Hive数据压缩与存储格式
一、Hive的数据压缩
(一) 数据压缩的优缺点
优点:
- 减少存储磁盘空间,降低单节点的磁盘IO。
- 减少网络传输带宽 ,因此可以加快数据在Hadoop集群流动的速度。
缺点:
需要花费额外的时间/CPU做压缩和解压缩计算。
(二)MR支持的压缩编码
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 否 |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | .snappy | 否 |
Hadoop引入了编码/解码器
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
(三) 压缩配置参数
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 说明 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
(四) 几种压缩方式的优缺点及应用场景
1. Gzip
- 优点: 压缩率比较高,压缩/解压速度也比较快,hadoop本身支持。
- 缺点: 不支持分片。
- 应用场景:当每个文件压缩之后在1个block块大小内, 可以考虑用gzip压缩格式。
2. Bzip2
-
优点: 支持分片,具有很高的压缩率,比gzip压缩率都高,Hadoop本身支持。
-
缺点: 压缩/解压速度慢,不支持Hadoop native库。
-
应用场景: 可以作为mapreduce作业的输出格式,输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘
空间并且以后数据用得比较少的情况。
3. LZO
- 优点: 压缩/解压速度也比较快,合理的压缩率,支持分片,是Hadoop中最流行的压缩格式,支持Hadoop native库。 可以在linux系统下安装lzop命令,使用方便。
- 缺点: 压缩率比gzip要低一些,Hadoop本身不支持,需要安装,如果支持分片需要建立索引,还需要指定inputformat改为lzo格式。
- 应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显。
4. Snappy
- 优点: 支持Hadoop native库,高速压缩速度和合理的压缩率。
- 缺点: 不支持分片,压缩率比gzip要低,Hadoop本身不支持,需要安装。
- 应用场景:当MapReduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式。
5. 总结
- 压缩比: bzip2 > gzip > lzo > snappy
- 压缩和解压缩速度,与压缩比成反比: snappy > lzo> gzip > bzip2
- BZip2,LZO提供了块(BLOCK)级别的压缩,支持split切分;而snappy,gzip将文件中记录的边界信息掩盖掉了,因此不支持split切分。
(五) 开启Map输出阶段压缩
- 开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4)执行查询语句
select count(1) from score;
(六) 开启Reduce输出阶段压缩
- 当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性 hive.exec.compress.output 控制着这个功能。
- 用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。
- 用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例实操:
1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3)设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4)设置mapreduce最终数据输出压缩为块压缩
hive(default)>set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/export/servers/snappy' select * from score distribute by s_id sort by s_id desc;
二、Hive的数据存储格式
(一) Hive可概括为六种存储格式
- TEXTFILE
- SEQUENCEFILE
- AVRO FILE
- PARQUET
- RCFILE
- ORCFILE
在其中textfile为默认格式,如果在创建hive表不提及,会默认启动textfile格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;与此同时,sequencefile,rcfile,orcfile自己不能直接从本地导入数据,需要将数据转为textfile格式,才能导入三种不同的格式。
(二) 简单介绍其特点
1. TEXTFILE
-
理论
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
-
存储方式:行存储
-
实例测试
create table if not exists textfile_table
(
ueserid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited fields terminated by '\t'
stored as textfile;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from textfile_table;
2. SEQUENCEFILE
-
理论
二进制文件,以<key,value>的形式序列化到文件中;
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点;
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK;
Record压缩率低,一般建议使用BLOCK压缩;
-
存储方式:行存储
-
实例测试
create table if not exists seqfile_table
(
ueserid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited
fields terminated by '\t'
stored as sequencefile;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table seqfile_table select * from textfile_table;
