


小记--------hadoop的yarn资源管理器原理剖析
首先,yarn在hadoop2.x之后才诞生的,主要作用是为了对计算框架进行总体资源管理调度的
yarn启动命令: ./start-yarn
启动之后,通过jps查看进程 会有两个进程:
1.ResourceManager 以下简称RM
2.NodeManager 以下简称NM
2.RM的组成部分
1.Application Manager (应用程序管理器)
以下简称为 AM
AM 主要负责接收client 端传输的job请求, 为应用(MapReduce)分配第一个Container(资源池 )来运行我们第一个Application Master ,就是负责监控Application Master,并且在遇到失败的时候重启Application Master
(Resource Manager国家领导人、Application Manager 省长、 Application Master 市长)
2.Resource Scheduler (调度器)
就是为了让我们的每一个节点都充分利用起来,不会产生某一个节点一直工作,而其他节点在空闲!!合理的分配和调度的一种管理器!
注意的是: 调度器只是一个纯调度器,它不负责从事任何具体的和应用程序的相关工作!
比如:运行map任务、reduce 任务、监控程序、跟踪程序 都不是他的活。
三种调度方式
FIFO scheduler(先来先服务、队列调度):按照优先级高低调度,如果优先级相同,则按照提交时间先后顺序调度,如果提交时间相同,则按照(队列或者应用程序)名称大小(字符串比较)调度;不支持子队列的情况
FAIR scheduler(公平调度):按照内存资源使用量比率调度,即按照used_memory、minShare大小调度(核心思想是按照该调度算法决定调度顺序)
举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享
Capacity scheduler(容器调度器):允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供了服务。
除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源,在一个队列内部,资源的调度采用的是(FIFO)策略
3.Application Master
当我们正常提交一个MapReduce任务的时候,比如: hadoop jar xxx.jar 命令,我们在后台jps查看下进程的时候,会多了一个MRAppMaster的进程(它就是ApplicationMaster)
首先ApplicationMaster 其实就是一个java程序,只不过他的类名叫:MRAppMaster
所进程名就叫做 MRAppMaster
ApplicationMaster 负责监控MAP任务和reduce任务,用户提交的每一个陈旭都会产生一个AM,这个Am就是负责整个任务的一个管理者

Application Master主要功能:
1.与RM调度器(scheduler)写上获取资源
2.与NM通信, 以启动任务(map、reduce)、停止任务。 设计到一个资源池(container)
3.监控所有旗下的任务的执行状态(map、reduce),如果失败了则会重新启动任务申请资源
4.Container
container是yarn中的资源抽象,它封装了节点的多维度资源:如内存、CPU、磁盘、网络、IO 。 相当于一个小电脑
资源池主要是将节点的资源切分出来组成一个可以单独运行任务的资源(map、reduce)
其中每一个Application Master会对应一个资源池
每一个Map 会对应一个资源池
每一个Reduce 会对应一个资源池
程序运行在yarn上流程图
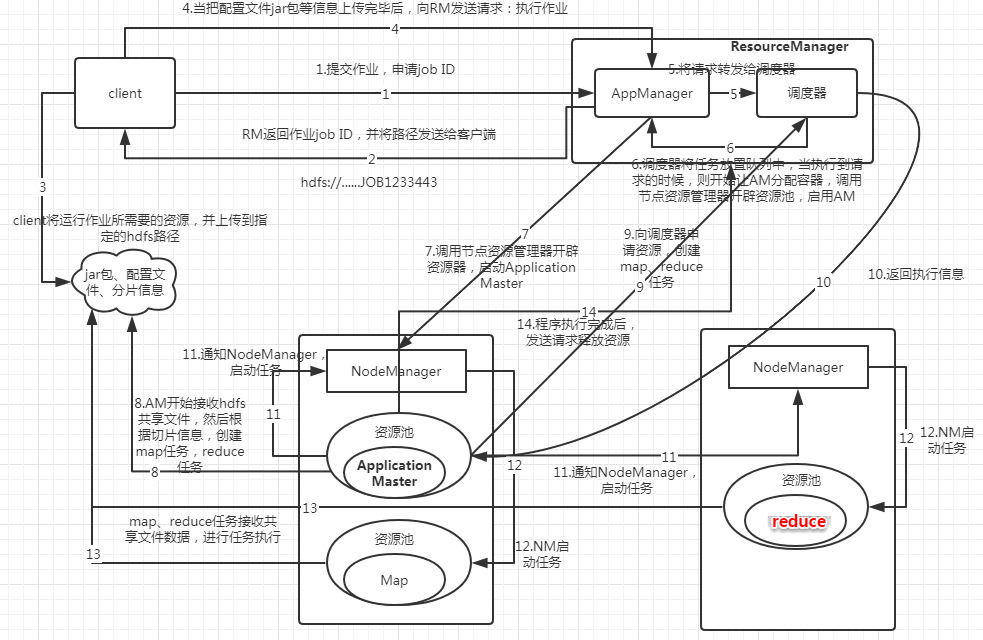
作者:于二黑
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

