python--学习笔记6 pandas
from pandas import Series,DataFrame #注意大小写 import pandas as pd
Series的字符串表现形式为:索引在左边,值在右边。
可以通过Series的values和index属性获得其数组表现形式和索引对象。
与普通Numpy数组相比,可以通过索引的方式选取Series中的单个或一组值。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型。它既有行索引也有列索引。
构建DataFrame的方法很多,最常用的是直接传入一个由等长列表或者numpy数组组成的字典,并且会自动加上索引列。也可以指定列顺序。
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = DataFrame(data)
DataFrame(data,cloums=['year','state','pop'])
注:通过索引方式返回的列只是相应数据的视图而已,因此,对返回的series所做的任何修改都会反映到源DataFrame上。通过Series的copy方法即可显式地复制列。
reindex
创建一个适应新索引的新对象,即会根据新索引进行重排,如果某个索引值当前不存在,就引入缺失值。
| 参数 | 说明 |
| ffill或pad | 前向填充 |
| bfill或backfill | 后向填充 |
pandas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取单个值或从DataFrame的行或列中提取一个Series。跟对应的Numpy数组方法相比,它们都是基于没有缺失数据的假设而构建的。
.describe 一次性产生多个汇总统计.
利用DataFrame的corrwith方法,可以计算其列和行与另一个列或者行之间的相关系数。
唯一值
obj = Series(['c','a','d','a','a','b','b','c','c']) uniques=obj.unique() uniques
输出 array([c,a,d,b], dtype=object)
返回的唯一值是未排序的,如果需要的话,可以对结果再次排序( uniques.sort() )。
value_counts用于计算一个Series中各值出现的频率。是一个顶级pandas方法,可以用于任何数组或序列。
Pandas对象上的所有描述和统计都排除了缺失数据,即浮点值NaN和None。
1. dropna 过滤缺失数据。对于一个Series,dropna返回一个仅含有非空数据和索引值的Series。 data.dropna()
2. 使用布尔型索引 data[data.notnull()]
而对于DataFrame对象,事情有些复杂,dropna默认丢弃任何含有缺失值的行。而加上 data.dropna(how='all')将只丢弃全为NA的行。丢弃列的话只需传入axis=1
另一个滤除DataFrame行的问题涉及时间序列数据,如果只想留下一部分观测数据,可以使用thresh参数实现。
填充缺失数据
fillna(0)可以将缺失值替换成常数值,0可以换。如果是通过一个字典调用的fillna,则可实现对不同列填充不同的值。df.fillna({1: 0.5, 3: -1}) 给第二列空值赋 0.5,第4列赋-1。 也可以传入series的平均值,中位值,向下向上填充等等。
层次化索引
在数据重塑和基于分组的操作中很重要。在一个轴上拥有多个索引。
pandas 自动类型转化 TextParser类。
1 from pandas.io.parsers import TextParser 2 3 def parse_option_data(tabl): 4 rows = table.findall('.//tr') 5 header = _unpack(rows[0], kind='th') 6 data = [_unpack(r) for r in rows[1:]] 7 return TextParser(data, names = header).get_chunk()
离散化和面元(bin)划分
要实现该功能,需要使用pandas的cut函数:
1 ages = [20,22,25,27,21,23,37,31,61,45,41,32] 2 bins = [18,25,35,69,100] 3 cats=pd.cut(ages,bins) 4 pd.value_counts(cats) 5 6 output:(18, 25] 5 7 (35, 69] 4 8 (25, 35] 3 9 (69, 100] 0 10 dtype: int64
如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。下面的例子将一些均匀分布的数据分为四组:
1 data=np.random.rand(20) 2 pd.cut(data,4,precision=2)--精确两位小数
qcut是类似于cut的函数,根据样本分位数进行面元划分,可以保证每个面元中含有相同数量的数据点。
这两个离散化函数对于分量和分组分析非常重要。
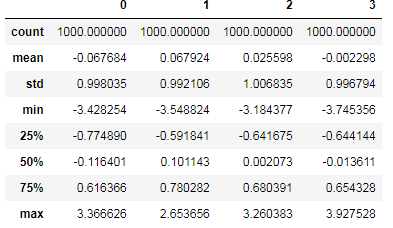
异常值,也叫孤立点或者离群值,它的过滤或者变换很大程度上其实是数组运算。下面看一个含有正态分布数据的DataFrame:
1 np.random.seed(12345) 2 data=DataFrame(np.random.randn(1000,4)) 3 data.describe()