3. AVRO FILE
-
理论
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
-
存储方式:Avro依赖模式(Schema)来实现数据结构定义。可以把模式理解为Java的类,它定义每个实例的结构,可以包含哪些属性。可以根据类来产生任意多个实例对象
-
实例测试
-- 方式一:高版本可以直接 STORED AS avro
-- 高版本的hive,可以直接使用avro格式存储,而不需要手动指定avro的schema文件,hive自己会根据table的创建方式自行解析并将schema存储到文件的头部。
CREATE TABLE if not exists `test_avro`(
`id` STRING,
`desc` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS avro;
-- 方式二:低版本|高版本 hive
-- 1)在创建表的时候,指定schema文件,表的属性为空。(Use avro.schema.url)
-- avro.schema.url可以 url 。
-- avro.schema.url也可以指向hdfs地址。
CREATE TABLE kst
PARTITIONED BY (ds string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES ('avro.schema.url'='http://schema_provider/kst.avsc');
/**
kst.avsc 内容
{
"namespace": "com.linkedin.haivvreo",
"name": "test_serializer",
"type": "record",
"fields": [
{ "name":"string1", "type":"string" },
{ "name":"int1", "type":"int" },
{ "name":"tinyint1", "type":"int" },
{ "name":"smallint1", "type":"int" },
{ "name":"bigint1", "type":"long" },
{ "name":"boolean1", "type":"boolean" },
{ "name":"float1", "type":"float" },
{ "name":"double1", "type":"double" },
{ "name":"list1", "type":{"type":"array", "items":"string"} },
{ "name":"map1", "type":{"type":"map", "values":"int"} },
{ "name":"struct1", "type":{"type":"record", "name":"struct1_name", "fields": [
{ "name":"sInt", "type":"int" }, { "name":"sBoolean", "type":"boolean" }, { "name":"sString", "type":"string" } ] } },
{ "name":"union1", "type":["float", "boolean", "string"] },
{ "name":"enum1", "type":{"type":"enum", "name":"enum1_values", "symbols":["BLUE","RED", "GREEN"]} },
{ "name":"nullableint", "type":["int", "null"] },
{ "name":"bytes1", "type":"bytes" },
{ "name":"fixed1", "type":{"type":"fixed", "name":"threebytes", "size":3} }
] }
*/
-- 方式三:低版本|高版本 hive
-- 2) schema直接写在table语句中
CREATE EXTERNAL TABLE tweets
COMMENT "A table backed by Avro data with the
Avro schema embedded in the CREATE TABLE statement"
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/wyp/examples/input/'
TBLPROPERTIES (
'avro.schema.literal'='{
"type": "record",
"name": "Tweet",
"namespace": "com.miguno.avro",
"fields": [
{ "name":"username", "type":"string"},
{ "name":"tweet", "type":"string"},
{ "name":"timestamp", "type":"long"}
]
}'
);
4. PARQUET
-
理论
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
-
在HDFS文件系统和Parquet文件中存在如下几个概念
HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的,例如记录占用空间比较小的Schema可以在每一个行组中存储更多的行。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照*Block**大小设置行组的大小*,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。
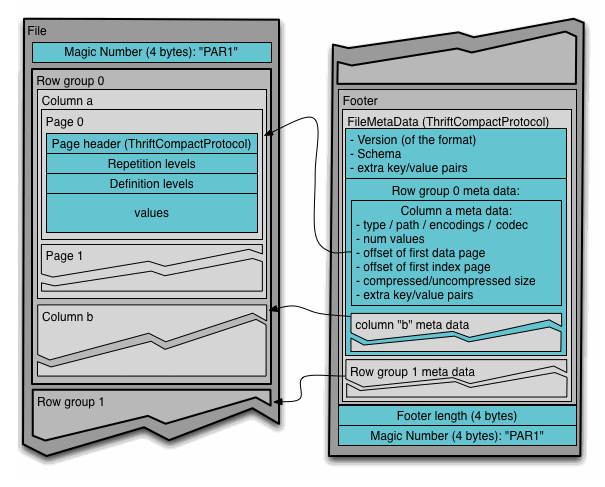
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。
在执行MR任务的时候可能存在多个Mapper任务的输入是同一个Parquet文件的情况,每一个Mapper通过InputSplit标示处理的文件范围,如果多个InputSplit跨越了一个Row Group,Parquet能够保证一个Row Group只会被一个Mapper任务处理。
-
存储方式:列式存储
-
实例测试
create table if not exists parquet_table(
`column1` string,
`column2` string,
`column3` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS parquet
TBLPROPERTIES ('parquet.compress'='snappy');
