Linux基础IO(系统调用,文件描述符,重定向)
Linux库函数和系统调用的区别
库函数
库函数可以理解成是对系统调用的一层封装。系统调用作为内核提供给用户程序的接口,系统调用的执行效率高并且精简,但是我们有时候需要对获取的信息进行更加复杂的处理,我们需要把这些过程封装成一个函数供给程序员使用,这就有了库函数的概念。
系统调用
系统调用,是操作系统提供给用户程序调用的一组特殊的接口。从逻辑上来说,系统调用可以看成是内核与用户空间程序交互的接口---就好比一个中间人。把用户进程的请求传达给内核,等内核把请求处理完毕之后将处理的结果返回给用户空间。
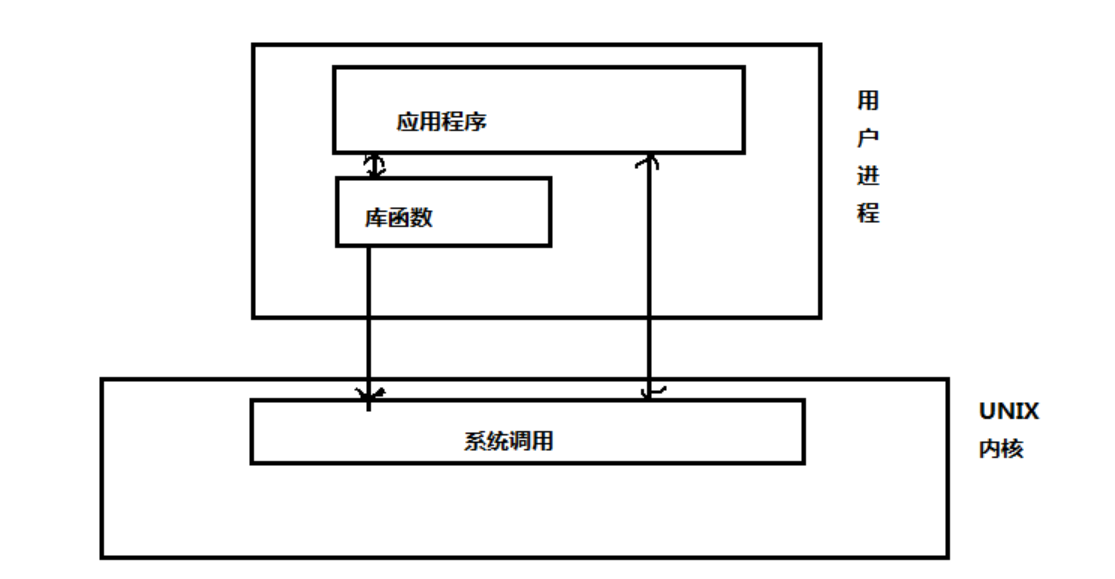
库函数和系统调用的区别
Linux下对文件操作有两种方式:系统调用和库函数调用。
库函数调用由两类函数组成:
(1)不需要调用系统调用:不需要切换到内核空间就可以完成函数的全部功能的函数,并且将结果反馈给应用程序,例如strcpy,bzer函数。
(2)需要调用系统调用:需要切换到内核空间,这类函数通过封装系统调用去实现相应的功能,例如printf,fread等。
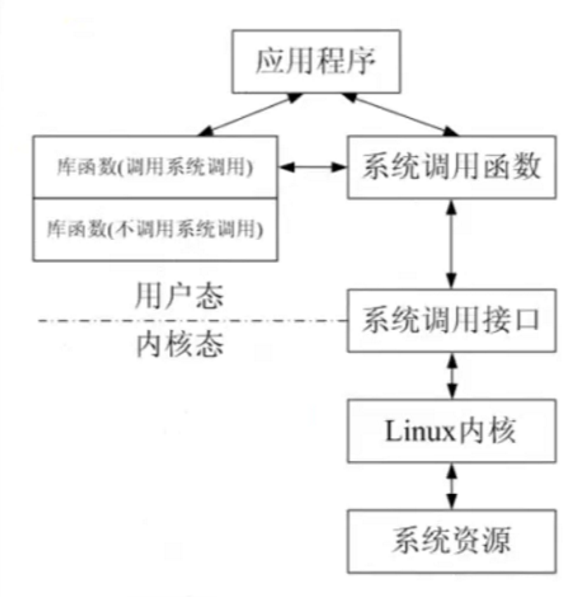
那为什么要有库函数调用和系统调用呢?
