【ArcGIS】好好的属性表,咋就乱码了呢?
我就瞎说一下,反正你也不懂。
——见到许多ArcGis属性表乱码的问题,也见过各种哭笑不得的解说
目录
第一节 字符编码那些事儿
计算机以二进制的形式存储信息。每个“字”都会用特定的一组代码(1-4个不等的字节,1个字节=8个二进制位)表示,也就是编个号,这种表示规则叫做“字符编码”。计算机会根据二进制的“编号”信息去“编号规则(字符编码)”对应的“字符集”查找其所对应的“字”,使用对应的字体(字符集对应若干“字体库”)显示出来。从别处拷贝或者网络来一个文件,系统环境或者编码规则没选对,那就乱了呗。
ASCII
话说当年,美国佬最早发明了“字符编码”这种东西,起名叫ASCII(American standard Code for information Interchange)。它包含了128个字符(0-127),每个字符用8个二进制位表示,第1位规定为0,后7位标识一个字符。比如‘A’表示为二进制是01000001,十进制是65,十六进制是0x41,这也就是我们常说的一个英文字母占1个字节,8bit=1Byte。
美国佬觉得一个字节(可以表示256个十进制编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前128个编码)。后来,欧洲国家不干了,他们发现ASCII并不能标识他们的字母,于是ASCII中127号之后的空位被用来表示这些字符,128-255这一页字符集被称为扩展字符集。为啥是-255?8个二进制位表示十进制数最大也就是255。
这就够了?差的远呢!
GB2312
后来,中国也用上计算机了,日本、韩国……一众国家也用上了,这回事儿大了,这么些文字怎么表示?
字符编码方案GB2312就这样出来了,它相当于对ASCII的扩展。该编码方案中,小于等于127的继续使用原ASCII编码,用2个大于127的字节表示一个中文字符,前面的一个字节(称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样就一组就给大约7000多个简体汉字编码了。在这些编码中,数学符号,希腊的字母,日文的假名都编进去了,连ASCII里本来就有的数字,标点,字母都统统重新编了两个字节长的编码,这就是常说的“全角”符号,原有的127号以前的那些字符称为“半角”符号。
当然,日本、韩国等的一众国家也整出了自己的双字节字符编码方案。
GBK
再后来……这点中文还是不够用啊!生僻字和繁体字等还是无法识别怎么办?于是改了编码规则:要求高字节(第一个字节)大于127的就认为是2字节的中文字符(低字节(第二个字节)那里0-127也用上了),这样拓展之后就是GBK标准。GBK收录了2万多汉字及符号,因其最早被WINDOWS采用,所以其应用范围非常广。但后来少数民族同胞也要用计算机,于是为了扩展少数民族字符,GBK被扩展为GB18030。
中国GBK、日本Shift_JIS、韩国EUC-KR……这些编码规则都使用了ANSI标准,这里面存在一个bug。都是双字节表示一个文字,那中文到韩文系统下会发生什么情况?乱码!你猜对了。
UTF-8
上面太乱了,ISO(国际标准化组织)决定制定一个统一的包括全世界所有字符的编码标准,包括字符集、编码方案等,叫做"Universal Multiple-Octet Coded Chracter Set",简称UCS,俗称Unicode标准(注意想想ANSI标准,它俩都不是具体的字符编码规则),“万国码”出来了,看你还怎么乱。
作为Unicode字符集的一种编码方式,UTF-8采用变长编码,使用1-4个字节表示一个字符,其特点是,对不同范围的字符使用不同长度的编码。这样,UTF-8中那些半角字符就用1个字节(8个二进制位)表示,而中文使用3个字节表示。
第二节 都是编码惹的祸
编码说,这个锅它不想背。
前面说了windows系统默认使用ANSI编码标准,中文系统下是GBK,10.2之前的ArcGis也默认这个“默认”给dbf编码,所以2个字节表示一个汉字,所以一个字段名最多(10字节)5个汉字。
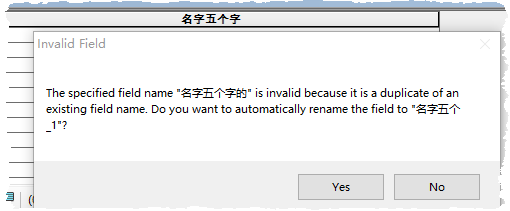
而自10.2.1之后,Esri潮了一把,dbf编码用了UTF-8,这样一个字段名也就只能写3个汉字了,因为10mod3=1。
这样一来,导出新的文件由gbk→UTF8就导致字段名字符截断的问题。
从别处拷贝或者网络来一个Shapefile文件,系统环境或者编码规则没选对,那就乱了呗。
第三节 dbf犯的错
在ArcGIS Desktop 创建 shapefile 文件,其dbf头文件(dBase Header)中,一般会包含使用的编码类型的信息,即 LDID ( Language Driver ID),它告诉应用程序用何种编码类型去正确读取它。一般,在Shapefile的子文件中有同名 *.cpg 文件,也存储了编码信息,用记事本打开,可看到如UTF-8、936。二者都标识了dbf的编码方式,被ArcGIS 识别的优先顺序是,LDID 优先于 CPG文件。
修改默认Codepage,可以改变ArcGis创建新Shapefile文件时dbf的编码格式。注意!这里划重点,改了这里只是以后创建新的采用何种编码方式,并不会改变已有dbf文件的编码方式,也就解决不了它的乱码!
ArcMap读取dbf属性表乱码的备选解决方案:
1、添加同名文件 *.cpg
由于Shapefile是开放数据格式,所以有可能在使用第三方工具创建或者其他一些情况中,忽略了 Language Driver ID的声明,可能会导致读取乱码,这时,尝试添加同名文件 *.cpg 。
2、换个ArcGis版本打开Shapefile数据
10-10.2版本为一组,默认dbf编码为gbk;10.2.1+的版本为一组,默认dbf编码为utf-8。如果在一组下出现乱码,那么换另一组看看。
3、溯源
谁给的数据,用什么版本生成的数据,用源头ArcMap将数据保存至地理数据库交付于你。
ArcGis属性表导出Excel乱码
移步ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
参考:
ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
 ArcGis交流群
ArcGis交流群

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下