2.线性表
一、什么是线性表
线性表是最简单、最基本、最常用的数据结构。线性表是线性结构的抽象(Abstract),线性结构的特点是结构中的数据元素之间存在一对一的线性关系。这种一对一的关系指的是数据元素之间的位置关系,即:( 1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素;( 2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素。也就是说,数据元素是一个接一个的排列。因此,可以把线性表想象为一种数据元素序列的数据结构。
线性表就是位置有先后关系,一个接着一个排列的数据结构。
二、CLR中的线性表
c# 1.1 提供了一个非泛型接口IList接口,接口中的项是object,实现了IList解扣子的类有ArrayList,ListDictionary,StringCollection,StringDictionary.
c# 2.0 提供了泛型的IList<T>接口,实现了List<T>接口的类有List<T>
三、线性表的接口定义
public interface IListDS<T> { int GetLength(); //求长度 void Clear(); //清空操作 bool IsEmpty(); //判断线性表是否为空 void Add(T item); //附加操作 void Insert(T item, int i); //插入操作 T Delete(int i); //删除操作 T GetElem(int i); //取表元 T this[int index]{get;}//定义一个索引器 获取元素 int Locate(T value); //按值查找 }
四、线性表的实现方式
线性表的实现方式有下面几种:
顺序表
单链表
双向链表
循环链表
五、顺序表
在计算机内,保存线性表最简单、最自然的方式,就是把表中的元素一个接一个地放进顺序的存储单元,这就是线性表的顺序存储(Sequence Storage)。线性表的顺序存储是指在内存中用一块地址连续的空间依次存放线性表的数据元素,用这种方式存储的线性表叫顺序表(Sequence List),如图所示。顺序表的特点是表中相邻的数据元素在内存中存储位置也相邻。

六、顺序表的存储
假设顺序表中的每个数据元素占w个存储单元,设第i个数据元素的存储地址为Loc(ai),则有:
Loc(ai)= Loc(a1)+(i-1)*w 1≤i≤n式中的Loc(a1)表示第一个数据元素a1的存储地址,也是顺序表的起始存储地址,称为顺序表的基地址(Base Address)。也就是说,只要知道顺序表的基地址和每个数据元素所占的存储单元的个数就可以求出顺序表中任何一个数据元素的存储地址。并且,由于计算顺序表中每个数据元素存储地址的时间相同,所以顺序表具有任意存取的特点。(可以在任意位置存取东西)
C#语言中的数组在内存中占用的存储空间就是一组连续的存储区域,因此,数组具有任意存取的特点。所以,数组天生具有表示顺序表的数据存储区域的特性。
七、顺序表的实现
public class SeqList<T> : IListDS<T> { // ... }
八、单链表
顺序表是用地址连续的存储单元顺序存储线性表中的各个数据元素,逻辑上相邻的数据元素在物理位置上也相邻。因此,在顺序表中查找任何一个位置上的数据元素非常方便,这是顺序存储的优点。但是,在对顺序表进行插入和删除时,需要通过移动数据元素来实现,影响了运行效率。线性表的另外一种存储结构——链式存储(Linked Storage),这样的线性表叫链表(Linked List)。链表不要求逻辑上相邻的数据元素在物理存储位置上也相邻,因此,在对链表进行插入和删除时不需要移动数据元素,但同时也失去了顺序表可随机存储的优点。
九、单链表的存储
链表是用一组任意的存储单元来存储线性表中的数据元素(这组存储单元可以是连续的,也可以是不连续的)。那么,怎么表示两个数据元素逻辑上的相邻关系呢?即如何表示数据元素之间的线性关系呢?为此,在存储数据元素时,除了存储数据元素本身的信息外,还要存储与它相邻的数据元素的存储地址信息。这两部分信息组成该数据元素的存储映像(Image),称为结点(Node)。把存储据元素本身信息的域叫结点的数据域(Data Domain),把存储与它相邻的数据元素的存储地址信息的域叫结点的引用域(Reference Domain)。因此,线性表通过每个结点的引用域形成了一根“链条”,这就是“链表”名称的由来。
如果结点的引用域只存储该结点直接后继结点的存储地址,则该链表叫单链表(Singly Linked List)。把该引用域叫 next。单链表结点的结构如图所示,图中 data 表示结点的数据域。
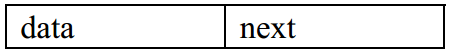
十、链式存储结构
下图是线性表(a1,a2,a3,a4,a5,a6)对应的链式存储结构示意图。
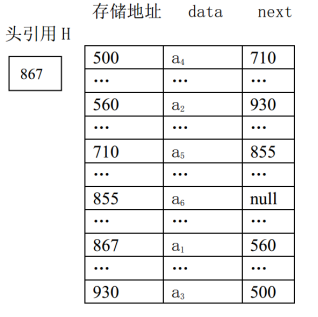
另外一种表示形式

十一、单链表节点定义
