 87 if key=="南昌": 88 continue 89 else: 90 if value !=0: 91 tmp = ['南昌'] 92 tmp.append(key) 93 data_nanchang.append(tmp) 94 95 print(data_nanchang) 96 97 geolines = GeoLines("各省份联系图 ", **style.init_style) 98 geolines.add("赣州", data_ganzhou,**style_geo) 99 geolines.add("南昌", data_nanchang,**style_geo) 100 101 geolines.render()
输出结果部分如下:
{'北京市': 11, '天津市': 26, '上海市': 1, '重庆市': 53, '河北省': 0, '山西省': 0, '辽宁省': 0, '吉林省': 0, '黑龙江省': 0, '江苏省': 0, '浙江省': 0, '安徽省': 0, '福建省': 0, '': 0, '山东省': 0, '河南省': 0, '湖北省': 0}
{'北京大学': 0, '清华大学': 42, '浙江大学': 40, '复旦大学': 22, '中国人民大学': 4, '上海交通大学': 0, '武汉大学': 36, '南京大学': 15, '中山大学': 5, '吉林大学': 18, '华中科技大学': 13, '四川大学': 20, '天津大学': 25, '南开大学': 16, '西安交通大学': 49, '中国科学技术大学': 0, '中南大学': 2, '哈尔滨工业大学': 19, '北京师范大学': 12, '山东大学': 27, '厦门大学': 17, '东南大学': 0, '同济大学': 0, '北京航空航天大学': 0, '大连理工大学': 0, '东北大学': 0, '华南理工大学': 0, '华东师范大学': 0, '北京理工大学': 0, '西北工业大学': 0, '重庆大学': 0, '兰州大学': 0, '中国农业大学': 0, '电子科技大学': 0, '湖南大学': 0, '东北师范大学': 0, '西南大学': 0, '武汉理工大学': 0, '西南交通大学': 0, '北京交通大学': 0, '华中师范大学': 0, '河海大学': 0, '南京农业大学': 0, '南京理工大学': 0, '南京师范大学': 0, '西安电子科技大学': 0, '北京科技大学': 0, '华中农业大学': 0, '郑州大学': 0, '中国海洋大学': 0, '西北大学': 0, '华东理工大学': 0, '中国矿业大学': 0, '南京航空航天大学': 0, '上海大学': 0, '北京协和医学院': 0, '西北农林科技大学': 0, '苏州大学': 0, '北京邮电大学': 0, '中国地质大学(武汉)': 0, '北京化工大学': 0, '上海财经大学': 0, '长安大学': 0, '云南大学': 0, '哈尔滨工程大学': 0, '合肥工业大学': 0, '中国政法大学': 0, '湖南师范大学': 0, '东华大学': 0, '南昌大学': 0, '中南财经政法大学': 0, '昆明理工大学': 0, '深圳大学': 0, '暨南大学': 0, '华南师范大学': 0, '陕西师范大学': 0, '首都师范大学': 0, '江南大学': 0, '福建师范大学': 0, '中央民族大学': 0, '福州大学': 0, '北京工业大学': 0, '广西大学': 0, '燕山大学': 0, '河南大学': 0, '中国石油大学(华东)': 0, '宁波大学': 0, '华南农业大学': 0, '浙江工业大学': 0, '山西大学': 0, '对外经济贸易大学': 0, '浙江师范大学': 0, '北京林业大学': 0, '西南财经大学': 0, '杭州电子科技大学': 0, '上海理工大学': 0, '扬州大学': 0, '天津师范大学': 0, '中央财经大学': 0, '首都医科大学': 0, '东北林业大学': 0, '河北大学': 0, '安徽大学': 0, '辽宁大学': 0, '太原理工大学': 0, '南京工业大学': 0, '新疆大学': 0, '华北电力大学': 0, '湘潭大学': 0, '东北财经大学':
[['南昌', '赣州'], ['南昌', '北京'], ['南昌', '深圳'], ['南昌', '广州'], ['南昌', '北京市'], ['南昌', '天津市'], ['南昌', '上海市'], ['南昌', '重庆市']]
效果图如下: