IK分词器的使用
六、IK分词器的使用
之前已经介绍了IK分词器的下载和安装,下面就来验证一下:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "上海自来水来自海上"
}
如果返回如下数据就说明安装成功了:
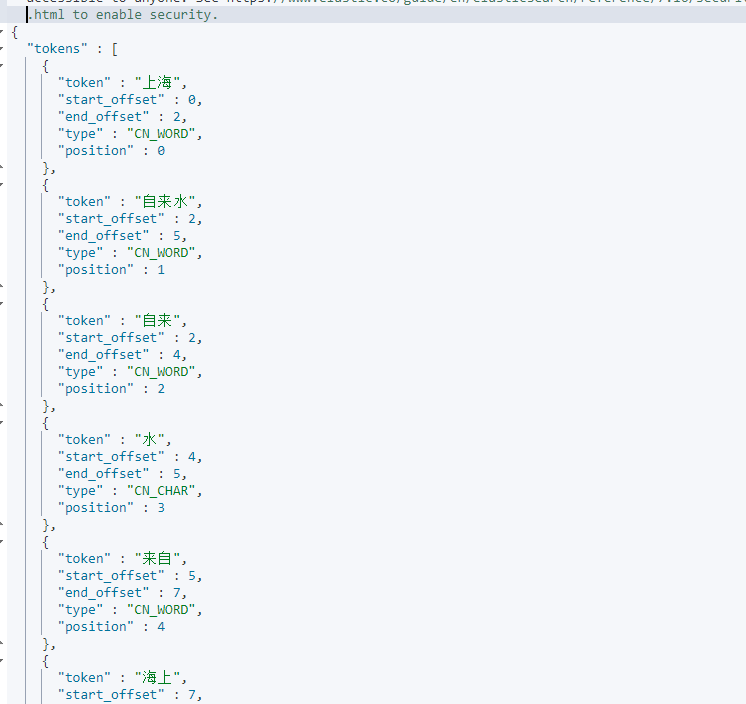
1 ik_max_word
ik_max_word参数会将文档做最细粒度的拆分,会穷尽各种可能的组合。
PUT ik1
{
"mappings": {
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
我们创建一个索引名为ik1,指定使用ik_max_word分词器,然后插入几条数据:
PUT ik1/_doc/1
{
"content":"真开心今天吃了三顿饭"
}
PUT ik1/_doc/2
{
"content":"今天你也在烦恼吗?笑一笑吧"
}
PUT ik1/_doc/3
{
"content":"爱笑的人运气都不会太差"
}
现在让我们开始查询:
GET ik1/_search
{
"query": {
"match": {
"content": "今天"
}
}
}
GET ik1/_search
{
"query": {
"match": {
"content": "笑"
}
}
}
2 ik_smart
ik_smart是另一种分词方式,它将文档作粗粒度的拆分。比如,爱笑的人运气都不会太差这句话:
- ik_max_word会拆分为:爱笑,的人,运气,都不会,都不,不会,太差
- ik_smart会拆分为:爱笑,的人,运气,都不会,太差
由上面的对比可以发现,两个参数的不同,所以查询结果也肯定不一样,视情况而定用什么粒度。
至于查询,与之前介绍的查询方法完全一样。
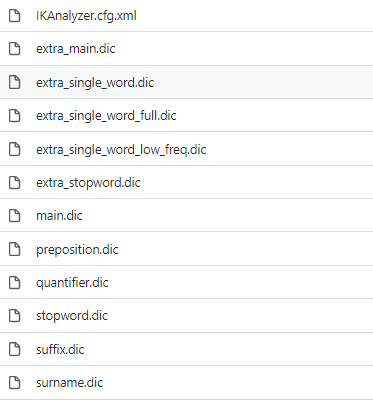
3 ik目录简介
在ik/config目录下有ik分词配置文件:
- IKAnalyzer.cfg.xml,用来配置自定义的词库
- main.dic,ik原生内置的中文词库,只要是这些单词,都会被分在一起。
- surname.dic,中国的姓氏。
- suffix.dic,特殊(后缀)名词,例如
乡、江、所、省等等。 - preposition.dic,中文介词,例如
不、也、了、仍等等。 - stopword.dic,英文停用词库,例如
a、an、and、the等。 - quantifier.dic,单位名词,如
厘米、件、倍、像素等。 - extra开头的文件,是额外的词库。
4 扩展词库
在ik/config目录下的IKAnalyzer.cfg.xml中可以扩展词库:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
比如我们添加一个词典,在config目录下新建一个new.dic:
<entry key="ext_dict">new.dic</entry>
然后重启es,再使用分词器试试:
GET _analyze
{
"analyzer": "ik_smart",
"text": "奥利给干了兄弟们"
}

注意词库的编码必须是utf-8。
IK插件还支持热更新,在配置文件中的如下配置
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
其中 words_location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
- 该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 - 该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启es 。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt文件。
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15700638.html
