Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
hive可以创建带分区的内表,
> create table sustPart (id int,name string) //创建表名为sust1
> partitioned by(country string) // 按国家进行分区
> row format delimited fields terminated by ',' ; //使用逗号进行分隔
根据分区进行查找人名 select count(1) from sustPart where country='China' group by (name='liyaozhou');
展示分区: show partitions + 表名; 如 show partitions sustPartion;
https://blog.csdn.net/weixin_38201936/article/details/88615988
hive执行计划解析
在从hive的sql,到最终出来执行结果,中间经历了MR流程,其中MR的map,combiner,shuffle,reduce具体是执行了hive的那个部分,这样就会比较全面。
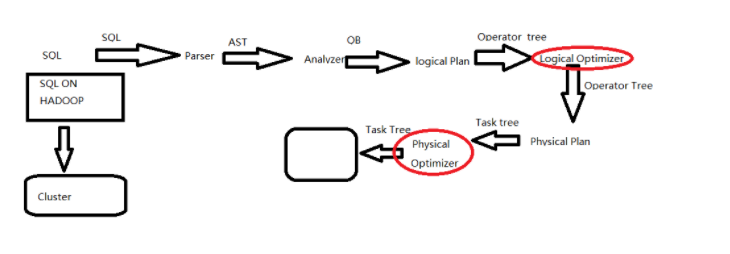
- sql写出来以后只是一些字符串的拼接,所以要经过一系列的解析处理,才能最终变成集群上的执行的作业
- Parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质还是字符串
- Analyzer:语法解析,生成QB(query block)
- Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
- Logical optimizer:进行逻辑执行计划优化,生成一堆优化后的Opertator Tree
- Phsical plan:物理执行计划解析,生成tasktree
- Phsical Optimizer:进行物理执行计划优化,生成优化后的tasktree,该任务即是集群上的执行的作业
- 结论:经过以上的六步,普通的字符串sql被解析映射成了集群上的执行任务,最重要的两步是 逻辑执行计划优化和物理执行计划优化(图中红线圈画)
https://blog.csdn.net/qq_32641659/article/details/89421655
Hadoop Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。
它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。HIVE不适合用于联机online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合。
Hive 的官方文档中对查询语言有了很详细的描述,请参考:http://wiki.apache.org/hadoop/Hive/LanguageManual ,本文的内容大部分翻译自该页面,期间加入了一些在使用过程中需要注意到的事项。
DML 操作:元数据存储
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
DML包括:INSERT
插入、UPDATE
更新、DELETE
删除
•向数据表内加载文件
•将查询结果插入到Hive表中
•0.8新特性 insert into
一般 SELECT 查询会扫描整个表,使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性
•Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝
Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务
•LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况
•LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
•join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
•实践中,应该把最大的那个表写在最后
join 查询时,需要注意几个关键点
•只支持等值join
•SELECT a.* FROM a JOIN b ON (a.id = b.id)
•SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
•可以 join 多于 2 个表,例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
•如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
LEFT,RIGHT和FULL OUTER
•例子
•SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
•如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写
•容易混淆的问题是表分区的情况
• SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds='2010-07-07' AND b.ds='2010-07-07‘
•如果 d 表中找不到对应 c 表的记录,d 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 d 表中不能找到匹配 c 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关
•解决办法
•SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds='2009-07-07' AND c.ds='2009-07-07')
LEFT SEMI JOIN
•LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
•
•SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
UNION ALL
•用来合并多个select的查询结果,需要保证select中字段须一致
•select_statement UNION ALL select_statement UNION ALL select_statement ...
3.2 基于Partition的查询
•一般 SELECT 查询会扫描整个表,使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性
•Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝
3.3 Join
Syntax
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
•Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务
•LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况
•LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
•join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
•实践中,应该把最大的那个表写在最后
join 查询时,需要注意几个关键点
•只支持等值join
•SELECT a.* FROM a JOIN b ON (a.id = b.id)
•SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
•可以 join 多于 2 个表,例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
•如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
LEFT,RIGHT和FULL OUTER
•例子
•SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
•如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写
•
•容易混淆的问题是表分区的情况
• SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds='2010-07-07' AND b.ds='2010-07-07‘
•如果 d 表中找不到对应 c 表的记录,d 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 d 表中不能找到匹配 c 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关
•解决办法
•SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds='2009-07-07' AND c.ds='2009-07-07')
LEFT SEMI JOIN
•LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
•
•SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
UNION ALL
•用来合并多个select的查询结果,需要保证select中字段须一致
•select_statement UNION ALL select_statement UNION ALL select_statement ...
