
第四周:卷积神经网络 part 3
第四周:卷积神经网络 part 3
视频学习
语义分割中的自注意力机制和低秩重建
- 语义分割(Semantic Segmentation)
- 概念:语义分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此语义分割是从像素级别来理解图像的。
- 思路:
- 传统方法:
- TextonForest和基于随机森林分类器等语义分割方法
- 深度学习方法:
- Patch classification
- 全卷积方法(FCN)
- encoder-decoder架构
- 空洞卷积(Dilated/Atrous)
- 条件随机场
- 传统方法:
- 几种架构:
ps:空洞卷积、池化目的都是增大感受野。
- 自注意力机制(Self-attention Mechanism)
- 是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
背景:
语义分割是计算机视觉几大主任务之一,被广泛应用到自动驾驶、遥感监测等领域中。语义分割研究中的若干成果,也被诸多相关领域沿用。自注意力机制继在 NLP 领域取得主导地位之后,近两年在计算机视觉领域也开始独领风骚。自注意力机制在语义分割网络中的应用,并由之衍生出的一系列低秩重建相关的方法。
图像语义分割前沿进展
既需要细节,又需要捕捉全局信息。
-
得到大尺度信息方法
- 1.Non-local modules(非局部模块)
- 2.self-attention(自注意力)
- 3.Dilated convolution(空洞卷积)
- 4.Pyramid/global pooling(金字塔/全局池化)
-
缺陷
- 1、2计算资源消耗多
- 3、4虽相对低代价,但各向同性,很难获得各向异性
提高CNNs中远程依赖关系建模能力的一种方法是采用self-attention机制或non-local模块。然而,它们会消耗大量内存。而其他的远程上下文建模方法包括:
1)扩张卷积,其目的是在不引入额外参数的情况下扩大CNNs的接受域;
2)全局/金字塔池化,它总结了图像的全局线索。
然而,这些方法的一个常见限制,包括扩张卷积和池化在内,它们都在方形窗口中探测输入特征图。这限制了它们在捕获广泛存在于现实场景中的各向异性的上下文上的灵活性。
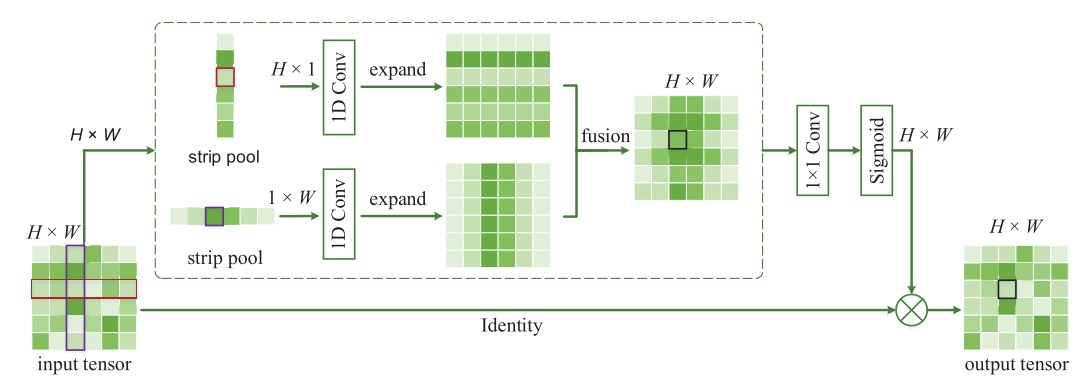
- CVPR2020 带状池化(Strip Pooling)
- 为了更有效地捕获长依赖关系,本文在空间池化扩大CNNs的感受野和捕获上下文信息的基础上,提出了条纹池化的概念,作为全局池化的替代方案。
- 优点:
- 它沿着一个空间维度部署一个长条状的池化核形状,因此能够捕获孤立区域的长距离关系
- 在其他空间维度上保持较窄的内核形状,便于捕获局部上下文,防止不相关区域干扰标签预测
- 集成这种长而窄的池内核使语义分割网络能够同时聚合全局和本地上下文。这与传统的从固定的正方形区域收集上下文的池化有本质的不同。
- 基于条纹池化的想法,作者提出了两种即插即用的池化模块:
- Strip Pooling Module (SPM)
- Mixed Pooling module (MPM)
代码练习
完善 HybridSN 高光谱分类网络
模型的网络结构为如下图所示:
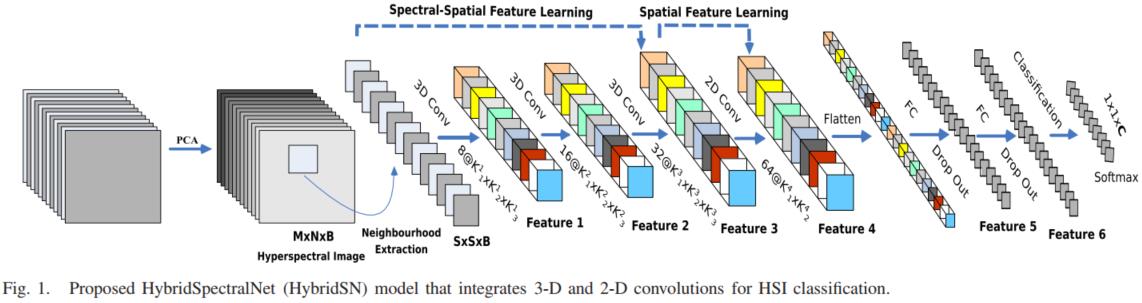
三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
下面是 HybridSN 类的代码:
class_num = 16
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1=nn.Conv3d(in_channels=1,out_channels=8,kernel_size=(7,3,3))
self.bn1 = nn.BatchNorm3d(8)
self.conv2=nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3))
self.bn2 = nn.BatchNorm3d(16)
self.conv3=nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3))
self.bn3 = nn.BatchNorm3d(32)
self.se1 = SELayer(576, 16)
self.conv4 = nn.Conv2d(576, 64, 3)
self.bn4 = nn.BatchNorm2d(64)
self.se2 = SELayer(64, 16)
self.fc1=nn.Linear(18496,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,class_num)
self.dropout = nn.Dropout(p=0.4)
# self.soft = nn.Softmax(dim = 1)
def forward(self, x):
x = self.conv1(x)
# x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
# x = self.bn2(x)
x = F.relu(x)
x = self.conv3(x)
# x = self.bn3(x)
x = F.relu(x)
x = torch.reshape(x,[x.shape[0],576,19,19])
# x = self.se1(x)
x = self.conv4(x)
# x = self.bn4(x)
# x = self.se2(x)
x = F.relu(x)
x = torch.flatten(x,start_dim=1)
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.fc3(x)
# x = self.soft(x)
return x
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
准确率为 95.96%
性能良好,测试结果稳定。
也可以考虑解开代码注释部分加入BN,进一步提升性能。
准确率为 96.61%
先后顺序:Batch Normalization 层恰恰插入在 Conv 层或全连接层之后,而在 ReLU等激活层之前。而对于 dropout 则应当置于 activation layer 之后。
注意:BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
SENet 实现
该网络通过学习的方式获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
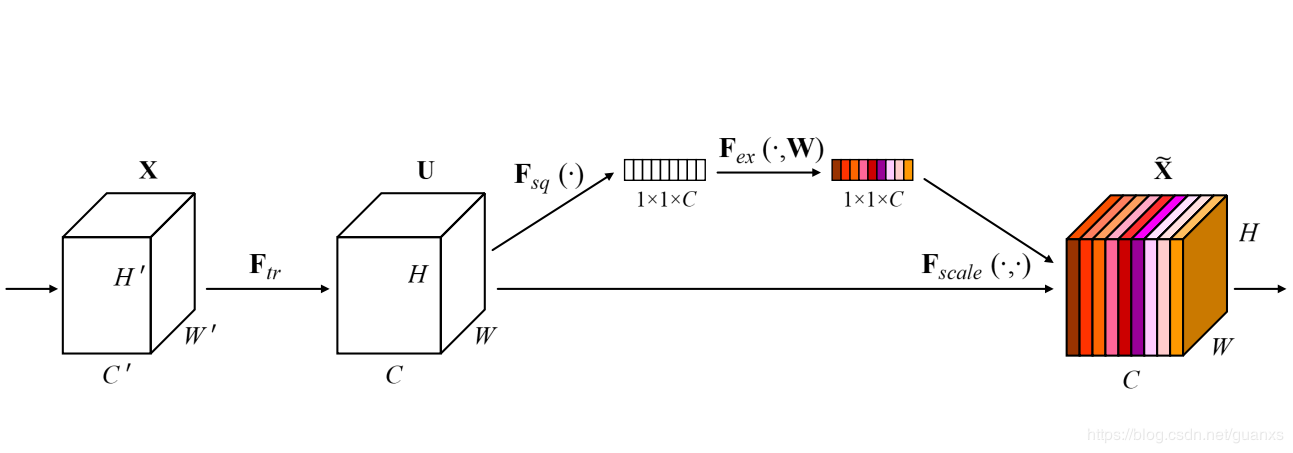
将上方代码SE注释部分解开,加入SE模块。
准确率为 97.36%
SE模块主要为了提升模型对channel特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。
总结:
| 方法 | accuracy |
|---|---|
| 普通HybridSN | 95.96% |
| 加入BN | 96.61% |
| 加入SENet | 97.36% |
其他的还可以通过添加学习率衰减函数来提升性能,这里mark一下,以后做个实验验证。
ResNet预训练模型 垃圾分类识别
AI研习社最新的比赛:垃圾分类识别
老师让我们试一试,我找了个预训练的ResNet模型微调了一下,加了几个简单的trick,结果如下:

离标准分_85还是有些距离,看来通用的网络并不比针对特定问题设计的网络表现更好。
后续我会继续关注比赛,争取学习更多的深度学习知识,设计出更加强大的网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号