shell数据筛选
聊聊大家常说的数据分析:
- 数据收集:负责数据的收集
- 数据清洗:负责数据的筛选
- 数据分析:数据运算、整理
- 数据展示:图表或表格方式输出结果
shell脚本数据的处理
1)数据检索:grep tr cut
2)数据处理:uniq sort tee paste xargs
之前的脚本中我们都是通过grep、cut、tr、uniq、sort等命令通过管道组合在一起将字符串检索出来,然后在通过shell中对应的运算得到结果,在数据检索过程中大家可能也体会到了其中的辛苦和蹩脚。没办法,会的就这么多,还需要完成任务。
缺点:复杂的命令组合
多次运算
上手难
解决办法
好了,学完这节课大家的所有之前的痛苦就都能解决了,今天要给大家介绍一个更加厉害的命令awk。他可以让大家从输出流中检索出自己需要的数据而不需要再向以前那样通过大量命令组合来完成,只需一个命令awk就能完成。并且还能够通过awk对数据进行处理,而不再需要额外的shell运算。
awk的应用场景
字符串截取
数据运算
比如内存使用率脚本
shell对输出流的处理-awk
1、awk介绍
在日常计算机管理中,总会有很多数据输出到屏幕或者文件,这些输出包含了标准输出、标准错误输出。默认情况下,这些信息全部输出到默认输出设备—屏幕。然而,大量的数据输出中,只有一小部分是我们需要重点关注的,我们需要把我们需要的或者关注的这些信息过滤或者提取以备后续需要时调用。早先的学习中,我们学过使用grep来过滤这些数据,使用cut、tr命令提出某些字段,但是他们都不具备提取并处理数据的能力,都必须先过滤,再提取转存到变量,然后在通过变量提取去处理,比如:
内存使用率的统计步骤
1) 通过free -m提取出内存总量,赋值给变量 memory_totle
2)通过free -m提取出n内存使用量,赋值给变量memory_use
3)通过数学运算计算内存使用率
需要执行多步才能得到内存使用率,那么有没有一个命令能够集过滤、提取、运算为一体呢?当然,就是今天我要给大家介绍的命令:awk
平行命令还有gawk、pgawk、dgawk
awk是一种可以处理数据、产生格式化报表的语言,功能十分强大。awk 认为文件中的每一行是一条记录 记录与记录的分隔符为换行符,每一列是一个字段 字段与字段的分隔符默认是一个或多个空格或tab制表符.
awk的工作方式是读取数据,将每一行数据视为一条记录(record)每条记录以字段分隔符分成若干字段,然后输出各个字段的值.
2、awk语法
awk [options] ‘[BEGIN]{program}[END]’ [FILENAME]
常用命令选项
-F fs 指定描绘一行中数据字段的文件分隔符 默认为空格
-f file 指定读取程序的文件名
-v var=value 定义awk程序中使用的变量和默认值
注意:awk 程序由左大括号和右大括号定义。 程序命令必须放置在两个大括号之间。由于awk命令行假定程序是单文本字符串,所以必须将程序包括在单引号内。
1)程序必须放在大括号内
2)程序必须要用单引号引起来
awk程序运行优先级是:
1)BEGIN: 在开始处理数据流之前执行,可选项
2)program: 如何处理数据流,必选项
3)END: 处理完数据流后执行,可选项
3、awk基本应用
能够熟练使用awk对标准输出的行、列、字符串截取
学习用例
[root@zutuanxue ~]# cat test
1 the quick brown fox jumps over the lazy cat . dog
2 the quick brown fox jumps over the lazy cat . dog
3 the quick brown fox jumps over the lazy cat . dog
4 the quick brown fox jumps over the lazy cat . dog
5 the quick brown fox jumps over the lazy cat . dog
3.1)awk对字段(列)的提取
字段提取:提取一个文本中的一列数据并打印输出
字段相关内置变量
$0 表示整行文本
$1 表示文本行中的第一个数据字段
$2 表示文本行中的第二个数据字段
$N 表示文本行中的第N个数据字段
$NF 表示文本行中的最后一个数据字段
读入test每行数据并把每行数据打印出来
[root@zutuanxue ~]# awk '{print $0}' test
1 the quick brown fox jumps over the lazy cat . dog
2 the quick brown fox jumps over the lazy cat . dog
3 the quick brown fox jumps over the lazy cat . dog
4 the quick brown fox jumps over the lazy cat . dog
5 the quick brown fox jumps over the lazy cat . dog
打印test第六个字段
[root@zutuanxue ~]# awk '{print $6}' test
jumps
jumps
jumps
jumps
jumps
打印test最后一个字段
[root@zutuanxue ~]# awk '{print $NF}' test
dog
dog
dog
dog
dog
3.2)命令选项详解
-F: 指定字段与字段的分隔符
当输出的数据流字段格式不是awk默认的字段格式时,我们可以使用-F命令选项来重新定义数据流字段分隔符。比如:
处理的文件是/etc/passwd,希望打印第一列、第三列、最后一列
[root@zutuanxue ~]# awk -F ':' '{print $1,$3,$NF}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network 192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