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
这样的话,使用库函数也有系统调用的开销,为什么不直接使用系统调用呢?
首先,系统调用是需要时间的,程序中频繁的使用系统调用会降低程序的运行效率。当运行内核代码的时候,CPU工作在内核态,在系统调用发生前需要保存用户态的栈和内存环境,然后转入内核态工作。系统调用结束后,又要切换回用户态,这种环境的切换回消耗掉很多时间。
其次,如果是读写文件通常是需要大量数据处理的,而库函数可以大大减少系统调用的次数,这源于缓冲区技术,对于系统调用来说,来一次数据然后触发系统调用,系统就会处理一次数据,但是库函数引入了缓冲区技术(人为设置缓冲区大小),将内容存储到用户空间缓冲区,等缓冲区满了一次性全部送到内核处理,大大减少了系统调用的次数。
这个过程就类似于快递员给某个区域(内核空间)送快递一样,快递员有两种方式:
(1)来一件快递就马上送到目的地,来一件送一件,这样导致来回走比较频繁(系统调用)。
(2)等快递攒着差不多了之后(缓冲区),才一次性送到目的地(库函数调用)。
stdin & stdout & stderr
Linux下一切皆文件,硬件设备也是被当做文件看待的,也就是说这些硬件设备也是可以通过IO打开的,并且进行读写。那他们是操作的呢?一般来说,C语言程序运行起来,都会默认打开3个流,分别是:
- stdin: 标准输入流(键盘)
- stdout: 标准输出流(显示器)
- stderr: 标准错误流(显示器)
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;
仔细观察可以发现,它们都是FILE*类型的,也就是文件指针。所以,我们不需要考虑要打开键盘和屏幕这些流。这也是为什么我在打印数据到屏幕或从键盘上输入数据时,即使我们没有打开这些流,我们也可以执行这些操作的原因。
文件描述符(fd)
打开现存文件或者新建文件的时候,系统(内核)会返回一个文件描述符,文件描述符用来指定已经打开的文件。这个文件描述符相当于这个已经打开文件的标号,文件描述符是非负整数,是文件的标识,操作这个文件描述符相当于操作这个描述符指向的文件。
注意:
- Linux进程默认情况下会有3个已经打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2。
- 0,1,2对应的物理设备一般是:键盘,显示器,显示器。
- 新创建的文件会从3往后排,因为默认会打开0,1,2这三个文件
#define STDIN_FILENO 0//标准输入的文件描述符
#define STDOUT_FILENO 1//标准输出的文件描述符
#define STDERR_FILENO 2//标准错误的文件描述符
思考1:一个进程可以打开很多文件,那么这些文件是如何管理起来的呢?
答案:先描述,再组织
(1)先描述:操作系统在内存中创建相应的数据结构来描述目标文件。也就是用一个struct file的结构体把每个文件描述起来。对于进程而言,先找到file_struct,然后找到fd_array的指针数组,通过下标fd找到对应的file*,从而找到对应的文件,然后struct file中的函数指针就可以实现对文件的读写操作。

(2)再组织:用一个双链表的结构把打开的文件链接起来,文件的打开和关闭就是对双链表的增删查改。
思考2:进程如何与文件关联起来?
