scrapy源码分析
基于Scrapy 2.5.1版本
一、初出茅庐
1 架构总览
Scrapy的基础架构:
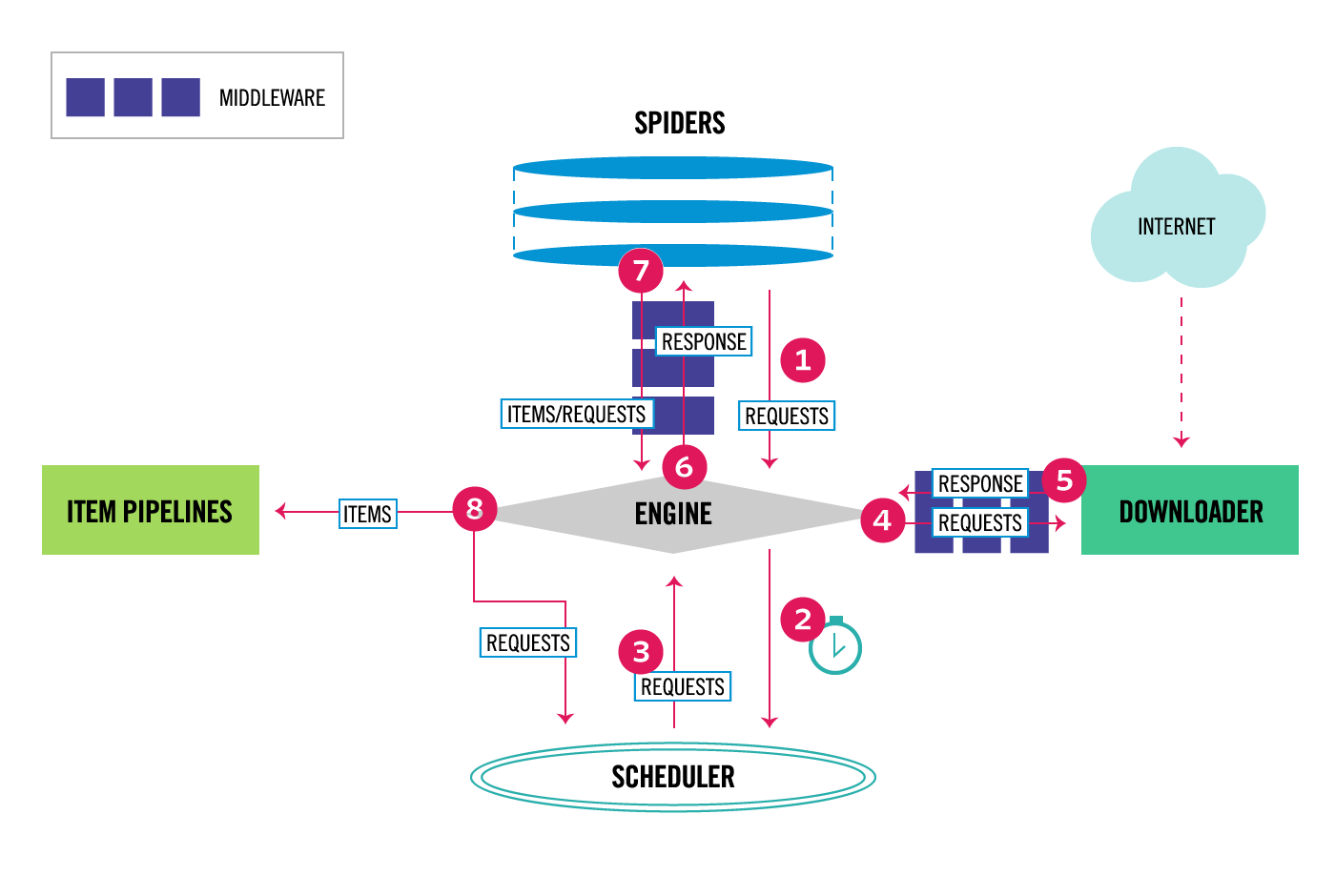
关于架构,很有趣的一点是在Scrapy文档里的问题:
Did Scrapy “steal” X from Django?
Probably, but we don’t like that word. We think Django is a great open source project and an example to follow, so we’ve used it as an inspiration for Scrapy.
We believe that, if something is already done well, there’s no need to reinvent it. This concept, besides being one of the foundations for open source and free software, not only applies to software but also to documentation, procedures, policies, etc. So, instead of going through each problem ourselves, we choose to copy ideas from those projects that have already solved them properly, and focus on the real problems we need to solve.
We’d be proud if Scrapy serves as an inspiration for other projects. Feel free to steal from us!
可以看到,Scrapy的架构很类似于Django,因此如果你了解Django,对于该架构应该更容易理解一些。在这里向这些开源作者们致敬!
二、似懂非懂
1 入口函数
无论是我们创建项目使用的命令
scrapy startproject 项目名
还是运行爬虫使用的命令
scrapy crawl 爬虫名
都需要使用scrapy,如果有linux基础,你应该知道usr/bin/或者usr/local/bin,它们存放了系统的可执行文件(命令)和用户安装的可执行文件(命令),而scrapy命令,就在后者目录中存放。不信?来用命令查看一下:
[root@control-plane ~]# which scrapy
/usr/local/bin/scrapy
打开它cat /usr/local/bin/scrapy,可以看到如下内容:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
# 为了统一windows等系统命令,将第一个参数scrapy的后缀字符替换成空字符串
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(execute())
2 执行流程
让我们想一下,当你运行了一条命令之后,程序会做什么事?首先肯定要获取你的参数,还要根据参数找到对应的函数,最后执行。运行scrapy后,这里的python脚本会获取用户输入参数,然后调用scrapy.cmdline中的execute函数,我们找到这个函数:
def execute(argv=None, settings=None):
# 获取命令行参数
if argv is None:
argv = sys.argv
# 获取settings配置参数
if settings is None:
settings = get_project_settings()
# set EDITOR from environment if available
try:
editor = os.environ['EDITOR']
except KeyError:
pass
else:
settings['EDITOR'] = editor
# 确认运行环境,检查配置文件scrapy.cfg是否存在
inproject = inside_project()
# 获取命令,以字典形式将所有的命令类输出
cmds = _get_commands_dict(settings, inproject)
# 从用户输入中解析要执行的是哪个命令
cmdname = _pop_command_name(argv)
parser = optparse.OptionParser(formatter=optparse.TitledHelpFormatter(),
conflict_handler='resolve')
if not cmdname:
_print_commands(settings, inproject)
sys.exit(0)
elif cmdname not in cmds:
_print_unknown_command(settings, cmdname, inproject)
sys.exit(2)
# 根据命令名称找到对应的命令类,以及命令的描述
cmd = cmds[cmdname]
parser.usage = f"scrapy {cmdname} {cmd.syntax()}"
parser.description = cmd.long_desc()
# 设置项目配置和级别为command
settings.setdict(cmd.default_settings, priority='command')
cmd.settings = settings
# 添加参数选项
cmd.add_options(parser)
# 解析参数选项,执行process_options解析参数
opts, args = parser.parse_args(args=argv[1:])
_run_print_help(parser, cmd.process_options, args, opts)
# 初始化CrawlerProcess对象,保存在crawler_process属性中
cmd.crawler_process = CrawlerProcess(settings)
# 执行cmd对象的run方法
_run_print_help(parser, _run_command, cmd, args, opts)
# 退出
sys.exit(cmd.exitcode)
不难看出,这里所做的就是整个函数的执行流程。也就是获取参数,初始化配置、参数解析、找到对应的函数,加载爬虫、运行爬虫,退出爬虫。接下来,就按照这个流程来阅读源码吧~
三、跃跃欲试
获取参数
这部分的内容很简单,就是获取用户输入参数。
获取settings配置
这一步是获取settings配置,首先调用了scrapy.utils.project.get_project_settings函数,内容如下:
def get_project_settings():
# 环境变量中是否有SCRAPY_SETTINGS_MODULE配置
if ENVVAR not in os.environ:
# project设置为SCRAPY_PROJECT对应的值,如果没有,就设置为default
project = os.environ.get('SCRAPY_PROJECT', 'default')
# 初始化环境变量
init_env(project)
# 初始化settings对象
settings = Settings()
# 获取用户配置文件
settings_module_path = os.environ.get(ENVVAR)
# 如果获取到配置文件,就调用setmodule方法
if settings_module_path:
settings.setmodule(settings_module_path, priority='project')
# 从环境变量获取以SCRAPY_开头的key与value,这些也是scrapy的相关配置,将key的SCRAPY_前缀去掉
scrapy_envvars = {k[7:]: v for k, v in os.environ.items() if
k.startswith('SCRAPY_')}
# 合法的key
valid_envvars = {
'CHECK',
'PROJECT',
'PYTHON_SHELL',
'SETTINGS_MODULE',
}
# 如果scrapy_envvars中的key名字不合法,发出警告
setting_envvars = {k for k in scrapy_envvars if k not in valid_envvars}
if setting_envvars:
setting_envvar_list = ', '.join(sorted(setting_envvars))
warnings.warn(
'Use of environment variables prefixed with SCRAPY_ to override '
'settings is deprecated. The following environment variables are '
f'currently defined: {setting_envvar_list}',
ScrapyDeprecationWarning
)
# 将配置保存到settings对象中(覆盖掉原来的配置)
settings.setdict(scrapy_envvars, priority='project')
return settings
os.environ是系统的环境变量字典:
environ({'XDG_SESSION_ID': '15', 'HOSTNAME': 'control-plane.minikube.internal', 'SELINUX_ROLE_REQUESTED': '', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'HISTSIZE': '1000', 'SSH_CLIENT': '192.168.142.3 49811 22', 'SELINUX_USE_CURRENT_RANGE': '', 'SSH_TTY': '/dev/pts/0', 'USER': 'root', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.axv=01;35:*.anx=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=01;36:*.au=01;36:*.flac=01;36:*.mid=01;36:*.midi=01;36:*.mka=01;36:*.mp3=01;36:*.mpc=01;36:*.ogg=01;36:*.ra=01;36:*.wav=01;36:*.axa=01;36:*.oga=01;36:*.spx=01;36:*.xspf=01;36:', 'MAIL': '/var/spool/mail/root', 'PATH': '/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/git/bin:/usr/local/nginx/sbin:/usr/local/nginx/sbin:/root/bin', 'PWD': '/root', 'LANG': 'zh_CN.UTF-8', 'SELINUX_LEVEL_REQUESTED': '', 'HISTCONTROL': 'ignoredups', 'SHLVL': '1', 'HOME': '/root', 'LOGNAME': 'root', 'SSH_CONNECTION': '192.168.142.3 49811 192.168.142.88 22', 'LESSOPEN': '||/usr/bin/lesspipe.sh %s', 'XDG_RUNTIME_DIR': '/run/user/0', '_': '/usr/bin/python3', 'OLDPWD': '/usr/local'})
接下来要关注的就是初始化系统变量函数init_env:
def init_env(project='default', set_syspath=True):
"""Initialize environment to use command-line tool from inside a project
dir. This sets the Scrapy settings module and modifies the Python path to
be able to locate the project module.
"""
# 获取到scrapy.cfg文件对象
cfg = get_config()
if cfg.has_option('settings', project):
# 从scrapy.cfg文件中获取[settings]对应的值
# 这个值就是settings.py的存放位置,将其保存在环境变量SCRAPY_SETTINGS_MODULE中
os.environ['SCRAPY_SETTINGS_MODULE'] = cfg.get('settings', project)
closest = closest_scrapy_cfg()
if closest:
projdir = os.path.dirname(closest)
if set_syspath and projdir not in sys.path:
sys.path.append(projdir)
def get_config(use_closest=True):
"""Get Scrapy config file as a ConfigParser"""
sources = get_sources(use_closest)
# 利用ConfigParser解析.cfg文件
cfg = ConfigParser()
cfg.read(sources)
return cfg
def get_sources(use_closest=True):
xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or os.path.expanduser('~/.config')
# os.path.expanduser可以将参数中开头部分的~或~user替换为当前用户的home目录并返回
# 在linux系统下,假设账号是root,这个用户的home目录是/root/,如果是普通用户,比如yyyz,这个用户的home目录是/home/root/
sources = [
'/etc/scrapy.cfg',
r'c:\scrapy\scrapy.cfg',
xdg_config_home + '/scrapy.cfg', # root用户下就是 /root/.config/scrapy.cfg
os.path.expanduser('~/.scrapy.cfg'), # root用户下就是/root/.scrapy.cfg
]
# sources列表存储了配置文件可能存放的这四个位置,
if use_closest:
# 返回最近的scrapy.cfg文件的路径
sources.append(closest_scrapy_cfg())
return sources
def closest_scrapy_cfg(path='.', prevpath=None):
# 从当前目录依次向上级目录递归查找配置文件scrapy.cfg的位置
if path == prevpath:
return ''
path = os.path.abspath(path)
cfgfile = os.path.join(path, 'scrapy.cfg')
if os.path.exists(cfgfile):
return cfgfile
return closest_scrapy_cfg(os.path.dirname(path), path)
接下来是生成settings对象,构造函数如下:
from scrapy.settings import default_settings
class BaseSettings(MutableMapping):
# 把它认为是一个字典,以K,V形式存储数据,其中多了冻结数据和设置优先级的功能
def __init__(self, values=None, priority='project'):
self.frozen = False
self.attributes = {}
if values:
self.update(values, priority)
def setmodule(self, module, priority='project'):
self._assert_mutability()
if isinstance(module, str):
module = import_module(module)
for key in dir(module):
if key.isupper():
# 把key为大写的配置保存
self.set(key, getattr(module, key), priority)
class Settings(BaseSettings):
def __init__(self, values=None, priority='project'):
# 调用父类的init方法
super().__init__()
# 把default_settings.py的内容保存到到settings对象中
self.setmodule(default_settings, 'default')
# 把其中嵌套字典的内容也设置进去
for name, val in self.items():
if isinstance(val, dict):
self.set(name, BaseSettings(val, 'default'), 'default')
self.update(values, priority)
在初始化settings对象时,会加载默认配置文件default_settings.py,这里配置了很多默认值以及使用的类,这些都是可插拔式的,如果你想扩展自定义类,都可以覆盖掉默认的类。
确认运行环境
初始化完配置之后,下面是确认运行环境。调用 inside_project 函数:
def inside_project():
# 检查上一步设置的环境变量是否存在
scrapy_module = os.environ.get('SCRAPY_SETTINGS_MODULE')
if scrapy_module is not None:
try:
# 尝试导入
import_module(scrapy_module)
except ImportError as exc:
warnings.warn(f"Cannot import scrapy settings module {scrapy_module}: {exc}")
else:
return True
# 调用closest_scrapy_cfg递归查找配置文件scrapy.cfg,如果找到就返回True
return bool(closest_scrapy_cfg())
只要能找到scrapy.cfg ,scrapy认为是在项目中执行的命令,而不是在其它地方执行的全局命令。
获取命令
接下来,就是获取命令了。调用_get_commands_dict函数:
def _get_commands_dict(settings, inproject):
# 导入commands目录下的所有模块
cmds = _get_commands_from_module('scrapy.commands', inproject)
cmds.update(_get_commands_from_entry_points(inproject))
# 从settings中加载COMMANDS_MODULE配置的命令类,这些类可以由用户自定义
cmds_module = settings['COMMANDS_MODULE']
if cmds_module:
cmds.update(_get_commands_from_module(cmds_module, inproject))
return cmds
def _get_commands_from_module(module, inproject):
d = {}
# 导入对应目录下的ScrapyCommand的所有子类
for cmd in _iter_command_classes(module):
if inproject or not cmd.requires_project:
# 以`.`分割,返回命令,比如'scrapy.commands.bench'的cmdname为'bench'
cmdname = cmd.__module__.split('.')[-1]
d[cmdname] = cmd()
return d
def _iter_command_classes(module_name):
# 导入模块和所有的子模块,遍历它们
for module in walk_modules(module_name):
# 遍历每个模块的属性值
for obj in vars(module).values():
if (
inspect.isclass(obj) # 如果这个对象是类
and issubclass(obj, ScrapyCommand) # 并且是ScrapyCommand的子类
and obj.__module__ == module.__name__ # 并且当前类所在模块和模块名一样
and not obj == ScrapyCommand # 并且不能是ScrapyCommand类
):
# 说明这个类是ScrapyCommand的子类,返回
yield obj
def walk_modules(path):
# 导入指定路径下的所有模块以及它们的子模块,比如:walk_modules('scrapy.utils')
mods = []
mod = import_module(path)
mods.append(mod)
if hasattr(mod, '__path__'):
for _, subpath, ispkg in iter_modules(mod.__path__):
fullpath = path + '.' + subpath
if ispkg:
mods += walk_modules(fullpath)
else:
submod = import_module(fullpath)
mods.append(submod)
return mods
最终返回的,就是scarpy.commands下面的命令类
解析命令
获取到所有的命令之后,接下来就是解析用户输入的命令:
def _pop_command_name(argv):
i = 0
for arg in argv[1:]:
if not arg.startswith('-'):
del argv[i]
return arg
i += 1
这个逻辑比较好理解,就是从argv参数中获取用户输入,比如输入的是:scrapy crawl xxx,那么就会获取到crawl返回。
利用optparse模块解析命令,并且添加参数选项。然后,调用 cmd.process_options 方法解析我们的参数:
class ScrapyCommand:
def process_options(self, args, opts):
try:
# 将命令行参数转化为字典
self.settings.setdict(arglist_to_dict(opts.set),
priority='cmdline')
except ValueError:
raise UsageError("Invalid -s value, use -s NAME=VALUE", print_help=False)
# 如果设置了对应的参数就将其配置到settings对象,优先级为cmdline
if opts.logfile:
self.settings.set('LOG_ENABLED', True, priority='cmdline')
self.settings.set('LOG_FILE', opts.logfile, priority='cmdline')
if opts.loglevel:
self.settings.set('LOG_ENABLED', True, priority='cmdline')
self.settings.set('LOG_LEVEL', opts.loglevel, priority='cmdline')
if opts.nolog:
self.settings.set('LOG_ENABLED', False, priority='cmdline')
if opts.pidfile:
with open(opts.pidfile, "w") as f:
f.write(str(os.getpid()) + os.linesep)
if opts.pdb:
failure.startDebugMode()
之后,初始化 CrawlerProcess 对象:
class CrawlerProcess(CrawlerRunner):
def __init__(self, settings=None, install_root_handler=True):
# 调用父类的构造方法
super().__init__(settings)
# 初始化信号以及日志
install_shutdown_handlers(self._signal_shutdown)
configure_logging(self.settings, install_root_handler)
log_scrapy_info(self.settings)
class CrawlerRunner:
def __init__(self, settings=None):
if isinstance(settings, dict) or settings is None:
# 如果settings是字典或者为空,新实例化一个settings
settings = Settings(settings)
self.settings = settings
# 获取爬虫加载器
self.spider_loader = self._get_spider_loader(settings)
self._crawlers = set()
self._active = set()
self.bootstrap_failed = False
self._handle_twisted_reactor()
@staticmethod
def _get_spider_loader(settings):
# 从settings中获取爬虫加载器,默认为:SPIDER_LOADER_CLASS = 'scrapy.spiderloader.SpiderLoader'
cls_path = settings.get('SPIDER_LOADER_CLASS')
loader_cls = load_object(cls_path)
excs = (DoesNotImplement, MultipleInvalid) if MultipleInvalid else DoesNotImplement
try:
verifyClass(ISpiderLoader, loader_cls)
except excs:
warnings.warn(
'SPIDER_LOADER_CLASS (previously named SPIDER_MANAGER_CLASS) does '
'not fully implement scrapy.interfaces.ISpiderLoader interface. '
'Please add all missing methods to avoid unexpected runtime errors.',
category=ScrapyDeprecationWarning, stacklevel=2
)
return loader_cls.from_settings(settings.frozencopy())
加载爬虫
在上面的_get_spider_loader的最后一句return loader_cls.from_settings(settings.frozencopy()),调用了SpiderLoader的类方法from_settings:
class SpiderLoader:
@classmethod
def from_settings(cls, settings):
# 初始化对象并返回SpiderLoader(settings)
return cls(settings)
在初始化方法中加载我们编写好的爬虫类:
@implementer(ISpiderLoader)
class SpiderLoader:
def __init__(self, settings):
# 从配置文件SPIDER_MODULES获取存放爬虫类的路径
self.spider_modules = settings.getlist('SPIDER_MODULES')
# SPIDER_LOADER_WARN_ONLY:如果导入爬虫类失败,是否只发出警告
self.warn_only = settings.getbool('SPIDER_LOADER_WARN_ONLY')
self._spiders = {}
self._found = defaultdict(list)
# 调用_load_all_spiders加载所有爬虫类
self._load_all_spiders()
def _load_spiders(self, module):
for spcls in iter_spider_classes(module):
# 爬虫的模块名和类名
self._found[spcls.name].append((module.__name__, spcls.__name__))
# 组装成{spider_name: spider_cls}的字典
self._spiders[spcls.name] = spcls
def _load_all_spiders(self):
for name in self.spider_modules:
try:
# 导入所有的爬虫
for module in walk_modules(name):
self._load_spiders(module)
except ImportError:
# 导入失败
if self.warn_only:
warnings.warn(
f"\n{traceback.format_exc()}Could not load spiders "
f"from module '{name}'. "
"See above traceback for details.",
category=RuntimeWarning,
)
else:
raise
# 检查是否重名
self._check_name_duplicates()
运行爬虫
之后会执行对应命令类的run方法,而使用命令行运行爬虫,使用的命令为 scrapy crawl xxxx,即调用 crawl.py 里的 run 方法:
class Command(BaseRunSpiderCommand):
def run(self, args, opts):
if len(args) < 1:
raise UsageError()
elif len(args) > 1:
raise UsageError("running 'scrapy crawl' with more than one spider is not supported")
spname = args[0]
# 调用CrawlerProcess父类CrawlerRunner的crawl方法
crawl_defer = self.crawler_process.crawl(spname, **opts.spargs)
if getattr(crawl_defer, 'result', None) is not None and issubclass(crawl_defer.result.type, Exception):
# 如果发生错误,退出码为1
self.exitcode = 1
else:
# 调用CrawlerProcess的start方法
self.crawler_process.start()
if (
self.crawler_process.bootstrap_failed
or hasattr(self.crawler_process, 'has_exception') and self.crawler_process.has_exception
):
# 如果发生错误,退出码为1
self.exitcode = 1
class CrawlerRunner:
def crawl(self, crawler_or_spidercls, *args, **kwargs):
# 类型检查
if isinstance(crawler_or_spidercls, Spider):
raise ValueError(
'The crawler_or_spidercls argument cannot be a spider object, '
'it must be a spider class (or a Crawler object)')
# 创建crawler
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def create_crawler(self, crawler_or_spidercls):
if isinstance(crawler_or_spidercls, Spider):
# 如果是Spider对象返回错误
raise ValueError(
'The crawler_or_spidercls argument cannot be a spider object, '
'it must be a spider class (or a Crawler object)')
if isinstance(crawler_or_spidercls, Crawler):
# 如果是Crawler对象,直接返回它本身
return crawler_or_spidercls
# 否则,调用_create_crawler
return self._create_crawler(crawler_or_spidercls)
def _create_crawler(self, spidercls):
# 判断是否为字符串类型
if isinstance(spidercls, str):
# 从spider_loader中加载这个爬虫类
spidercls = self.spider_loader.load(spidercls)
# 不是字符串,实例化Crawler对象
return Crawler(spidercls, self.settings)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
# 调用Crawler的crawl方法
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
self.bootstrap_failed |= not getattr(crawler, 'spider', None)
return result
return d.addBoth(_done)
到最终会创建 Cralwer 对象,调用它的 crawl 方法:
class Crawler:
def __init__(self, spidercls, settings=None):
if isinstance(spidercls, Spider):
raise ValueError('The spidercls argument must be a class, not an object')
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.spidercls = spidercls # 最终我们的爬虫类会加载到这里
self.settings = settings.copy() # 配置文件的拷贝
self.spidercls.update_settings(self.settings)
self.signals = SignalManager(self) # 信号
self.stats = load_object(self.settings['STATS_CLASS'])(self)
handler = LogCounterHandler(self, level=self.settings.get('LOG_LEVEL'))
logging.root.addHandler(handler)
d = dict(overridden_settings(self.settings))
logger.info("Overridden settings:\n%(settings)s",
{'settings': pprint.pformat(d)})
if get_scrapy_root_handler() is not None:
install_scrapy_root_handler(self.settings)
self.__remove_handler = lambda: logging.root.removeHandler(handler)
self.signals.connect(self.__remove_handler, signals.engine_stopped)
lf_cls = load_object(self.settings['LOG_FORMATTER'])
self.logformatter = lf_cls.from_crawler(self)
self.extensions = ExtensionManager.from_crawler(self)
self.settings.freeze()
self.crawling = False
self.spider = None
self.engine = None
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
if self.crawling:
raise RuntimeError("Crawling already taking place")
self.crawling = True
try:
# 调用_create_spider
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法,生成迭代器
start_requests = iter(self.spider.start_requests())
# 执行engine的open_spider方法,传入spider对象和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise
def _create_spider(self, *args, **kwargs):
# 调用from_crawler,这里的self是Crawler对象,作为第二个参数传递给爬虫类的类方法from_crawler
return self.spidercls.from_crawler(self, *args, **kwargs)
class Spider(object_ref):
name: Optional[str] = None
custom_settings: Optional[dict] = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError(f"{type(self).__name__} must have a name")
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
# 如果没有start_urls,默认为空列表
self.start_urls = []
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
# 在这里真正实例化spider对象,cls就是我们创建的spider类
spider = cls(*args, **kwargs)
# 设置相关属性
spider._set_crawler(crawler)
return spider
def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
全部初始化之后,会调用CrawlerProcess的start方法:
class CrawlerProcess(CrawlerRunner):
def start(self, stop_after_crawl=True):
# 通过'REACTOR_THREADPOOL_MAXSIZE'调整线程池,通过`DNSCACHE_ENABLED`启用内存缓存DNS
# 通过'DNSCACHE_SIZE'设置缓存大小
# 在默认情况下stop_after_crawl默认为True,reactor会在所有爬虫结束后停止
from twisted.internet import reactor
# 这里的多线程是调用twisted实现的
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
resolver_class = load_object(self.settings["DNS_RESOLVER"])
resolver = create_instance(resolver_class, self.settings, self, reactor=reactor)
resolver.install_on_reactor()
# 配置线程池
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
# 调用reactor的run方法开始执行
reactor.run(installSignalHandlers=False) # 阻塞调用
关于Twisted,以后有时间单独写文章介绍,这里只需要知道scrapy是通过twisted实现并发即可。
退出
这部分也很简单,当所有的spider结束后,获取exitcode,退出执行。
了解scrapy的运行流程后,让我们重新回到架构图上,分别来看看每个组件的源码实现。
四、豁然开朗
引擎
在上一章中运行爬虫这一节,调用 crawl.py 里的 run 方法后,最终会创建 Cralwer 对象,调用它的 crawl 方法。
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
if self.crawling:
raise RuntimeError("Crawling already taking place")
self.crawling = True
try:
# 调用_create_spider
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法,生成迭代器
start_requests = iter(self.spider.start_requests())
# 执行engine的open_spider方法,传入spider对象和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise
在这个方法中,实例化spider对象,然后就通过self._create_engine()创建了引擎,我们从这里出发,看看引擎是怎么创建的:
class Crawler:
def _create_engine(self):
# self是Crawler对象
return ExecutionEngine(self, lambda _: self.stop())
可以看到调用init方法初始化ExecutionEngine对象。
class ExecutionEngine:
def __init__(self, crawler, spider_closed_callback):
self.crawler = crawler # 保存crawler
self.settings = crawler.settings # 保存settings
self.signals = crawler.signals # 信号
self.logformatter = crawler.logformatter # 日志
# 状态设置
self.slot = None
self.spider = None
self.running = False
self.paused = False
# 从配置中查找SCHEDULER调度器,默认为scrapy.core.scheduler.Scheduler
self.scheduler_cls = load_object(self.settings['SCHEDULER'])
# 从配置中查找DOWNLOADER下载器,默认为scrapy.core.downloader.Downloader
downloader_cls = load_object(self.settings['DOWNLOADER'])
# 实例化downloader下载器对象
self.downloader = downloader_cls(crawler)
# 实例化scraper对象
self.scraper = Scraper(crawler)
self._spider_closed_callback = spider_closed_callback
这个初始化方法中,将一些核心参数定义在引擎中,包括settings、日志、crawler、下载器类、调度器类等等,还初始化了下载器对象和scraper对象,但在这里并没有初始化调度器对象。无论是源码,还是在第一章的架构图中,都能很清晰地看出引擎就是整个scrapy运行的核心组件,它负责连接其它所有组件。
下载器的初始化
首先来看看下载器的初始化:
class Downloader:
DOWNLOAD_SLOT = 'download_slot'
def __init__(self, crawler):
self.settings = crawler.settings # 同样把settings保存在下载器中
self.signals = crawler.signals # 保存信号
self.slots = {} # 插槽
self.active = set()
# DownloadHandlers类的初始化
self.handlers = DownloadHandlers(crawler)
# 在settings中获取总的并发数限制
self.total_concurrency = self.settings.getint('CONCURRENT_REQUESTS')
# 在settings中获取同一域名并发数限制
self.domain_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_DOMAIN')
# 在settings中获取同一IP并发数限制
self.ip_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_IP')
# 在settings中获取是否启用随机延迟下载时间
self.randomize_delay = self.settings.getbool('RANDOMIZE_DOWNLOAD_DELAY')
# 初始化下载器中间件
self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
self._slot_gc_loop = task.LoopingCall(self._slot_gc)
self._slot_gc_loop.start(60)
其中最重要的就是DownloadHandlers类的初始化和下载器中间件的初始化。
下载器处理器初始化
首先看看 DownloadHandlers:
class DownloadHandlers:
def __init__(self, crawler):
self._crawler = crawler
self._schemes = {} # stores acceptable schemes on instancing 用于保存下载处理器的类
self._handlers = {} # stores instanced handlers for schemes 用于保存下载处理器类实例化之后的对象
self._notconfigured = {} # remembers failed handlers 保存失败的handlers
# 调用getwithbase方法,从settings中获取DOWNLOAD_HANDLERS_BASE
handlers = without_none_values(
crawler.settings.getwithbase('DOWNLOAD_HANDLERS'))
# 循环加载
for scheme, clspath in handlers.items():
# 将下载器类名字和路径保存在self._schemes
self._schemes[scheme] = clspath
# 调用_load_handler
self._load_handler(scheme, skip_lazy=True)
crawler.signals.connect(self._close, signals.engine_stopped)
def _load_handler(self, scheme, skip_lazy=False):
# 获取下载器处理的名字对应的路径
path = self._schemes[scheme]
try:
# dhcls即downloadhandlerclass的简写
dhcls = load_object(path)
# 获取类中定义的lazy属性值,如果与skip_lazy同样为True就不初始化,否则就初始化
if skip_lazy and getattr(dhcls, 'lazy', True):
return None
# 创建downloadhandler对象
dh = create_instance(
objcls=dhcls,
settings=self._crawler.settings,
crawler=self._crawler,
)
except NotConfigured as ex:
self._notconfigured[scheme] = str(ex)
return None
except Exception as ex:
logger.error('Loading "%(clspath)s" for scheme "%(scheme)s"',
{"clspath": path, "scheme": scheme},
exc_info=True, extra={'crawler': self._crawler})
self._notconfigured[scheme] = str(ex)
return None
else:
# 没出异常,就将downloadhandler对象保存在_handlers中
self._handlers[scheme] = dh
return dh
那么,具体都有哪些下载器处理器呢?在默认的配置文件中是这样的:
DOWNLOAD_HANDLERS_BASE = {
'data': 'scrapy.core.downloader.handlers.datauri.DataURIDownloadHandler',
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
见名知意,这些下载处理器会根据请求的资源类型,使用对应的下载器去下载。一般会使用的是http和https
下载器中间件初始化
下面看看下载器中间件的初始化,由DownloaderMiddlewareManager调用父类MiddlewareManager的类方法from_crawler:
class MiddlewareManager:
# 它是所有中间件的父类
@classmethod
def from_crawler(cls, crawler):
# cls是DownloaderMiddlewareManager类
# 由于没有定义from_settings,所以cls调用父类(也就是MiddlewareManager)的from_settings
return cls.from_settings(crawler.settings, crawler)
@classmethod
def from_settings(cls, settings, crawler=None):
# cls是DownloaderMiddlewareManager类
# 调用DownloaderMiddlewareManager的_get_mwlist_from_settings方法,获得下载器中间件的顺序列表
mwlist = cls._get_mwlist_from_settings(settings)
middlewares = []
enabled = []
# 遍历mwlist
for clspath in mwlist:
try:
# 根据路径,获得中间件类
mwcls = load_object(clspath)
# 实例化中间件
mw = create_instance(mwcls, settings, crawler)
# 添加到middlewares列表中
middlewares.append(mw)
# 添加到启用列表中
enabled.append(clspath)
except NotConfigured as e:
if e.args:
clsname = clspath.split('.')[-1]
logger.warning("Disabled %(clsname)s: %(eargs)s",
{'clsname': clsname, 'eargs': e.args[0]},
extra={'crawler': crawler})
logger.info("Enabled %(componentname)ss:\n%(enabledlist)s",
{'componentname': cls.component_name,
'enabledlist': pprint.pformat(enabled)},
extra={'crawler': crawler})
# 调用DownloaderMiddlewareManager的初始化方法
# 由于自己没有定义,所以调用父类MiddlewareManager的init方法
return cls(*middlewares)
def __init__(self, *middlewares):
self.middlewares = middlewares
# 定义中间件方法,其中defaultdict和deque都是collections模块的数据结构
# defaultdict是一个拥有默认值的字典,deque是一个双端队列
self.methods = defaultdict(deque)
for mw in middlewares:
# 循环添加mw,调用_add_middleware,这里调用的是DownloaderMiddlewareManager的_add_middleware方法
self._add_middleware(mw)
def _add_middleware(self, mw):
# 注意,下载器中间件不走这个方法,这里列出来主要是与其它中间件的_add_middleware进行对比
if hasattr(mw, 'open_spider'):
# 如果中间件中定义了open_spider方法,就将其加入到methods中,从右入队
self.methods['open_spider'].append(mw.open_spider)
if hasattr(mw, 'close_spider'):
# 如果中间件中定义了close_spider方法,就将其加入到methods中,从左入队
self.methods['close_spider'].appendleft(mw.close_spider)
class DownloaderMiddlewareManager(MiddlewareManager):
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 调用getwithbase方法从settings中获取所有的DOWNLOADER_MIDDLEWARES_BASE
# 然后通过build_component_list将字典{ class: order }排序后组装成list并返回
return build_component_list(
settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
def _add_middleware(self, mw):
# 下载器中间件会调用这个方法,分别定义了下载前,下载后,发生异常时的方法
if hasattr(mw, 'process_request'):
# 如果中间件中定义了process_request方法,就将其加入到methods中,从右入队
self.methods['process_request'].append(mw.process_request)
if hasattr(mw, 'process_response'):
# 如果中间件中定义了process_response方法,就将其加入到methods中,从左入队
self.methods['process_response'].appendleft(mw.process_response)
if hasattr(mw, 'process_exception'):
# 如果中间件中定义了process_exception方法,就将其加入到methods中,从左入队
self.methods['process_exception'].appendleft(mw.process_exception)
默认的下载器中间件有这些:
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}
Scraper的初始化
Scraper是什么,之前好像没听说过?带着这个问题,先来看看Scraper的初始化:
class Scraper:
def __init__(self, crawler):
self.slot = None
# 初始化spidermiddleware爬虫中间件
self.spidermw = SpiderMiddlewareManager.from_crawler(crawler)
# 从配置文件中获取ITEM_PROCESSOR处理器类
# 默认的ITEM_PROCESSOR = 'scrapy.pipelines.ItemPipelineManager'
itemproc_cls = load_object(crawler.settings['ITEM_PROCESSOR'])
# 初始化ITEM_PROCESSOR对象
self.itemproc = itemproc_cls.from_crawler(crawler)
# 从配置文件中获取同时处理item的个数,默认为100
self.concurrent_items = crawler.settings.getint('CONCURRENT_ITEMS')
self.crawler = crawler
self.signals = crawler.signals
self.logformatter = crawler.logformatter
首先它调用了 SpiderMiddlewareManager,整个过程和下载器中间件的初始化基本一样,有了之前分析的经验,下面的分析也就不难了,这里给出它初始化的过程:
class SpiderMiddlewareManager(MiddlewareManager):
@classmethod
def _get_mwlist_from_settings(cls, settings):
return build_component_list(settings.getwithbase('SPIDER_MIDDLEWARES'))
def _add_middleware(self, mw):
# 调用父类的_add_middleware方法
super()._add_middleware(mw)
# 定义爬虫中间件的方法
if hasattr(mw, 'process_spider_input'):
self.methods['process_spider_input'].append(mw.process_spider_input)
if hasattr(mw, 'process_start_requests'):
self.methods['process_start_requests'].appendleft(mw.process_start_requests)
process_spider_output = getattr(mw, 'process_spider_output', None)
self.methods['process_spider_output'].appendleft(process_spider_output)
process_spider_exception = getattr(mw, 'process_spider_exception', None)
self.methods['process_spider_exception'].appendleft(process_spider_exception)
默认的爬虫中间件有:
