
Celery的任务分发与定时任务
celery应用场景
-
celery,处理任务的Python的模块。
-
场景1:
对【耗时的任务】,通过celery,将任务添加到broker(队列),然后立即给用户返回一个任务ID。 当任务添加到broker之后,由worker去broker获取任务并处理任务。 任务完完成之后,再将结果放到backend中 用户想要检查结果,提供任务ID,我们就可以去backend中去帮他查找。 -
场景2:
定时任务(定时发布/定时拍卖)
-
celery的使用
Celery是由Python开发的一个简单、灵活、可靠的处理大量任务的分发系统,它不仅支持实时处理,也支持任务调度。
支持多个broker和worker来实现高可用和分布式。
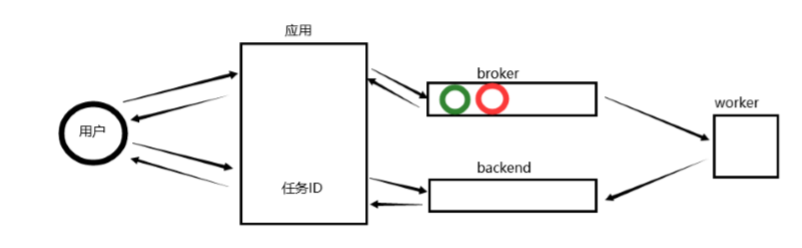
将一些耗时的任务 扔到broker队列中,并且会返回一个任务ID,可以通过任务ID去backend队列中获取结果。 worker从broker获取任务去执行,并将结果返回到backend队列中。
函数名、参数 传入broker
1.1 环境的搭建
pip3 install celery==4.4
安装broker: redis或rabbitMQ
pip3 install redis / pika
1.2 快速使用
-
s1.py
from celery import Celery app = Celery('tasks', broker='redis://192.168.10.48:6379', backend='redis://192.168.10.48:6379') @app.task # 说明这个函数可以被当作celery的任务 def x1(x, y): return x + y @app.task def x2(x, y): return x - y -
s2.py
from s1 import x1 # 立即告诉celery去创建并执行x1任务,并传两个参数 result = x1.delay(4, 4) print(result.id) # 任务ID -
s3.py 获取任务结果
from celery.result import AsyncResult from s1 import app result_object = AsyncResult(id="任务ID", app=app) print(result_object.status) # 任务状态 data = result_object.get() # 获取任务结果 print(data)
任务超时限制
避免某些任务一直处于非正常的进行中状态,阻塞队列中的其他任务。应该为任务执行设置超时时间。如果任务超时未完成,则会将 Worker 杀死,并启动新的 Worker 来替代。
@app.task(time_limit=1800) # 可以设置任务超时限制
运行程序:
-
启动redis
-
启动worker
# 首先要进入当前目录 celery worker -A s1 -l info # -A s1 找到项目 # -l info 是打印日志log,代码上线时不加infowindows下会报一个错: Traceback (most recent call last): File "d:\wupeiqi\py_virtual_envs\auction\lib\site-packages\billiard\pool.py", line 362, in workloop result = (True, prepare_result(fun(*args, **kwargs))) File "d:\wupeiqi\py_virtual_envs\auction\lib\site-packages\celery\app\trace.py", line 546, in _fast_trace_task tasks, accept, hostname = _loc ValueError: not enough values to unpack (expected 3, got 0) 解决安装: pip install eventlet celery worker -A s1 -l info -P eventlet -
创建任务,放入broker
python s2.py python s2.py -
查看任务状态
# 在s3.py填写任务ID ptyhon s3.py取消任务
from s1 import app from celery.app.control import Control celery_control = Control(app=app) celery_control.revoke(id, terminate=True)
1.3 django中应用celery
在Django中用Django-celery。
# pip3 install django-celery (没有用到,还是用的celery模块)
之后,需要按照django-celery的要求进行编写代码。
-
第一步:【项目/项目/settings.py 】添加配置
CELERY_BROKER_URL = 'redis://192.168.16.85:6379' CELERY_ACCEPT_CONTENT = ['json'] CELERY_RESULT_BACKEND = 'redis://192.168.16.85:6379' CELERY_TASK_SERIALIZER = 'json' # CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间Celery 配置参数汇总
配置项 说明 CELERY_DEFAULT_QUEUE 默认队列 CELERY_BROKER_URL Broker 地址 CELERY_RESULT_BACKEND 结果存储地址 CELERY_TASK_SERIALIZER 任务序列化方式 CELERY_RESULT_SERIALIZER 任务执行结果序列化方式 CELERY_TASK_RESULT_EXPIRES 任务过期时间 CELERY_ACCEPT_CONTENT 指定任务接受的内容类型(序列化) -
第二步:【项目/项目/celery.py】在项目同名目录创建 celery.py