每个进程中都有一个struct file_struct* 的结构体指针,指向的是一个file_struct的结构体,这个结构体里面有一个sturct file* 的指针数组fd_array[],里面指向的就是一个一个的struct file,如下图:
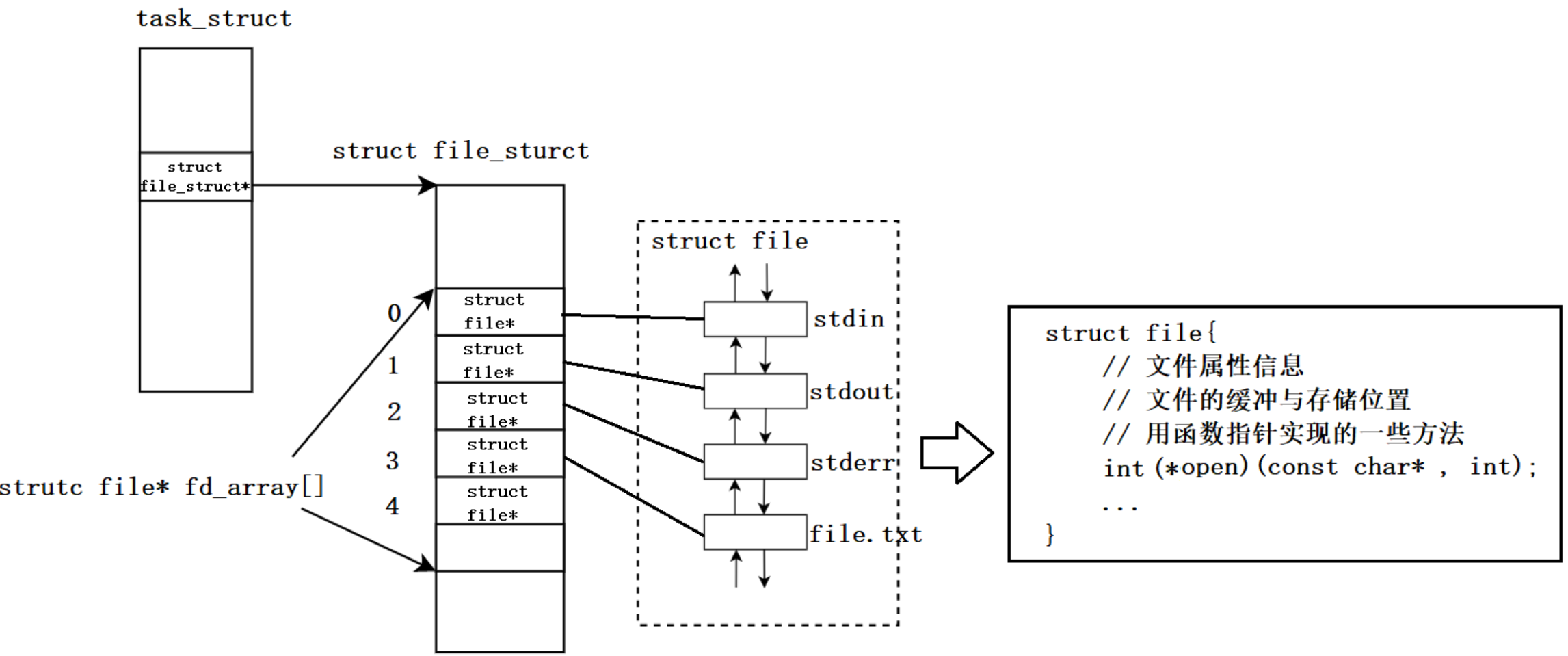
进程如何找到对应文件?(进程和文件关联)
进程的task_struct中可以找到一个叫struct file*的指针,这个指针指向file_struct这张表,这样表里面又有一个指针数组,指向的是每一个文件的结构体,通过fd (数组下标)可以找到对应的struct file,这个结构体里面就包含文件属性和相关的inode元信息,还有对文件进行读写操作的一些方法。这样就达到通过fd找到对应文件的目的。
文件描述符分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
重定向
概念
概念: 重定向是指修改原来默认的一些东西,对原来系统命令的默认执行方式进行改变。
重定向一般有以下几种:
- 输出重定向: >
- 输入重定向: <
- 追加重定向: >>
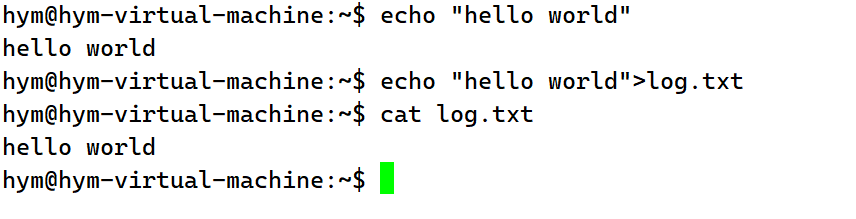
正常使用echo命令,字符串是输出在显示器上的,加了输出重定向后,字符串被输出到文件上了。也就是把本应该打印到显示器上的内容打印到了文件上了。输出重定向改变了默认的输出方式。
原理
输出重定向的原理