SPIDER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50, # 对http非200响应进行处理
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500, # 不访问非domain定义的域名
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700, # 添加Referer
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800, # 过滤出URL长度超过URLLENGTH_LIMIT的request
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900, # 用来限制爬取深度
# Spider side
}
爬虫中间件初始化后,会进行ItemPipelineManager类的初始化,也就是管道的初始化,它同样继承MiddlewareManager父类,因此和前面的中间件初始化大同小异:
class ItemPipelineManager(MiddlewareManager):
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 获取默认的管道
return build_component_list(settings.getwithbase('ITEM_PIPELINES')) # 默认的管道为空
def _add_middleware(self, pipe):
super(ItemPipelineManager, self)._add_middleware(pipe)
if hasattr(pipe, 'process_item'):
# 如果定义了process_item就添加方法
self.methods['process_item'].append(deferred_f_from_coro_f(pipe.process_item))
def process_item(self, item, spider):
# 按顺序调用所有子类的process_item方法
return self._process_chain('process_item', item, spider)
可以看出,Scraper初始化了爬虫中间件和管道,以及一些其它参数,可以认为它的作用就是控制爬虫与管道之间的数据传输。
调度器的初始化
刚才提到,在引擎初始化时,并没有初始化调度器,那么它在什么时候初始化呢?回到运行爬虫这一节:创建Cralwer 对象,调用它的 crawl 方法这里,在引擎初始化完毕后,会执行yield self.engine.open_spider(self.spider, start_requests),即调用了引擎的open_spider方法:
class ExecutionEngine:
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
if not self.has_capacity():
raise RuntimeError(f"No free spider slot when opening {spider.name!r}")
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request, spider)
# 这里进行调度器的初始化
scheduler = self.scheduler_cls.from_crawler(self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
slot.nextcall.schedule()
slot.heartbeat.start(5)
主要来关注调度器的初始化,这里首先调用类方法from_crawler:
class Scheduler:
@classmethod
def from_crawler(cls, crawler):
# cls是Scheduler类
# 获取settings配置
settings = crawler.settings
# 从配置文件中获取DUPEFILTER_CLASS,去重类
dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
# 创建去重类对象
dupefilter = create_instance(dupefilter_cls, settings, crawler)
# 获取优先级队列类
pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
# 获取磁盘队列类
dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
# 获取内存队列类
mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
# 是否记录调度器的调试信息
logunser = settings.getbool('SCHEDULER_DEBUG')
# 调用初始化方法,传入参数,其中jobdir用于获取暂停/恢复爬虫的目录
return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser,
stats=crawler.stats, pqclass=pqclass, dqclass=dqclass,
mqclass=mqclass, crawler=crawler)
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None, crawler=None):
# 将参数依次保存
self.df = dupefilter
self.dqdir = self._dqdir(jobdir)
self.pqclass = pqclass
self.dqclass = dqclass
self.mqclass = mqclass
self.logunser = logunser
self.stats = stats
self.crawler = crawler
调度器首先初始化一个去重类,然后定义了三个任务队列类:优先级队列类,磁盘队列类,内存队列类,但并没有初始化这三个类,只是进行了去重类的初始化。默认DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter',看看这个去重类的初始化:
class RFPDupeFilter(BaseDupeFilter):
# RFP指的是:request fingerprint,即请求指纹
def __init__(self, path=None, debug=False):
self.file = None
# 内部使用set()
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
# 如果传入path,可以保存在文件中,下次也可以使用
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
三种任务队列类默认为:
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue'
SCHEDULER_PRIORITY_QUEUE = 'scrapy.pqueues.ScrapyPriorityQueue'
这里比较奇怪的是,磁盘队列和内存队列都是LIFO,明明是栈的特性,却偏要叫成队列。其实可以修改这些默认值,将其变为FIFO的队列,在scrapy.squeues.py文件中,可以看到许多队列的定义,你可以为调度器选择FIFO的队列:
# 使用Pickle序列化的先入先出磁盘队列
PickleFifoDiskQueue = _scrapy_serialization_queue(
PickleFifoDiskQueueNonRequest
)
# 使用Pickle序列化的后入先出磁盘队列
PickleLifoDiskQueue = _scrapy_serialization_queue(
PickleLifoDiskQueueNonRequest
)
# 使用Marshal序列化的先入先出磁盘队列
MarshalFifoDiskQueue = _scrapy_serialization_queue(
MarshalFifoDiskQueueNonRequest
)
# 使用Marshal序列化的后入先出磁盘队列
MarshalLifoDiskQueue = _scrapy_serialization_queue(
MarshalLifoDiskQueueNonRequest
)
# 先入先出内存队列
FifoMemoryQueue = _scrapy_non_serialization_queue(queue.FifoMemoryQueue)
# 后入先出内存队列
LifoMemoryQueue = _scrapy_non_serialization_queue(queue.LifoMemoryQueue)
五、游刃有余
下面我们来看看整个的调度过程,还是回到运行爬虫这里:
class Crawler:
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
if self.crawling:
raise RuntimeError("Crawling already taking place")
self.crawling = True
try:
# 调用_create_spider
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法,生成迭代器
start_requests = iter(self.spider.start_requests())
# 执行engine的open_spider方法,传入spider对象和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise
构建请求
创建 Cralwer 对象,调用它的 crawl 方法时,会执行这一句start_requests = iter(self.spider.start_requests())即调用了 spider 对象的 start_requests 方法,这就是我们在项目中定义的spider继承的父类里的方法:
class Spider(object_ref):
def start_requests(self):
# 获取类
cls = self.__class__
# 判断是不是将start_url少写了s
if not self.start_urls and hasattr(self, 'start_url'):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)")
# make_requests_from_url是弃用方法
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead "
f"(see {cls.__module__}.{cls.__name__}).",
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
# 依次实例化
yield Request(url, dont_filter=True)
这里,就会将我们在spider中定义的start_urls列表遍历,并实例化Request对象:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
# 编码方式
self._encoding = encoding # this one has to be set first
# 请求方法
self.method = str(method).upper()
# 处理url的合法性,并设置url
self._set_url(url)
# 设置body
self._set_body(body)
# priority必须是int类型
if not isinstance(priority, int):
raise TypeError(f"Request priority not an integer: {priority!r}")
# 设置priority优先级
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError(f'callback must be a callable, got {type(callback).__name__}')
if errback is not None and not callable(errback):
raise TypeError(f'errback must be a callable, got {type(errback).__name__}')
# 分别设置正确回调和错误回调
self.callback = callback
self.errback = errback
# 设置cookies
self.cookies = cookies or {}
# 设置headers
self.headers = Headers(headers or {}, encoding=encoding)
# 是否过滤请求
self.dont_filter = dont_filter
# meta信息
self._meta = dict(meta) if meta else None
# 回调函数的参数
self._cb_kwargs = dict(cb_kwargs) if cb_kwargs else None
# 标志
self.flags = [] if flags is None else list(flags)
这样就完成了初始请求的构建。
调度请求
在引擎初始化完毕后,会执行yield self.engine.open_spider(self.spider, start_requests),即调用了引擎的open_spider方法:
class ExecutionEngine:
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
if not self.has_capacity():
raise RuntimeError(f"No free spider slot when opening {spider.name!r}")
logger.info("Spider opened", extra={'spider': spider})
# 将self._next_request函数封装
nextcall = CallLaterOnce(self._next_request, spider)
# 这里进行调度器的初始化
scheduler = self.scheduler_cls.from_crawler(self.crawler)
# 调用self.scraper.spidermw,也就是爬虫中间件的process_start_requests方法对初始url进行处理
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
# 初始化Slot对象
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
# 调用scheduler的open方法
yield scheduler.open(spider)
# 调用scraper的open方法
yield self.scraper.open_spider(spider)
# crawler的stats是数据收集器,默认为scrapy.statscollectors.MemoryStatsCollector
self.crawler.stats.open_spider(spider)
# 发送信号
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
# 开始调度
slot.nextcall.schedule()
# 每5秒钟执行一次CallLaterOnce.schedule方法,最终执行CallLaterOnce.__call__方法
slot.heartbeat.start(5)
CallLaterOnce初始化
这里首先是CallLaterOnce封装:
class CallLaterOnce:
# 安排一个运行过的函数在下一个reactor循环中被调用
def __init__(self, func, *a, **kw):
self._func = func # 这里的func就是self._next_request
self._a = a
self._kw = kw
self._call = None
调度器初始化
接下来是调度器初始化(在第四章已经介绍)。
初始url处理
然后是调用爬虫中间件的process_start_requests方法:
class SpiderMiddlewareManager(MiddlewareManager):
def process_start_requests(self, start_requests, spider):
# start_requests就是初始url,spider是我们写的爬虫对象
return self._process_chain('process_start_requests', start_requests, spider)
class MiddlewareManager:
def _process_chain(self, methodname, obj, *args):
# methodname='process_start_requests'
# obj=start_requests
# args=spider
return process_chain(self.methods[methodname], obj, *args)
# from scrapy.utils.defer import process_chain
def process_chain(callbacks, input, *a, **kw):
# 生成deferred对象
d = defer.Deferred()
for x in callbacks:
d.addCallback(x, *a, **kw)
# input=start_requests
d.callback(input)
return d
Slot初始化
之后是Slot对象的初始化:
class Slot:
def __init__(self, start_requests, close_if_idle, nextcall, scheduler):
self.closing = False
self.inprogress = set() # requests in progress
self.start_requests = iter(start_requests)
self.close_if_idle = close_if_idle
self.nextcall = nextcall
self.scheduler = scheduler
# nextcall就是CallLaterOnce对象,注册它的schedule方法
self.heartbeat = task.LoopingCall(nextcall.schedule)
class CallLaterOnce:
def schedule(self, delay=0):
from twisted.internet import reactor
if self._call is None:
self._call = reactor.callLater(delay, self)
schedule方法并不会立即执行,而只是注册到self.heartbeat属性中。
调用各种open方法
之后是调用scheduler的open方法:
class Scheduler:
def open(self, spider):
self.spider = spider
# 创建一个内存优先级队列
self.mqs = self._mq()
# 创建一个磁盘优先级队列(如果配置了dqdir就使用磁盘队列,默认None)
self.dqs = self._dq() if self.dqdir else None
# 调用去重对象(请求指纹过滤器)的open方法,这个方法在父类BaseDupeFilter中
return self.df.open()
class BaseDupeFilter:
def open(self): # can return deferred
# 默认没有做事情,可以手动重写该方法
pass
之后调用 Scraper 的 open_spider 方法:
class Scraper:
@defer.inlineCallbacks
def open_spider(self, spider):
# 初始化Slot对象,SCRAPER_SLOT_MAX_ACTIVE_SIZE默认为5000000
self.slot = Slot(self.crawler.settings.getint('SCRAPER_SLOT_MAX_ACTIVE_SIZE'))
# itemproc是scrapy.pipelines.ItemPipelineManager类的对象,调用它的open_spider方法
# 也就是调用每个管道的open_spider方法
yield self.itemproc.open_spider(spider)
接下来,还进行了数据收集器的open和发送信号操作。
开始调度
最后,开始调度,首先执行slot.nextcall.schedule(),
# slot.nextcall是CallLaterOnce对象
class CallLaterOnce:
def schedule(self, delay=0):
from twisted.internet import reactor
if self._call is None:
# 这里传入的是self,最终就会执行到类的__call__方法
# 这里并不是直接执行,而是通过reactor去调度,只不过delay延迟为0,所以就是立即执行了
self._call = reactor.callLater(delay, self)
def __call__(self):
self._call = None
# 在这里执行了`CallLaterOnce`初始化时注册的func
# 当时注册的func=self._next_request方法,self就是ExecutionEngine对象
return self._func(*self._a, **self._kw)
class ExecutionEngine:
def _next_request(self, spider):
slot = self.slot
# 如果没有slot
if not slot:
return
# 判断是否暂停
if self.paused:
return
# 只要_needs_backout返回False(运行良好),就一直循环
while not self._needs_backout(spider):
# 返回deferred对象或者None
if not self._next_request_from_scheduler(spider):
# 当第一次执行时,由于没有下一个请求,所以返回None,于是break跳出循环
# 如果没有下一个请求,就会break
break
# 如果start_requests有值,并且不需要等待
if slot.start_requests and not self._needs_backout(spider):
try:
# 从初始urls中获取请求
request = next(slot.start_requests)
except StopIteration:
slot.start_requests = None
except Exception:
slot.start_requests = None
logger.error('Error while obtaining start requests',
exc_info=True, extra={'spider': spider})
else:
# 调用crawl方法
self.crawl(request, spider)
# 如果spider空闲 (英文单词idle的意思是:无事可做的;懒惰的;闲置的)
# 并且如果设置了"空闲就关闭" (在open_spider的时候默认slot.close_if_idle=True)
if self.spider_is_idle(spider) and slot.close_if_idle:
# 调用_spider_idle,默认关闭spider
self._spider_idle(spider)
在开始调度里,有一些细节的实现,分别来看一看。
首先是_needs_backout方法:
class ExecutionEngine:
def _needs_backout(self, spider):
slot = self.slot
# 返回布尔类型
# 判断逻辑为:
# 引擎没有运行
# slot正在关闭
# 下载器个数超出预期(默认16)
# slot个数超出预期(5000000)
# 满足其中之一,就需要暂停(返回True)
return (
not self.running
or slot.closing
or self.downloader.needs_backout()
or self.scraper.slot.needs_backout()
)
从调度器获取下一个请求
然后是_next_request_from_scheduler:
class ExecutionEngine:
def _next_request_from_scheduler(self, spider):
slot = self.slot
# 从scheduler获取下一个request
request = slot.scheduler.next_request()
if not request:
# 没有请求就return
return
# 调用_download方法,调用下载器的方法,返回内联回调对象deferred
d = self._download(request, spider)
# 为deferred添加一系列回调链
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
# 返回deferred对象
return d
如上所述,第一次运行时,由于没有下一个请求,所以返回None,于是break跳出循环。然后执行到下面的self.crawl(request, spider):
class ExecutionEngine:
def crawl(self, request, spider):
if spider not in self.open_spiders:
raise RuntimeError(f"Spider {spider.name!r} not opened when crawling: {request}")
# 调用schedule方法
self.schedule(request, spider)
# 继续调用nextcall.schedule,到下一轮调度过程
self.slot.nextcall.schedule()
def schedule(self, request, spider):
# 发送信号
self.signals.send_catch_log(signals.request_scheduled, request=request, spider=spider)
# 将请求入队
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signals.request_dropped, request=request, spider=spider)
请求入队
请求入队的过程如下:
class Scheduler:
def enqueue_request(self, request):
# 如果没有开启request.dont_filter=True,并且是重复的请求就返回False
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
# 检查磁盘队列是否入队成功(如果没有使用磁盘队列就为None)
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 内存入队
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
# 返回True
return True
这里如果没有开启dont_filter=True参数,则会检查url是否重复:
class RFPDupeFilter(BaseDupeFilter):
def request_seen(self, request):
# 获得指纹
fp = self.request_fingerprint(request)
# 判断这个指纹在不在已有的指纹集合中
if fp in self.fingerprints:
return True
# 如果不在,就把这个指纹添加进去
self.fingerprints.add(fp)
# 如果有填写了文件路径就把指纹保存到文件中
if self.file:
self.file.write(fp + '\n')
def request_fingerprint(self, request):
# 调用了指纹生成器
return request_fingerprint(request)
生成指纹的过程如下:
def request_fingerprint(
request: Request,
include_headers: Optional[Iterable[Union[bytes, str]]] = None,
keep_fragments: bool = False,
):
"""
Return the request fingerprint.
The request fingerprint is a hash that uniquely identifies the resource the
request points to. For example, take the following two urls:
http://www.example.com/query?id=111&cat=222
http://www.example.com/query?cat=222&id=111
Even though those are two different URLs both point to the same resource
and are equivalent (i.e. they should return the same response).
Another example are cookies used to store session ids. Suppose the
following page is only accessible to authenticated users:
http://www.example.com/members/offers.html
Lot of sites use a cookie to store the session id, which adds a random
component to the HTTP Request and thus should be ignored when calculating
the fingerprint.
For this reason, request headers are ignored by default when calculating
the fingeprint. If you want to include specific headers use the
include_headers argument, which is a list of Request headers to include.
Also, servers usually ignore fragments in urls when handling requests,
so they are also ignored by default when calculating the fingerprint.
If you want to include them, set the keep_fragments argument to True
(for instance when handling requests with a headless browser).