1 public class Node<T> 2 { 3 private T data; //数据域 4 private Node<T> next; //引用域 5 //构造器 6 public Node(T val, Node<T> p) 7 { 8 data = val; 9 next = p; 10 } 11 //构造器 12 public Node(Node<T> p) 13 { 14 next = p; 15 } 16 //构造器 17 public Node(T val) 18 { 19 data = val; 20 next = null; 21 } 22 //构造器 23 public Node() 24 { 25 data = default(T); 26 next = null; 27 } 28 //数据域属性 29 public T Data 30 { 31 get 32 { 33 return data; 34 } 35 set 36 { 37 data = value; 38 } 39 } 40 //引用域属性 41 public Node<T> Next 42 { 43 get 44 { 45 return next; 46 } 47 set 48 { 49 next = value; 50 } 51 } 52 }
十二、单链表实现
1 using System; 2 3 public class LinkList<T> : IListDS<T> 4 { 5 private Node<T> head; //单链表的头引用 6 //头引用属性 7 public Node<T> Head 8 { 9 get { return head; } 10 set { head = value; } 11 } 12 13 //构造器 14 public LinkList() 15 { 16 head = null; 17 } 18 19 //求单链表的长度 20 public int GetLength() 21 { 22 Node<T> p = head; 23 int len = 0; 24 while (p != null) 25 { 26 ++len; 27 p = p.Next; 28 } 29 return len; 30 } 31 32 //清空单链表 33 public void Clear() 34 { 35 head = null; 36 } 37 38 //判断单链表是否为空 39 public bool IsEmpty() 40 { 41 if (head == null) 42 { 43 return true; 44 } 45 else 46 { 47 return false; 48 } 49 } 50 51 //在单链表的末尾添加新元素 52 public void Append(T item) 53 { 54 Node<T> q = new Node<T>(item); 55 Node<T> p = new Node<T>(); 56 if (head == null) 57 { 58 head = q; 59 return; 60 } 61 p = head; 62 while (p.Next != null) 63 { 64 p = p.Next; 65 } 66 p.Next = q; 67 } 68 69 //在单链表的第i个结点的位置前插入一个值为item的结点 70 public void Insert(T item, int i) 71 { 72 if (IsEmpty() || i < 1) 73 { 74 Console.WriteLine("List is empty or Position is error!"); 75 return; 76 } 77 if (i == 1) 78 { 79 Node<T> q = new Node<T>(item); 80 q.Next = head; 81 head = q; 82 return; 83 } 84 Node<T> p = head; 85 Node<T> r = new Node<T>(); 86 int j = 1; 87 while (p.Next != null && j < i) 88 { 89 r = p; 90 p = p.Next; 91 ++j; 92 } 93 if (j == i) 94 { 95 Node<T> q = new Node<T>(item); 96 q.Next = p; 97 r.Next = q; 98 } 99 } 100 101 //在单链表的第i个结点的位置后插入一个值为item的结点 102 public void InsertPost(T item, int i) 103 { 104 if (IsEmpty() || i < 1) 105 { 106 Console.WriteLine("List is empty or Position is error!"); 107 return; 108 } 109 if (i == 1) 110 { 111 Node<T> q = new Node<T>(item); 112 q.Next = head.Next; 113 head.Next = q; 114 return; 115 } 116 Node<T> p = head; 117 int j = 1; 118 while (p != null && j < i) 119 { 120 p = p.Next; 121 ++j; 122 } 123 if (j == i) 124 { 125 Node<T> q = new Node<T>(item); 126 q.Next = p.Next; 127 p.Next = q; 128 } 129 } 130 131 //删除单链表的第i个结点 132 public T Delete(int i) 133 { 134 if (IsEmpty() || i < 0) 135 { 136 Console.WriteLine("Link is empty or Position is error!"); 137 return default(T); 138 } 139 Node<T> q = new Node<T>(); 140 141 if (i == 1) 142 { 143 q = head; 