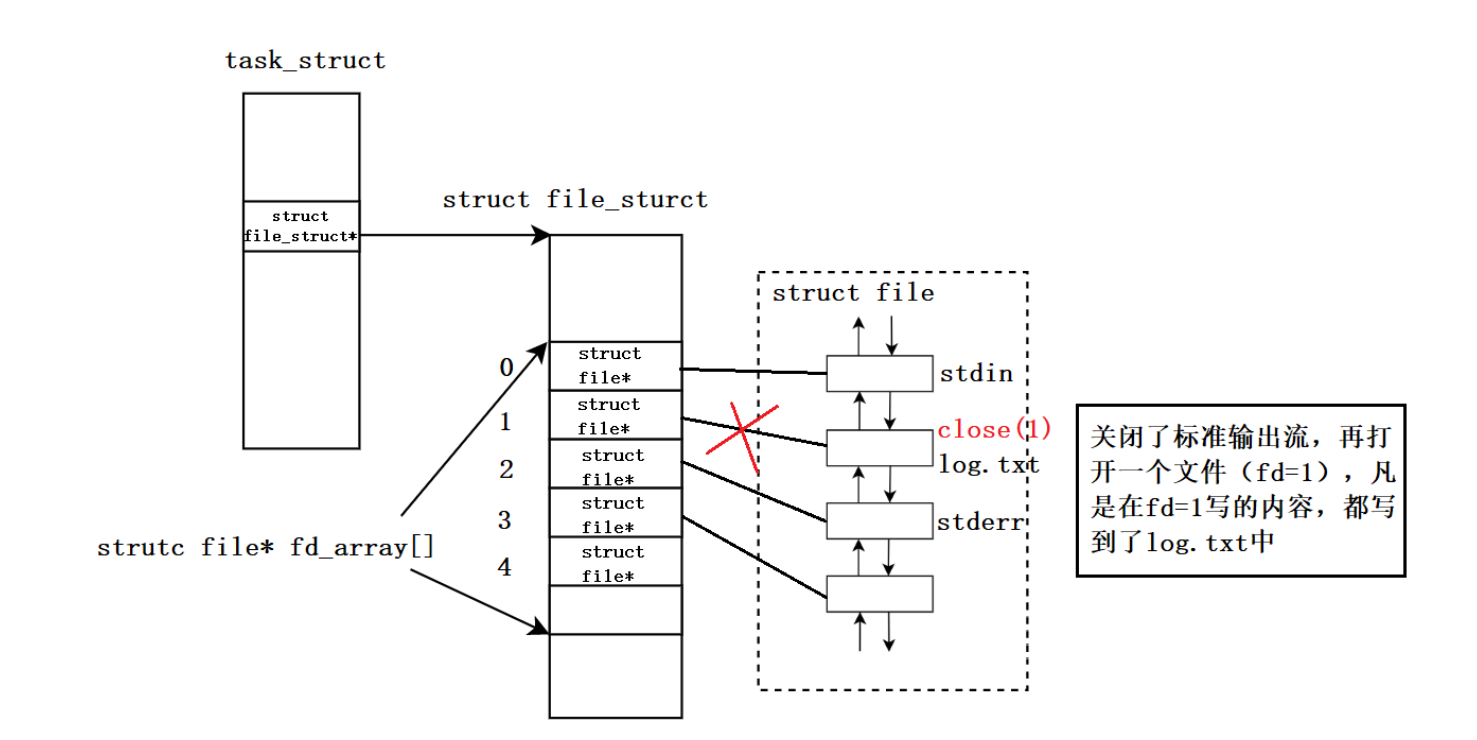
示例:关闭标准输出流,也就是fd为1的文件,此时我们再以写的方式打开一个文件,然后进行输出,观察现象。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d, you can see me...\n", fd);
fflush(stdout);
close(fd);
return 0;
}
可以发现关闭标准输出流后,本应该打印到显示器上的字符串被输出到了log.txt 的文件中。
从上述实验现象分析重定向原理: 关闭了标准输出流,再以写的方式打开一个文件(被分配fd=1),凡是要在fd=1写的内容,现在都写到了log.txt中,如下图:
追加重定向的原理
示例:关闭标准输出流,也就是fd为1的文件,此时我们再以追加(O_APPEND)的方式打开一个文件,然后进行输出,观察现象。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY|O_APPEND|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d, you can see me...\n", fd);
fflush(stdout);
close(fd);
return 0;
}
根据输出重定向的原理,我们也不难介绍这个现象,关闭了标准输出流,我们以追加的方式打开一个文件,这个文件被分配了一个为1的文件描述符。因为printf是库函数,是往fd为1的文件进行输出,所以这里也是直接在log.txt文末进行追加。