#!/usr/bin/env python # -*- coding:utf-8 -*- import os from celery import Celery # set the default Django settings module for the 'celery' program. # celery指定的配置文件 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'demos.settings') app = Celery('demos') # 名字随便起,省略了broker配置,配置文件已配置 # Using a string here means the worker doesn't have to serialize # the configuration object to child processes. # - namespace='CELERY' means all celery-related configuration keys # should have a `CELERY_` prefix. # 所有的celery配置都以CELERY开头 app.config_from_object('django.conf:settings', namespace='CELERY') # Load task modules from all registered Django app configs. # 去每个已注册app中读取 tasks.py 文件 app.autodiscover_tasks() -
第三步,【项目/app名称/tasks.py】
from celery import shared_task @shared_task def add(x, y): return x + y @shared_task def mul(x, y): return x * y -
第四步,【项目/项目/
__init__.py】from .celery import app as celery_app __all__ = ('celery_app',) -
启动worker
# 首先进入项目目录 celery worker -A demos -l info -P eventlet -
编写视图函数,调用celery去创建任务。
-
url
# from api.views import task url(r'^create/task/$', task.create_task), url(r'^get/result/$', task.get_result), -
视图函数
from django.shortcuts import HttpResponse from api.tasks import x1 from celery.result import AsyncResult # from demos.celery import app from demos import celery_app def create_task(request): print('请求来了') result = x1.delay(2,2) # 添加x1任务,并返回任务ID print('执行完毕') return HttpResponse(result.id) def get_result(request): nid = request.GET.get('nid') result_object = AsyncResult(id=nid, app=celery_app) # print(result_object.status) data = result_object.get() # 获取数据 return HttpResponse(data)
-
-
启动django程序
python manage.py ....
1.4 celery定时执行
from app01 import tasks
from celery.result import AsyncResult
def time_task(request):
"""
定时执行
:param request:
:return:
"""
# 获取本地时间
ctime = datetime.datetime.now()
# 转换成utc时间
utc_ctime = datetime.datetime.utcfromtimestamp(ctime.timestamp())
s10 = datetime.timedelta(seconds=60) # 60s后执行
ctime_x = utc_ctime + s10 # 执行的时间
# 使用apply_async并设定时间
result = tasks.mul.apply_async(args=[2, 5], eta=ctime_x)
return HttpResponse(result.id)
def time_result(request):
nid = request.GET.get('nid')
from celery.result import AsyncResult
# from demos.celery import app
from celerytest import celery_app
result_object = AsyncResult(id=nid, app=celery_app)
# print(result_object.status) # 获取状态
# data = result_object.get() # 获取数据
# result_object.forget() # 把数据在backend中移除
# result_object.revoke(terminate=True) # 取消任务terminate=True强制取消
# 通过状态绝对返回方式
if result_object.successful():
# 成功
data = result_object.get()
result_object.forget()
elif result_object.failed():
# 失败
data = '执行失败!'
else:
data = '执行中!'
return HttpResponse(data)
支持的参数 :
-
countdown : 等待一段时间再执行.
tasks.add.apply_async((2,3), countdown=5) -
eta : 定义任务的开始时间.
tasks.add.apply_async((2,3), eta=now+tiedelta(second=10)) -
expires : 设置超时时间.
tasks.add.apply_async((2,3), expires=60) -
retry : 定时如果任务失败后, 是否重试.
tasks.add.apply_async((2,3), retry=False) -
retry_policy : 重试策略.
