一.走进Hystrix
hystrix介绍
Hystrix 供分布式系统使用,提供延迟和容错功能,隔离远程系统、访问和第三方程序库的访问点,防止级联失败,保证复杂的分布系统在面临不可避免的失败时,仍能有其弹性。
hystrix历史
hystrix,高可用性保障的一个框架,是Netflix公司API团队从2011年开始做一些提升系统可用性和稳定性的工作,Hystrix就是从那时候开始发展出来的。时至今日,Netflix中每天都有数十亿次的服务间调用,通过Hystrix框架在进行,而Hystrix也帮助Netflix网站提升了整体的可用性和稳定性。
hystrix的适用场景
适用场景:
对于一个分布式系统,不同的的服务间存在着很多依赖,比如服务A依赖服务B、C、D,服务A拿到B、C、D返回的数据,进行下一个环节的操作,这时候如果服务B出现故障,这时候使用hystrix可以确保服务A停止调用服务B,只调用服务C、服务D,使系统能正常的响应,不会因为服务B故障而导致整个系统崩溃。
例如:
短信发送微服务,因为对接了多个渠道,当某个渠道不可用的情况下,hystrix熔断掉,然后采取另外的渠道进行下发。在发送量级比较大的情况,可以减少短信发送进行重试的时间。
不适用场景:
如果你的服务所依赖的服务均是核心业务,不能熔断,这个时候就不能使用hystrix了。
例如:
计费业务,id生成器业务作为核心业务,是整个短信业务的核心,如果引入熔断机制会导致业务流程失败,相当于整个短信业务不可用,所以这类核心无降级的服务是不应该启动hystrix的。
hystrix vs dubbo
也许你们的脑海中会有疑问,就是既然我们的分布式系统都使用了分布式服务治理框架了,例如dubbo,可以设置超时时间来打断未响应的调用;为什么还需要hystrix,这不是多此一举么,其实不然,因为dubbo设置的超时时间并不能减轻服务提供方的压力,当你的服务提供方出现故障时,大量的请求依然会打过来,这时候你的服务提供者不段的进行超时处理,抛timeout异常,也就是提供方依然在不断的接收大量的请求,如果突然来了个流量洪峰,你的web容器的线程就会瞬间被吃光,这时候会导致整个系统卡死,无法再为用户作出任何响应了。
而hystrix可以有丰富的配置,其原理是:在一个窗口时间内针对错误进行计数,当达到阈值则熔断提供方,不在请求该熔断的提供方,然后快速返回。hystrix能够解决服务提供者不可用的场景。他采用了资源隔离模式,通过线程隔离和信号量隔离保护主线程池;使用熔断器避免无节操的重试,并提供断路自动复位功能。下面我们就来看一看如何使用hystrix。
hystrix开发原则
(1)阻止任何一个依赖服务耗尽所有的资源,比如tomcat中的所有线程资源
(2)避免请求排队和积压,采用限流和fail fast来控制故障
(3)提供fallback降级机制来应对故障
(4)使用资源隔离技术,比如bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术),来限制任何一个依赖服务故障导致的影响
(5)通过近实时的统计/监控/报警功能,来提高故障发现的速度
(6)通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
(7)保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
hystrix如何实现目标
(1)通过HystrixCommand或者HystrixObservableCommand来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离
(2)对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是99.5%的访问时间,但是一般我们可以自己设置一下
(3)为每一个依赖服务维护一个独立的线程池,或者是semaphore,当线程池已满时,直接拒绝对这个服务的调用
(4)对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计
(5)如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
(6)当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制
(7)对属性和配置的修改提供近实时的支持
摘抄
App Container可以是我们的应用容器,比如jetty,tomcat,也可以是一个用来处理外部请求的线程池(比如netty的worker线程池)。一个用户请求有可能依赖其他多个外部服务,比如上图中的A,H,I,P,在不可靠的网络环境下,任何的RPC都可能会面临三种情况:成功、失败、超时。如果一次用户请求所依赖外部服务(A,H,I,P)有任何一个不可用,就有可能导致整个用户请求被阻塞。考虑到应用容器的线程数目基本都是固定的(比如tomcat的线程池默认200),当在高并发的情况下,某一外部依赖的服务超时阻塞,就有可能使得整个主线程池被占满,这是长请求拥塞反模式(https://tech.meituan.com/performance_tuning_pattern.html)。
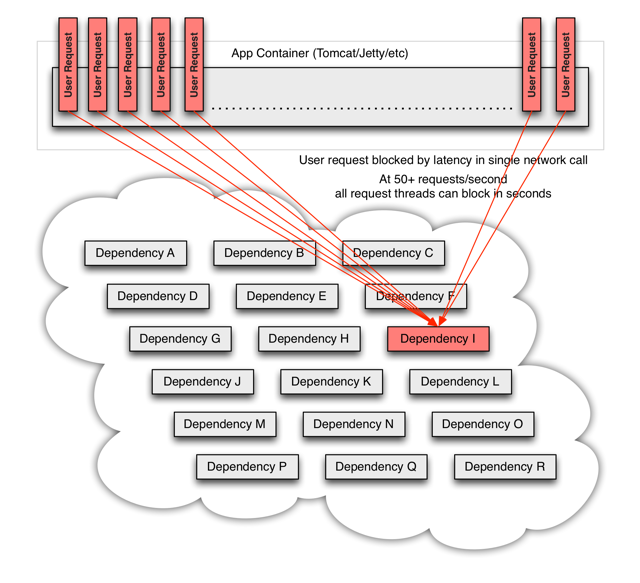
更进一步,线程池被占满就会导致整个服务不可用,而依赖该服务的其他服务,就又可能会重复产生上述问题。因此整个系统就像雪崩一样逐渐的扩散、坍塌、崩溃了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号