输入重定向的原理
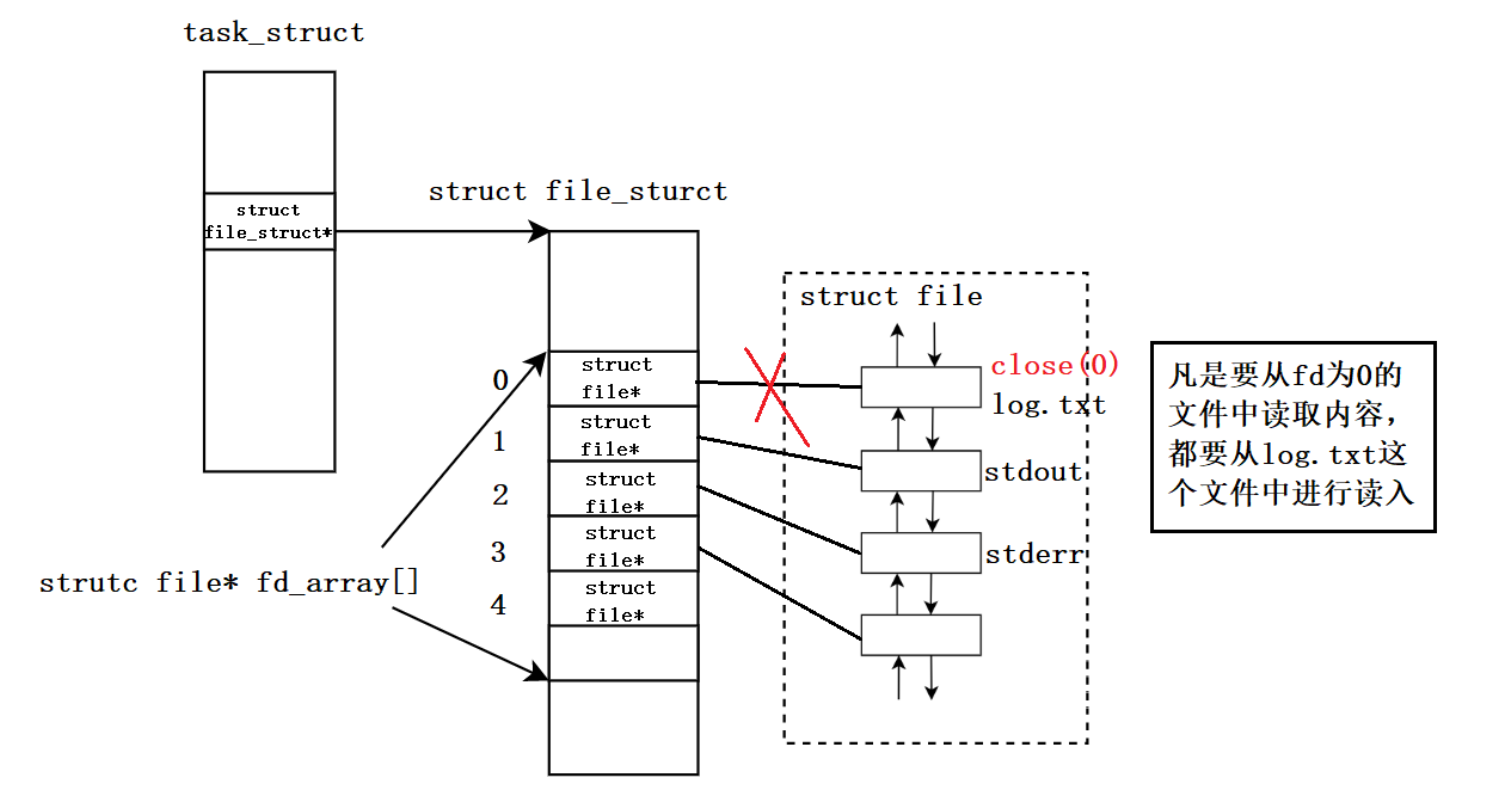
示例:关闭标准输入流,以读的方式打开文件
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(0);
int fd = open("log.txt", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
char buf[256] = {0};
scanf("%s", buf);
printf("%s\n", buf);
close(fd);
return 0;
}
文件描述符复制(dup函数和dup2函数)
概述:dup函数和dup2是两个非常有用的系统调用,都是用来复制一个文件的文件描述符,使得新的文件描述符也能标识旧的文件描述符所标识的文件。
这个过程类似于生活中配钥匙。钥匙相当于文件描述符,锁相当于文件,本来一个钥匙开一把锁,相当于一个文件描述符对应一个文件,现在,我们去配钥匙,通过旧的钥匙复制了一把新的钥匙,新的和旧的钥匙都能打开这把锁,这就相当于新的文件描述符和旧的文件描述符都指向同一个文件。
dup函数
int dup(int oldfd);
功能:通过oldfd复制出一个新的文件描述符,新的文件描述符是调用进程文件描述符中最小可用的文件描述符,最终oldfd和新的文件描述符都指向同一个文件。