postfix 89 /sbin/nologin
chrony 998 /sbin/nologin
sshd 74 /sbin/nologin
ntp 38 /sbin/nologin
tcpdump 72 /sbin/nologin
nscd 28 /sbin/nologin
mysql 997 /sbin/nologin
www 996 /sbin/nologin
apache 48 /sbin/nologin
tss 59 /sbin/nologin
zabbix 995 /sbin/nologin
saslauth 994 /sbin/nologin
grafana 993 /sbin/nologin
可以看的出,awk输出字段默认的分隔符也是空格
-f file: 如果awk命令是日常重复工作,而又没有太多变化,可以将程序写入文件,每次使用-f调用程序文件就好,方便,高效。
[root@zutuanxue ~]# cat abc
{print $1,$3,$NF}
[root@zutuanxue ~]# awk -f abc test
1 quick dog
2 quick dog
3 quick dog
4 quick dog
5 quick dog
-v 定义变量,既然作者写awk的时候就是按着语言去写的,那么语言中最重要的要素—变量肯定不能缺席,所以可以使用-v命令选项定义变量
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
定义了一个变量 name=baism,然后调用变量读出数据。
3.3)awk对记录(行)的提取
记录提取:提取一个文本中的一行并打印输出
记录的提取方法有两种:a、通过行号 b、通过正则匹配
记录相关内置变量
NR: 指定行号 number row
提取test第三行数据
指定行号为3
[root@zutuanxue ~]# awk 'NR==3{print $0}' test
3 the quick brown fox jumps over the lazy cat . dog
指定行的第一个字段精确匹配字符串为3
[root@zutuanxue ~]# awk '$1=="3"{print $0}' test
3 the quick brown fox jumps over the lazy cat . dog
3.4)awk对字符串提取
记录和字段的汇合点就是字符串
打印test第三行的第六个字段
[root@zutuanxue ~]# awk 'NR==3{print $6}' test
jumps
4、awk程序的优先级
awk代码块的优先级
关于awk程序的执行优先级,BEGIN是优先级最高的代码块,是在执行PROGRAM之前执行的,不需要提供数据源,因为不涉及到任何数据的处理,也不依赖与PROGRAM代码块;PROGRAM是对数据流干什么,是必选代码块,也是默认代码块。所以在执行时必须提供数据源;END是处理完数据流后的操作,如果需要执行END代码块,就必须需要PROGRAM的支持,单个无法执行。
BEGIN:处理数据源之前干什么 不需要数据源就可以执行
PROGRAM: 对数据源干什么 【默认必须有】 需要数据源
END:处理完数据源后干什么 需要program 需要数据源
优先级展示
[root@zutuanxue ~]# awk 'BEGIN{print "hello zutuanxue"}{print $0}END{print "bye zutuanxue"}' test
hello zutuanxue
1 the quick brown fox jumps over the lazy cat . dog
2 the quick brown fox jumps over the lazy cat . dog
3 the quick brown fox jumps over the lazy cat . dog
4 the quick brown fox jumps over the lazy cat . dog
5 the quick brown fox jumps over the lazy cat . dog
bye zutuanxue
不需要数据源,可以直接执行
[root@zutuanxue ~]# awk 'BEGIN{print "hello world"}'
hello world
没有提供数据流,所以无法执行成功
[root@zutuanxue ~]# awk '{print "hello world"}'
[root@zutuanxue ~]# awk 'END{print "hello world"}'
5、awk高级应用
awk是一门语言,那么就会符合语言的特性,除了可以定义变量外,还可以定义数组,还可以进行运算,流程控制,我们接下来看看吧。
5.1)awk定义变量和数组
定义变量
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
[root@zutuanxue ~]# awk 'BEGIN{name="baism";print name}'
baism
数组定义方式: 数组名[索引]=值
定义数组array,有两个元素,分别是100,200,打印数组元素。
[root@zutuanxue ~]# awk 'BEGIN{array[0]=100;array[1]=200;print array[0],array[1]}'
100 200
[root@zutuanxue ~]# awk 'BEGIN{a[0]=100;a[1]=200;print a[0]}'
100
[root@zutuanxue ~]# awk 'BEGIN{a[0]=100;a[1]=200;print a[1]}'
200
5.2)awk运算
- 赋值运算 =
- 比较运算 > >= == < <= !=
- 数学运算 + - * / % ** ++ –
- 逻辑运算 && || !