"""
headers: Optional[Tuple[bytes, ...]] = None
if include_headers:
headers = tuple(to_bytes(h.lower()) for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
cache_key = (headers, keep_fragments)
if cache_key not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url, keep_fragments=keep_fragments)))
fp.update(request.body or b'')
if headers:
for hdr in headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[cache_key] = fp.hexdigest()
return cache[cache_key]
这里使用的是sha1算法生成指纹,在注释中也给了一个例子:
http://www.example.com/query?id=111&cat=222
http://www.example.com/query?cat=222&id=111
这两个请求只是参数位置不同,因此被算作同一个请求。
_download
在从调度器获取下一个请求中,如果不是第一次请求,应该会调用到_download方法:
class ExecutionEngine:
def _download(self, request, spider):
slot = self.slot
# 添加请求
slot.add_request(request)
# 定义下载成功的回调函数
def _on_success(response):
# 如果不是Response或者Request对象则异常
if not isinstance(response, (Response, Request)):
raise TypeError(
"Incorrect type: expected Response or Request, got "
f"{type(response)}: {response!r}"
)
# 如果是Response对象就返回Response
if isinstance(response, Response):
if response.request is None:
response.request = request
logkws = self.logformatter.crawled(response.request, response, spider)
if logkws is not None:
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
self.signals.send_catch_log(
signal=signals.response_received,
response=response,
request=response.request,
spider=spider,
)
return response
def _on_complete(_):
# 下载完成的回调函数,即进行下一次的调度
slot.nextcall.schedule()
return _
# 调用Downloader.fetch
dwld = self.downloader.fetch(request, spider)
# 添加回调
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld
看看Downloader.fetch方法:
class Downloader:
def fetch(self, request, spider):
def _deactivate(response):
# 在这里把该请求的active状态删除
self.active.remove(request)
return response
# 在下载之前,将请求添加在active集合中
self.active.add(request)
# 调用下载器中间件的download方法,下载成功的回调函数是self._enqueue_request
# 返回deferred对象
dfd = self.middleware.download(self._enqueue_request, request, spider)
# 添加_deactivate到正确和错误回调中
return dfd.addBoth(_deactivate)
这里比较复杂的是调用下载器中间件的方法,首先看这个方法:
class DownloaderMiddlewareManager(MiddlewareManager):
# 这里定义了三个回调函数
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# 从下载器中间件里获取process_request
for method in self.methods['process_request']:
# method(request=request, spider=spider) 在这里调用我们书写的process_request方法
response = yield deferred_from_coro(method(request=request, spider=spider))
if response is not None and not isinstance(response, (Response, Request)):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return None, Response or "
f"Request, got {response.__class__.__name__}"
)
if response:
return response
# download_func就是传过来的_enqueue_request方法
return (yield download_func(request=request, spider=spider))
@defer.inlineCallbacks
def process_response(response):
# 类型检测
if response is None:
raise TypeError("Received None in process_response")
elif isinstance(response, Request):
return response
# 从下载器中间件里获取process_response
for method in self.methods['process_response']:
response = yield deferred_from_coro(method(request=request, response=response, spider=spider))
if not isinstance(response, (Response, Request)):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return Response or Request, "
f"got {type(response)}"
)
if isinstance(response, Request):
return response
return response
@defer.inlineCallbacks
def process_exception(failure):
exception = failure.value
# 从下载器中间件里获取process_exception
for method in self.methods['process_exception']:
response = yield deferred_from_coro(method(request=request, exception=exception, spider=spider))
if response is not None and not isinstance(response, (Response, Request)):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return None, Response or "
f"Request, got {type(response)}"
)
if response:
return response
return failure
# 添加回调链
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred
首先循环所有的下载器中间件,下载前调用 process_request,然后调用Downloader的 _enqueue_request 方法:
class Downloader:
def _enqueue_request(self, request, spider):
key, slot = self._get_slot(request, spider)
request.meta[self.DOWNLOAD_SLOT] = key
def _deactivate(response):
# 定义回调函数
slot.active.remove(request)
return response
slot.active.add(request)
self.signals.send_catch_log(signal=signals.request_reached_downloader,
request=request,
spider=spider)
# 添加回调
deferred = defer.Deferred().addBoth(_deactivate)
# 添加到下载队列
slot.queue.append((request, deferred))
# 添加到处理队列
self._process_queue(spider, slot)
return deferred
def _process_queue(self, spider, slot):
from twisted.internet import reactor
if slot.latercall and slot.latercall.active():
return
# Delay queue processing if a download_delay is configured
# 延迟队列处理(如果配置了download_delay)
now = time()
# 生成一个延迟时间
delay = slot.download_delay()
if delay:
penalty = delay - now + slot.lastseen
if penalty > 0:
slot.latercall = reactor.callLater(penalty, self._process_queue, spider, slot)
return
# Process enqueued requests if there are free slots to transfer for this slot
# 如果有空闲的slots,处理入队请求
while slot.queue and slot.free_transfer_slots() > 0:
slot.lastseen = now
# 从下载队列中获取请求,以及deferred
request, deferred = slot.queue.popleft()
# 调用_download
dfd = self._download(slot, request, spider)
dfd.chainDeferred(deferred)
# prevent burst if inter-request delays were configured
if delay:
# 如果配置了延迟,重新调用
self._process_queue(spider, slot)
break
def _download(self, slot, request, spider):
# 创建下载deferred,将handlers.download_request注册
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
# 回调函数
def _downloaded(response):
self.signals.send_catch_log(signal=signals.response_downloaded,
response=response,
request=request,
spider=spider)
return response
dfd.addCallback(_downloaded)
# 将请求添加到transferring集合中
slot.transferring.add(request)
# 定义回调函数
def finish_transferring(_):
# 当响应到达的时候执行,从transferring集合中移除slot,使得这个slot可以被后面的请求使用
slot.transferring.remove(request)
# 调用_process_queue
self._process_queue(spider, slot)
# 发送信号
self.signals.send_catch_log(signal=signals.request_left_downloader,
request=request,
spider=spider)
return _
# 添加回调链
return dfd.addBoth(finish_transferring)
注册的handlers.download_request如下:
class DownloadHandlers:
def download_request(self, request, spider):
# 这里实现下载请求
# 获取scheme
scheme = urlparse_cached(request).scheme
# 根据scheme获取下载器处理器(handler)
handler = self._get_handler(scheme)
if not handler:
raise NotSupported(f"Unsupported URL scheme '{scheme}': {self._notconfigured[scheme]}")
# 调用对应的下载器处理器进行下载并返回
return handler.download_request(request, spider)
这里分两步,首先是获取scheme,然后根据scheme获取handler。主要看获取handler:
class DownloadHandlers:
def _get_handler(self, scheme):
# 获取对应的handler
if scheme in self._handlers:
return self._handlers[scheme]
if scheme in self._notconfigured:
return None
if scheme not in self._schemes:
self._notconfigured[scheme] = 'no handler available for that scheme'
return None
# 加载handler
return self._load_handler(scheme)
def _load_handler(self, scheme, skip_lazy=False):
path = self._schemes[scheme]
try:
dhcls = load_object(path)
if skip_lazy and getattr(dhcls, 'lazy', True):
return None
dh = create_instance(
objcls=dhcls,
settings=self._crawler.settings,
crawler=self._crawler,
)
except NotConfigured as ex:
self._notconfigured[scheme] = str(ex)
return None
except Exception as ex:
logger.error('Loading "%(clspath)s" for scheme "%(scheme)s"',
{"clspath": path, "scheme": scheme},
exc_info=True, extra={'crawler': self._crawler})
self._notconfigured[scheme] = str(ex)
return None
else:
self._handlers[scheme] = dh
return dh
加载完成后,会调用对应的处理器的 download_request 方法(每个下载器处理器都定义了该方法)进行下载。由于下载器处理器有很多,它们的实现方式也略有差异,这里简单看一下HTTP11DownloadHandler的实现:
class HTTP11DownloadHandler:
def download_request(self, request, spider):
# 实例化ScrapyAgent
agent = ScrapyAgent(
contextFactory=self._contextFactory,
pool=self._pool,
maxsize=getattr(spider, 'download_maxsize', self._default_maxsize),
warnsize=getattr(spider, 'download_warnsize', self._default_warnsize),
fail_on_dataloss=self._fail_on_dataloss,
crawler=self._crawler,
)
# 实例化后,调用其download_request方法
return agent.download_request(request)
class ScrapyAgent:
_Agent = Agent
_ProxyAgent = ScrapyProxyAgent
_TunnelingAgent = TunnelingAgent
def __init__(self, contextFactory=None, connectTimeout=10, bindAddress=None, pool=None,
maxsize=0, warnsize=0, fail_on_dataloss=True, crawler=None):
self._contextFactory = contextFactory
self._connectTimeout = connectTimeout
self._bindAddress = bindAddress
self._pool = pool
self._maxsize = maxsize
self._warnsize = warnsize
self._fail_on_dataloss = fail_on_dataloss
self._txresponse = None
self._crawler = crawler
def download_request(self, request):
from twisted.internet import reactor
timeout = request.meta.get('download_timeout') or self._connectTimeout
# 这里底层使用的是twisted获取agent
agent = self._get_agent(request, timeout)
# request details
url = urldefrag(request.url)[0]