参数:oldfd:需要复制的文件描述符oldfd。
返回值:成功:新的最小并且可以用的文件描述符
失败:-1
dup2函数
int dup2(int oldfd,int newfd);
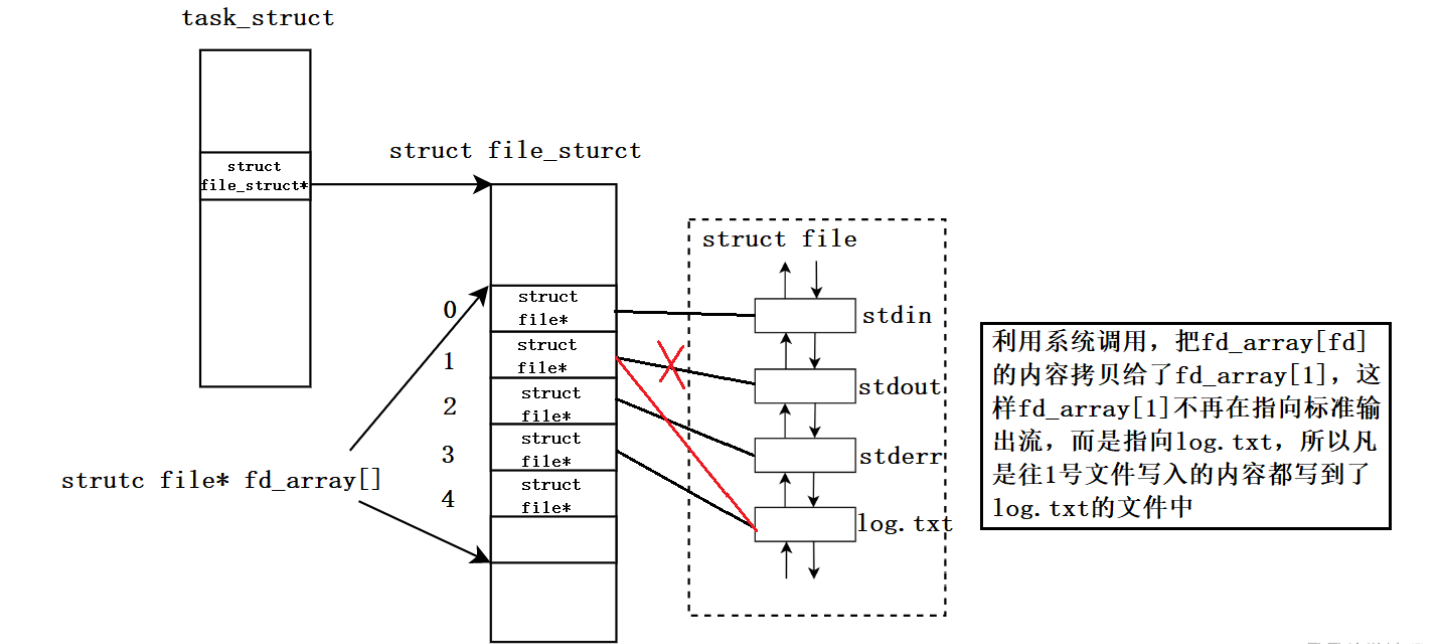
功能: 复制文件描述符给一个新的文件描述符,让fd_array数组中下标为oldfd的内容拷贝给下标为newfd的内容,也就是让newfd的指向发生改变,指向oldfd所指向的文件。
参数:oldfd:要复制的文件的文件描述符
newfd:让文件描述符文newfd的文件称为文件描述符为oldfd的文件的一份拷贝
示例:
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd = open("log.txt", O_CREAT | O_WRONLY);
if (fd < 0) {
perror("open");
return 1;
}
dup2(fd, 1);
printf("fd:%d, you can see me\n", fd);
close(fd);
return 0;
}
运行结果:

dup2原理分析: printf是C库当中的IO函数,一般往 stdout 中输出,但是stdout底层访问文件的时候,找的还是fd:1, 但此时,fd:1下标所表示内容,已经变成了log.txt的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步