- 匹配运算 ~ !~ 精确匹配 == !=
a.赋值运算:主要是对变量或者数组赋值,如:
变量赋值 name=‘baism’ school=‘zutuanxue’
数组赋值 array[0]=100
[root@zutuanxue ~]# awk -v name='baism' 'BEGIN{print name}'
baism
[root@zutuanxue ~]# awk 'BEGIN{school="zutuanxue";print school}'
zutuanxue
[root@zutuanxue ~]# awk 'BEGIN{array[0]=100;print array[0]}'
100
b.比较运算,如果比较的是字符串则按ascii编码顺序表比较。如果结果返回为真则用1表示,如果返回为假则用0表示
ascii
[root@zutuanxue ~]# awk 'BEGIN{print "a" >= "b" }'
0
[root@zutuanxue ~]# awk 'BEGIN{print "a" <= "b" }'
1
[root@zutuanxue ~]# awk '$1>4{print $0}' test
5 the quick brown fox jumps over the lazy cat . dog
[root@zutuanxue ~]# awk 'BEGIN{print 100 >= 1 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100 == 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 <= 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 < 1 }'
0
[root@zutuanxue ~]# awk 'BEGIN{print 100 != 1 }'
1
c.数学运算
[root@zutuanxue ~]# awk 'BEGIN{print 100+3 }'
103
[root@zutuanxue ~]# awk 'BEGIN{print 100-3 }'
97
[root@zutuanxue ~]# awk 'BEGIN{print 100*3 }'
300
[root@zutuanxue ~]# awk 'BEGIN{print 100/3 }'
33.3333
[root@zutuanxue ~]# awk 'BEGIN{print 100**3 }'
1000000
[root@zutuanxue ~]# awk 'BEGIN{print 100%3 }'
1
[root@zutuanxue ~]# awk -v 'count=0' 'BEGIN{count++;print count}'
1
[root@zutuanxue ~]# awk -v 'count=0' 'BEGIN{count--;print count}'
-1
d.逻辑运算
与运算:真真为真,真假为假,假假为假
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 && 100>=3 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 && 1>=100 }'
0
或运算:真真为真,真假为真,假假为假
[root@zutuanxue ~]# awk 'BEGIN{print 100>=2 || 1>=100 }'
1
[root@zutuanxue ~]# awk 'BEGIN{print 100>=200 || 1>=100 }'
0
非运算
[root@manage01 resource]# awk 'BEGIN{print ! (100>=2)}'
0
e.匹配运算
[root@zutuanxue ~]# awk -F ':' '$1 ~ "^ro" {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@zutuanxue ~]# awk -F ':' '$1 !~ "^ro" {print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
nscd:x:28:28:NSCD Daemon:/:/sbin/nologin
mysql:x:997:995::/home/mysql:/sbin/nologin
www:x:996:994::/home/www:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
zabbix:x:995:993:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin
grafana:x:993:992:grafana user:/usr/share/grafana:/sbin/nologin
5.3)awk 环境变量