set hive.exec.compress.intermediate=true;
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;
insert overwrite table parquet_table select * from textfile_table;
5. RCFILE
-
理论
RCFILE 行列混合存储方式:RCFILE可以进行行列混合压缩,将附近的列和行的数据尽量保存到相同的块里面,该存储格式会提高查询效率,但是写数据较慢。该方式和gzcodeC压缩属性结合不是很好,(ORCFILE与这个效果一样只是,他的效率比 RCFILE 高很多)
RCFile文件格式是FaceBook开源的一种Hive的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念。

首先对表进行行划分,分成多个行组。一个行组主要包括:16字节的HDFS同步块信息,主要是为了区分一个HDFS块上的相邻行组;元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;数据部分我们可以看出RCFile将每一行,存储为一列,将一列存储为一行,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就以。
在一般的行存储中 select a from table,虽然只是取出一个字段的值,但是还是会遍历整个表,所以效果和select * from table 一样,在RCFile中,像前面说的情况,只会读取该行组的一行。
在一般的列存储中,会将不同的列分开存储,这样在查询的时候会跳过某些列,但是有时候存在一个表的有些列不在同一个HDFS块上(如下图),所以在查询的时候,Hive重组列的过程会浪费很多IO开销。而RCFile由于相同的列都是在一个HDFS块上,所以相对列存储而言会节省很多资源
- 在存储空间上
行划分 列存储,RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。

- 懒加载:
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
select c from table where a>1
针对行组来说,会对一个行组的a列进行解压缩,如果当前列中有a>1的值,然后才去解压缩c。若当前行组中不存在a>1的列,那就不用解压缩c,从而跳过整个行组。
-
存储方式:数据按行分块 每块按照列存储
-
应用场景
在OLAP应用场景中,如果指定的表有成百上千个字段,而大多数的查询只需要使用到其中的一小部分字段,这时候,如果使用行式存储,那么这是扫描所有的行,而过滤掉大部分的字段显示是个浪费,因此 RCFILE 这种列式存储就显示出了优势,列式存储只扫描需要用到的列,减少了不必要的消耗。
实例测试
create table if not exists rcfile_table
(
ueserid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited fields terminated by '\t'
stored as rcfile;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from textfile_table;
6. ORCFILE
-
理论
ORC是在一定程度上扩展了RCFile,是对RCFile的优化。
ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。
文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
提供了多种索引,row group index、bloom filter index。
ORC可以支持复杂的数据结构(比如Map等)

- **存储结构上 **
stripe划分 列存储,根据结构图,我们可以看到ORCFile在RCFile基础上引申出来Stripe和Footer等。每个ORC文件首先会被横向切分成多个Stripe,而每个Stripe内部以列存储,所有的列存储在一个文件中,而且每个stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效。
Postscripts 中存储该表的行数,压缩参数,压缩大小,列等信息
Stripe Footer 中包含该stripe的统计结果,包括Max,Min,count等信息
File Footer 中包含该表的统计结果,以及各个Stripe的位置信息
Index Data 中保存了该stripe上数据的位置信息,总行数等信息
Row Data 以stream的形式保存了数据的具体信息
Hive读取数据的时候,根据FileFooter读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据。
网友有一幅图,形象的说明了这个问题:

ORCFile扩展了RCFile的压缩,除了Run-length(游程编码),引入了字典编码和Bit编码。
采用字典编码,最后存储的数据便是字典中的值,每个字典值得长度以及字段在字典中的位置
至于Bit编码,对所有字段都可采用Bit编码来判断该列是否为null,
如果为null则Bit值存为0,否则存为1,对于为null的字段在实际编码的时候不需要存储,也就是说字段若为null,是不占用存储空间的。
所有关于ORCFile的参数都是在Hive QL语句的TBLPROPERTIES字段里面出现,他们是:
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268435456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
- 存储方式:数据按行分块 每块按照列存储
- 实例测试
create table if not exists orcfile_table
(
ueserid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited fields terminated by '\t'
stored as orcfile;
set hive.default.fileformat=orc
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table orcfile_table select * from textfile_table;
本文作者:柒小韩
本文链接:https://www.cnblogs.com/yzyang/p/15137852.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步