4. 从SQL到HiveQL应转变的习惯
1、Hive不支持等值连接
•SQL中对两表内联可以写成:
•select * from dual a,dual b where a.key = b.key;
•Hive中应为
•select * from dual a join dual b on a.key = b.key;
而不是传统的格式:
SELECT t1.a1 as c1, t2.b1 as c2FROM t1, t2 WHERE t1.a2 = t2.b2
•分号是SQL语句结束标记,在HiveQL中也是,但是在HiveQL中,对分号的识别没有那么智慧,例如:
•select concat(key,concat(';',key)) from dual;
•但HiveQL在解析语句时提示:
FAILED: Parse Error: line 0:-1 mismatched input '<EOF>' expecting ) in function specification
•解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成:
•select concat(key,concat('\073',key)) from dual;
3、IS [NOT] NULL
•SQL中null代表空值, 值得警惕的是, 在HiveQL中String类型的字段若是空(empty)字符串, 即长度为0, 那么对它进行IS NULL的判断结果是False.
4、Hive不支持将数据插入现有的表或分区中,
仅支持覆盖重写整个表,示例如下:
-
INSERT OVERWRITE TABLE t1
-
4、hive不支持INSERT INTO, UPDATE, DELETE操作
这样的话,就不要很复杂的锁机制来读写数据。
INSERT INTO syntax is only available starting in version 0.8。INSERT INTO就是在表或分区中追加数据。
5、hive支持嵌入mapreduce程序,来处理复杂的逻辑
如:
-
-
MAP doctext USING 'python wc_mapper.py' AS (word, cnt)
-
-
-
-
REDUCE word, cnt USING 'python wc_reduce.py';
--doctext: 是输入
--word, cnt: 是map程序的输出
--CLUSTER BY: 将wordhash后,又作为reduce程序的输入
并且map程序、reduce程序可以单独使用,如:
-
-
-
SELECT sessionid, tstamp, data
-
DISTRIBUTE BY sessionid SORT BY tstamp
-
-
REDUCE sessionid, tstamp, data USING 'session_reducer.sh';
--DISTRIBUTE BY: 用于给reduce程序分配行数据
6、hive支持将转换后的数据直接写入不同的表,还能写入分区、hdfs和本地目录。
这样能免除多次扫描输入表的开销。
-
-
-
INSERT OVERWRITE TABLE t2
-
-
-
-
-
-
INSERT OVERWRITE DIRECTORY '/output_dir'
-
-
-
WHERE t3.c1 > 20 AND t3.c1 <= 30
-
-
-
INSERT OVERWRITE LOCAL DIRECTORY '/home/dir'
-
-
-
-
-
- https://zhuanlan.zhihu.com/p/123007983
-
分组排序窗口函数
1、ntile(n) over()
ntile(n) over(partition by ...A... order by ...B...) -- 均分成n份
n:切分的片数
A:分组的字段名称
B:排序的字段名称
- NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
- NTILE()不支持ROWS BETWEEN ,比如NTILE(2) OVER(PARTITION BY ... ORDER BY ...ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
- 如果切片不均匀,默认增加第一个切片的分布
--将2019年1月的支付用户,按照支付金额分成5组--
SELECT user_name,
sum(pay_amount) as pay_amount,
ntile(5) over(order by sum(pay_amount) desc) level
FROM user_trade
WHERE substr(dt,1,7) = '2019-01'
GROUP BY user_name;
练习
- 选出2019年退款金额排名前10%的用户:选出2019年退款金额排名前10%的用户:
--选出2019年退款金额排名前10%的用户--
SELECT a.user_name,
a.refund_amount,
a.level
FROM
(SELECT user_name,
sum(refund_amount) as refund_amount,
ntile(10) over(order by sum(refund_amount) desc) level
FROM user_refund
WHERE year(dt)=2019
GROUP BY user_name)a
WHERE a.level = 1;
四、偏移窗口函数
1、lag(...) over(...) 、lead(...) over(...)
相对于当前的行偏移 ; Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用中,若要用到取今天和昨天的某字段差值时,Lag和Lead 函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与 left join 、right join 等自连接相比,效率更高,SQL更简洁。
lag(exp_str,offset,defval) over(partition by ...... oredr by ......)
lead(exp_str,offset,defval) over(partition by ...... oredr by ......)
- exp_str是字段名称;
- offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第五行,offset 为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)。offset默认值为1;
- defval 默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错。
lag()实例:
--Alice和Alexander的各种时间偏移--
SELECT user_name,
dt,
lag(dt,1,dt) over(partition by user_name order by dt),
lag(dt) over(partition by user_name order by dt),
lag(dt,2,dt) over(partition by user_name order by dt),
lag(dt,2) over(partition by user_name order by dt)
FROM user_trade
WHERE dt > '0'
and user_name in ('Alice','Alexader');
lead()实例:
--Alice和Alexander的各种时间偏移--
SELECT user_name,
dt,
lead(dt,1,dt) over(partition by user_name order by dt),
lead(dt) over(partition by user_name order by dt),
lead(dt,2,dt) over(partition by user_name order by dt),
lead(dt,2) over(partition by user_name order by dt)
FROM user_trade
WHERE dt >'0'
and user_name in ('Alice','Alexander');
练习:支付时间间隔超过100天的用户数
SELECT count(distinct user_name)
FROM
(SELECT user_name,
dt,
lead(dt) over(partition by user_name order by dt) lead_dt
FROM user_trade
WHERE dt>'0')a
WHERE a.lead_dt is not null
and datediff(a.lead_dt,a.dt)>100;