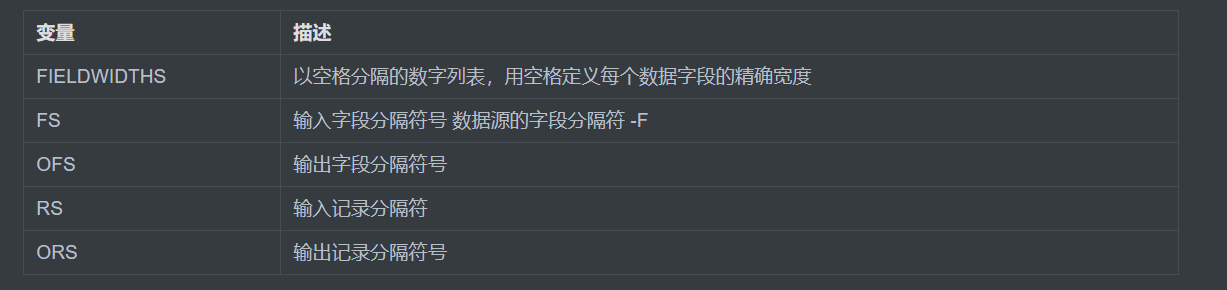
FIELDWIDTHS:重定义列宽并打印,注意不可以使用$0打印所有,因为$0是打印本行全内容,不会打印你定义的字段
[root@zutuanxue ~]# awk 'BEGIN{FIELDWIDTHS="5 2 8"}NR==1{print $1,$2,$3}' /etc/passwd
root: x: 0:0:root
FS:指定数据源中字段分隔符,类似命令选项-F
[root@zutuanxue ~]# awk 'BEGIN{FS=":"}NR==1{print $1,$3,$NF}' /etc/passwd
root 0 /bin/bash
OFS:指定输出到屏幕后字段的分隔符
[root@zutuanxue ~]# awk 'BEGIN{FS=":";OFS="-"}NR==1{print $1,$3,$NF}' /etc/passwd
root-0-/bin/bash
RS:指定记录的分隔符
[root@zutuanxue ~]# awk 'BEGIN{RS=""}{print $1,$13,$25,$37,$49}' test
1 2 3 4 5
将记录的分隔符修改为空行后,所有的行会变成一行,所以所有字段就在一行了。
ORS:输出到屏幕后记录的分隔符,默认为回车
[root@zutuanxue ~]# awk 'BEGIN{RS="";ORS="*"}{print $1,$13,$25,$37,$49}' test
1 2 3 4 5*[root@zutuanxue ~]#
可以看出,提示符和输出在一行了,因为默认回车换成了*
5.4)流程控制
if判断语句
学习用例
[root@zutuanxue ~]# cat num
1
2
3
4
5
6
7
8
9
单if语句
打印$1大于5的行
[root@zutuanxue ~]# awk '{if($1>5)print $0}' num
6
7
8
9
if...else语句
假如$1大于5则除以2输出,否则乘以2输出
[root@zutuanxue ~]# awk '{if($1>5)print $1/2;else print $1*2}' num
2
4
6
8
10
3
3.5
4
4.5
for循环语句
学习用例
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
将一行中的数据都加起来 $1+$2+$3
[root@zutuanxue ~]# awk '{sum=0;for (i=1;i<4;i++){sum+=$i}print sum}' num2
210
190
210
如果看的不明白可以看下面格式
[root@zutuanxue ~]# awk '{
> sum=0
> for (i=1;i<4;i++) {
> sum+=$i
> }
> print sum
> }' num2
210
190
210
while循环语句–先判断后执行
学习用例
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
将文件中的每行的数值累加,和大于或等于150就停止累加
[root@zutuanxue ~]# awk '{sum=0;i=1;while(sum<150){sum+=$i;i++}print sum}' num2
210
150
170
如果看的不明白可以看下面格式
[root@zutuanxue ~]# awk '{
sum=0
i=1
while (sum<150) {
sum+=$i
i++
}
print sum
}' num2
210
150
170
do…while循环语句–先执行后判断
学习用例
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
将文件中的每行的数值累加,和大于或等于150就停止累加
[root@zutuanxue ~]# awk '{sum=0;i=1;do{sum+=$i;i++}while(sum<150);print sum}' num2
210
150
170
如果看的不明白可以看下面格式
[root@zutuanxue ~]# awk '{
> sum=0
> i=1
> do {
> sum+=$i
> i++
> }while (sum<150)
> print sum
> }' num2
210
150
170
循环控制语句
break 跳出循环,继续执行后续语句
学习用例
[root@zutuanxue ~]# cat num2
60 50 100
150 30 10
70 100 40
累加每行数值,和大于150停止累加
[root@zutuanxue ~]# awk '{
> sum=0
> i=1
> while (i<4){
> sum+=$i
> if (sum>150){
> break
> }
> i++
> }
> print sum
> }' num2
210
180
170

