


python--学习笔记11 pandas groupby
在没有数据库的情况下,可以用pandas进行简单的分组函数处理情况。
import pandas as pd
csv_data = pd.read_csv('E:\\saleprice.csv', encoding = 'gb18030') %如果出现UTF-8不能编译的情况
from pandas import DataFrame,Series
a=DataFrame(csv_data)
a.describe
s = a.groupby(['type','datee'])['saleprice'].sum()
s.to_csv('e:\\salesprice.csv')
max min sum mean
quantile(0.75) 求样本分位数
经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”。表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。

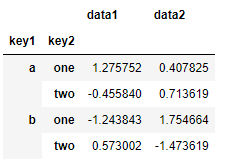
在两个索引相互交叠的情况下,使用.unstack()函数,将数据转化为表格的形式,满足行列两个索引,更直观,方便比较。
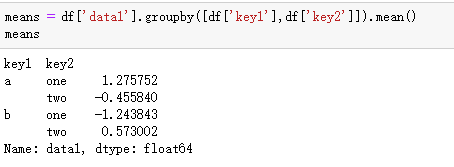
import pandas as pd import numpy as np from pandas import DataFrame df = DataFrame({'key1':['a','a','b','b','a'], 'key2': ['one','two','one','two','one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)}) means = df.groupby([df['key1'],df['key2']]).mean() means
不输入值的时候,mean默认对date1和date2都进行取平均操作。
除了数组,分组信息也可以通过别的形式,比如mapping,series等方法。
还可以通过函数进行分组。
pandas可以根据指定面元或者分位数将数据拆分成多块(cut和qcut),将这些函数和groupby结合起来,就可以对数据集进行桶(bucket)或者分位数(quantile)分析。
可以使用apply引入定义好的函数
透视表
.corr()
可以判断pandas数据特征之间的相关性,默认返回每个行-列对中的pearson系数。
dropna(how='any',axis = 0)
# DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
主要的2个参数:
#axis=0: 删除包含缺失值(NaN)的行
#axis=1: 删除包含缺失值(NaN)的列
# how=‘any’ :要有缺失值(NaN)出现删除
# how=‘all’: 所有的值都缺失(NaN)才删除
这两个要配合使用才好。
还有一个thresh参数
如果缺失值(NaN)的数量大于thresh,将删除
1.loc意义:通过行标签索引行数据
例: loc[n]表示索引的是第n行(index 是整数)
loc[‘d’]表示索引的是第’d’行(index 是字符)
2. .iloc :通过行号获取行数据,不能是字符
3. ix——结合前两种的混合索引
三者区别:
ix / loc 可以通过行号和行标签进行索引,比如 df.loc['a'] , df.loc[1], df.ix['a'] , df.ix[1]
而iloc只能通过行号索引 , df.iloc[0] 是对的, 而df.iloc['a'] 是错误的
建议:
当用行号索引的时候, 尽量用 iloc 来进行索引; 而用标签索引的时候用 loc , ix 尽量别用。