- max_retries : 最大重试次数, 默认为 3 次.
- interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
- interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
- interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .
1.5 周期性定时任务
- celery
- django中也可以结合使用
task与shared_task装饰器的区别:
task是通过创建的Celery对象进行调用
例如:
app1 = Celery('tasks', broker='redis://192.168.16.48:6379',)
app2 = Celery('tasks', broker='redis://192.168.16.48:6379',)
@app1.task
def x1(x, y):
return x - y
@app2.task
def x2(x, y):
return x * y
多用于单一文件中,不用直接加载到内存。当有多个Celery对象时,任务函数可以明确使用某一个来装饰。
shared_task多用与多个文件使用celery,一般在celery.py中只创建一个Celery对象,例如Django集成celery。在项目启动时,会将celery对象加载到内存,而@shared_task会自动将写在各个应用下task.py的任务交与内存中的Celery对象,复用性较强。
例如:
@shared_task
def x1(x, y):
return x - y
from web import tasks
tasks.x1.delay(1,5)
但当在celery.py中创建多个Celery对象时,不同任务使用不同的对象,这个时候就需要指明对象名。
例如:
from web import tasks
app1.tasks.x1.delay(1,5)
app2.tasks.x2.delay(1,5)
1.6 任务绑定,记录日志,重试
# 修改 tasks.py 文件.
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__)
@app.task(bind=True)
def div(self, x, y):
logger.info(('Executing task id {0.id}, args: {0.args!r}'
'kwargs: {0.kwargs!r}').format(self.request))
try:
result = x/y
except ZeroDivisionError as e:
raise self.retry(exc=e, countdown=5, max_retries=3) # 发生 ZeroDivisionError 错误时, 每 5s 重试一次, 最多重试 3 次.
return result
当使用 bind=True 参数之后, 函数的参数发生变化, 多出了参数 self, 这这相当于把 div 编程了一个已绑定的方法, 通过 self 可以获得任务的上下文.
1.7 启用任务监控
Flower 是 Celery 官方推荐的实时监控工具,用于监控 Tasks 和 Workers 的运行状态。Flower 提供了下列功能:
- 查看 Task 清单、历史记录、参数、开始时间、执行状态等
- 撤销、终止任务
- 查看 Worker 清单、状态
- 远程开启、关闭、重启 Worker 进程
- 提供 HTTP API,方便集成到运维系统
相比查看日志,Flower 的 Web 界面会显得更加友好。
Flower 的 supervisor 管理配置文件:
[program:flower]
command=/opt/PyProjects/venv/bin/flower -A celery_worker:celery --broker="redis://localhost:6379/2" --address=0.0.0.0 --port=5555
directory=/opt/PyProjects/app
autostart=true
autorestart=true
startretries=3
user=derby
stdout_logfile=/var/logs/%(program_name)s.log
stdout_logfile_maxbytes=50MB
stdout_logfile_backups=30
stderr_logfile=/var/logs/%(program_name)s-error.log
stderr_logfile_maxbytes=50MB
stderr_logfile_backups=3
celery面试总结
1. Celery是一个由python开发的一个简单、灵活、可靠的,能够处理大量任务的系统,可以做任务的分发,也能够做定时任务。多用于耗时的操作。例如发送短信、邮箱这些功能就能使用Celery做任务分发。
2. @shared_task/@task装饰的函数说明是这一个celery任务,会添加broker中。
3. 函数名.delay(参数),会去调用且执行任务,并且返回任务ID。
4. 可以根据任务ID,去backend获取任务状态、结果。AsyncResult(id=任务ID, app=celery_app).get()获取任务的结果;
5. apply_async(args=[参数],eta)设置定时执行任务,eta是定时任务的执行时间(utc时间)。
6. revoke()可以取消任务。