method = to_bytes(request.method)
headers = TxHeaders(request.headers)
if isinstance(agent, self._TunnelingAgent):
headers.removeHeader(b'Proxy-Authorization')
if request.body:
bodyproducer = _RequestBodyProducer(request.body)
else:
bodyproducer = None
start_time = time()
# 这里也是调用twisted的request获得deferred对象
d = agent.request(method, to_bytes(url, encoding='ascii'), headers, bodyproducer)
# 添加回调链
d.addCallback(self._cb_latency, request, start_time)
# response body is ready to be consumed
d.addCallback(self._cb_bodyready, request)
d.addCallback(self._cb_bodydone, request, url)
# check download timeout
self._timeout_cl = reactor.callLater(timeout, d.cancel)
d.addBoth(self._cb_timeout, request, url, timeout)
return d
以上就是下载的大致流程,如果对细节感兴趣,可以研究一下twisted的底层实现。
_handle_downloader_output
现在,先回到从调度器获取下一个请求开头的部分,如果获取到下载结果,接下来就调用了 _handle_downloader_output方法:
class ExecutionEngine:
def _handle_downloader_output(self, response, request, spider):
# 类型判断,必须是Request,Response,Failure
if not isinstance(response, (Request, Response, Failure)):
raise TypeError(
"Incorrect type: expected Request, Response or Failure, got "
f"{type(response)}: {response!r}"
)
# 下载器中间件可以返回Request
if isinstance(response, Request):
# 如果是Request,就重新调用crawl
self.crawl(response, spider)
return
# 如果返回Response或者Failure,调用scraper.enqueue_scrape
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
这里分两种情况:
- 第一种是返回了
Request,那么就会重新调用crawl,在前面从调度器获取下一个请求已经讲过了。 - 第二种情况是返回
Response或者Failure,那么会调用scraper.enqueue_scrape
class Scraper:
def enqueue_scrape(self, response, request, spider):
slot = self.slot
# 调用Slot的add_response_request方法
dfd = slot.add_response_request(response, request)
# 定义回调函数
def finish_scraping(_):
slot.finish_response(response, request)
self._check_if_closing(spider, slot)
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
dfd.addErrback(
lambda f: logger.error('Scraper bug processing %(request)s',
{'request': request},
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
# 调用_scrape_next
self._scrape_next(spider, slot)
return dfd
def _scrape_next(self, spider, slot):
while slot.queue:
# 只要slot队列不为空,就从中获取保存的response, request, deferred信息
response, request, deferred = slot.next_response_request_deferred()
# 调用_scrape
self._scrape(response, request, spider).chainDeferred(deferred)
def _scrape(self, result, request, spider):
# 处理响应或者下载失败的情况
# 类型判断
if not isinstance(result, (Response, Failure)):
raise TypeError(f"Incorrect type: expected Response or Failure, got {type(result)}: {result!r}")
# 调用_scrape2
dfd = self._scrape2(result, request, spider) # returns spider's processed output
# 添加回调链
dfd.addErrback(self.handle_spider_error, request, result, spider)
dfd.addCallback(self.handle_spider_output, request, result, spider)
return dfd
def _scrape2(self, result, request, spider):
# 类型判断
if isinstance(result, Response):
# 如果是Response对象,调用爬虫中间件的scrape_response方法
return self.spidermw.scrape_response(self.call_spider, result, request, spider)
else: # result is a Failure
# 否则继续调用call_spider处理
dfd = self.call_spider(result, request, spider)
return dfd.addErrback(self._log_download_errors, result, request, spider)
def call_spider(self, result, request, spider):
if isinstance(result, Response):
if getattr(result, "request", None) is None:
result.request = request
# 在这里获取回调函数,如果在请求中定义了,就从result.request.callback中获取
# 而第一次请求则回调函数为spider._parse,调用它时,会返回self.parse(response, **kwargs)
# 这就是为什么在默认的parse里会获取到返回的原因
callback = result.request.callback or spider._parse
warn_on_generator_with_return_value(spider, callback)
dfd = defer_succeed(result)
dfd.addCallback(callback, **result.request.cb_kwargs)
else: # result is a Failure
result.request = request
# 在这里获取errback并添加
warn_on_generator_with_return_value(spider, request.errback)
dfd = defer_fail(result)
dfd.addErrback(request.errback)
return dfd.addCallback(iterate_spider_output)
class Slot:
def add_response_request(self, response, request):
# 创建deferred对象
deferred = defer.Deferred()
# 将参数入队
self.queue.append((response, request, deferred))
if isinstance(response, Response):
# 如果是Response对象,active_size等于响应体和1024的最小值(单位B)
self.active_size += max(len(response.body), self.MIN_RESPONSE_SIZE)
else:
# 如果不是Response对象,active_size等于1024(单位B)
self.active_size += self.MIN_RESPONSE_SIZE
return deferred
爬虫中间件的scrape_response方法如下:
class SpiderMiddlewareManager(MiddlewareManager):
def scrape_response(self, scrape_func, response, request, spider):
# scrape_func=self.call_spider
def process_callback_output(result):
# 执行所有定义了process_spider_output的爬虫中间件
return self._process_callback_output(response, spider, result)
def process_spider_exception(_failure):
# 执行所有定义了process_spider_exception的爬虫中间件
return self._process_spider_exception(response, spider, _failure)
# 添加回调函数_process_spider_input
dfd = mustbe_deferred(self._process_spider_input, scrape_func, response, request, spider)
# 添加回调
dfd.addCallbacks(callback=process_callback_output, errback=process_spider_exception)
return dfd
def _process_spider_input(self, scrape_func, response, request, spider):
for method in self.methods['process_spider_input']:
# 执行所有定义了process_spider_input的爬虫中间件
try:
result = method(response=response, spider=spider)
if result is not None:
msg = (f"Middleware {method.__qualname__} must return None "
f"or raise an exception, got {type(result)}")
raise _InvalidOutput(msg)
except _InvalidOutput:
raise
except Exception:
# 执行call_spider,里面有我们写的回调函数
return scrape_func(Failure(), request, spider)
# 执行call_spider,里面有我们写的回调函数
return scrape_func(response, request, spider)
在Scraper类的_scrape中,调用_scrape2之后,还添加了两个回调handle_spider_error和handle_spider_output,一个用于处理错误,另一个处理爬虫的返回值。
class Scraper:
def handle_spider_error(self, _failure, request, response, spider):
exc = _failure.value
if isinstance(exc, CloseSpider):
self.crawler.engine.close_spider(spider, exc.reason or 'cancelled')
return
logkws = self.logformatter.spider_error(_failure, request, response, spider)
logger.log(
*logformatter_adapter(logkws),
exc_info=failure_to_exc_info(_failure),
extra={'spider': spider}
)
self.signals.send_catch_log(
signal=signals.spider_error,
failure=_failure, response=response,
spider=spider
)
self.crawler.stats.inc_value(
f"spider_exceptions/{_failure.value.__class__.__name__}",
spider=spider
)
def handle_spider_output(self, result, request, response, spider):
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
# 这里添加了_process_spidermw_output方法
dfd = parallel(it, self.concurrent_items, self._process_spidermw_output,
request, response, spider)
return dfd
def _process_spidermw_output(self, output, request, response, spider):
if isinstance(output, Request):
# 如果是Request对象,重新调度
self.crawler.engine.crawl(request=output, spider=spider)
elif is_item(output):
# 如果为item则最终会依次调用管道的process_item方法
self.slot.itemproc_size += 1
dfd = self.itemproc.process_item(output, spider)
# 执行完自定义方法,会执行_itemproc_finished
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error(
'Spider must return request, item, or None, got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider},
)
def _itemproc_finished(self, output, item, response, spider):
self.slot.itemproc_size -= 1
if isinstance(output, Failure):
# 如果我们在管道中抛出异常
ex = output.value
if isinstance(ex, DropItem):
# 如果是DropItem异常则忽略它
logkws = self.logformatter.dropped(item, ex, response, spider)
if logkws is not None:
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_dropped, item=item, response=response,
spider=spider, exception=output.value)
else:
logkws = self.logformatter.item_error(item, ex, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider},
exc_info=failure_to_exc_info(output))
return self.signals.send_catch_log_deferred(
signal=signals.item_error, item=item, response=response,
spider=spider, failure=output)
else:
logkws = self.logformatter.scraped(output, response, spider)
if logkws is not None:
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_scraped, item=output, response=response,
spider=spider)
另外这里要解答一下:调用了
_handle_downloader_output处理下载结果时,为什么可以获取到参数呢?这还是涉及到twisted的回调链相关知识,如果一定要了解,请先阅读我的这篇文章的
回调链相关部分。假设你已经阅读了文章,理解了运行流程,那问题就简单了,下面是从调度器获取下一个请求的代码截取部分:
# 调用_download方法,调用下载器的方法,返回内联回调对象deferred d = self._download(request, spider) # 为deferred添加一系列回调链 d.addBoth(self._handle_downloader_output, request, spider)这里调用下载器方法(见_download),下载成功的回调函数的返回值是response,这个返回值将作为参数传递给下一个回调函数中,至于
request和spider则是在addBoth(self._handle_downloader_output, request, spider)这句话中传的参数!所以,
_handle_downloader_output中能够获取到下载器中间件的response。
回到开始调度的while循环中,你会发现,一次请求的完整流程大致结束了。当请求队列为空时,就会执行退出逻辑。
在阅读过程中,细心的话你会发现不止一次出现了@defer.inlineCallbacks装饰器,由于这是twisted相关内容,所以放到现在简单介绍一下,这是twisted中的内联回调,可以把它当做语法糖,它可以把生成器函数转化成异步回调对象。具体内容,我的这篇文章有更详细的介绍。至此,scrapy的整个运行流程与部分细节就已经分析完毕了,更多内容(比如信号、爬虫类、选择器等),今后会在这里继续补充。
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15861140.html