144 head = head.Next; 145 return q.Data; 146 } 147 Node<T> p = head; 148 int j = 1; 149 while (p.Next != null && j < i) 150 { 151 ++j; 152 q = p; 153 p = p.Next; 154 } 155 if (j == i) 156 { 157 q.Next = p.Next; 158 return p.Data; 159 } 160 else 161 { 162 Console.WriteLine("The ith node is not exist!"); 163 return default(T); 164 } 165 } 166 167 //获得单链表的第i个数据元素 168 public T GetElem(int i) 169 { 170 if (IsEmpty()) 171 { 172 Console.WriteLine("List is empty!"); 173 return default(T); 174 } 175 Node<T> p = new Node<T>(); 176 p = head; 177 int j = 1; 178 while (p.Next != null && j < i) 179 { 180 ++j; 181 p = p.Next; 182 } 183 if (j == i) 184 { 185 return p.Data; 186 } 187 else 188 { 189 Console.WriteLine("The ith node is not exist!"); 190 return default(T); 191 } 192 } 193 194 //在单链表中查找值为value的结点 195 public int Locate(T value) 196 { 197 if (IsEmpty()) 198 { 199 Console.WriteLine("List is Empty!"); 200 return -1; 201 } 202 Node<T> p = new Node<T>(); 203 p = head; 204 int i = 1; 205 while (!p.Data.Equals(value) && p.Next != null) 206 { 207 P = p.Next; 208 ++i; 209 } 210 return i; 211 } 212 }
十三、双向链表
前面介绍的单链表允许从一个结点直接访问它的后继结点,所以, 找直接后继结点的时间复杂度是 O(1)。但是,要找某个结点的直接前驱结点,只能从表的头引用开始遍历各结点。如果某个结点的 Next 等于该结点,那么,这个结点就是该结点的直接前驱结点。也就是说,找直接前驱结点的时间复杂度是 O(n), n是单链表的长度。当然,我们也可以在结点的引用域中保存直接前驱结点的地址而不是直接后继结点的地址。这样,找直接前驱结点的时间复杂度只有 O(1),但找直接后继结点的时间复杂度是 O(n)。如果希望找直接前驱结点和直接后继结点的时间复杂度都是 O(1),那么,需要在结点中设两个引用域,一个保存直接前驱结点的地址,叫 prev,一个直接后继结点的地址,叫 next,这样的链表就是双向链表(Doubly Linked List)。双向链表的结点结构示意图如图所示。

十四、双向链表节点实现
1 public class DbNode<T> 2 { 3 private T data; //数据域 4 private DbNode<T> prev; //前驱引用域 5 private DbNode<T> next; //后继引用域 6 //构造器 7 public DbNode(T val, DbNode<T> p) 8 { 9 data = val; 10 next = p; 11 } 12 13 //构造器 14 15 public DbNode(DbNode<T> p) 16 { 17 next = p; 18 } 19 20 //构造器 21 public DbNode(T val) 22 { 23 data = val; 24 next = null; 25 } 26 27 //构造器 28 public DbNode() 29 { 30 data = default(T); 31 next = null; 32 } 33 34 //数据域属性 35 public T Data 36 { 37 get { return data; } 38 set { data = value; } 39 } 40 41 //前驱引用域属性 42 public DbNode<T> Prev 43 { 44 get { return prev; } 45 set { prev = value; } 46 } 47 48 //后继引用域属性 49 public DbNode<T> Next 50 { 51 get { return next; } 52 set { next = value; } 53 } 54 }
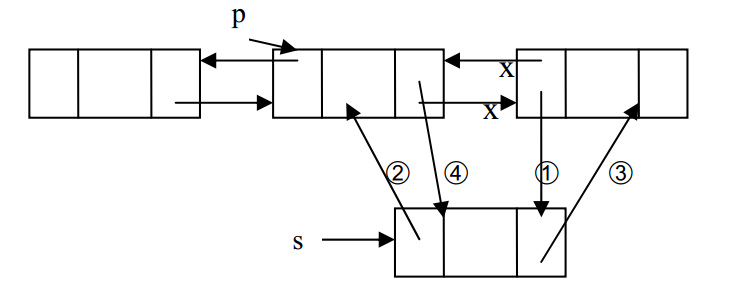
十五、双向链表插入示意图
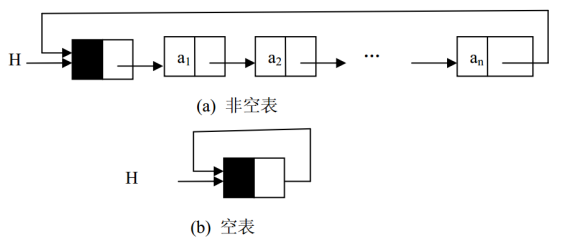
十六、循环链表
有些应用不需要链表中有明显的头尾结点。在这种情况下,可能需要方便地从最后一个结点访问到第一个结点。此时,最后一个结点的引用域不是空引用,而是保存的第一个结点的地址(如果该链表带结点,则保存的是头结点的地址),也就是头引用的值。带头结点的循环链表(Circular Linked List)如图所示。