并发编程
十八、并发编程
1 并发和并行
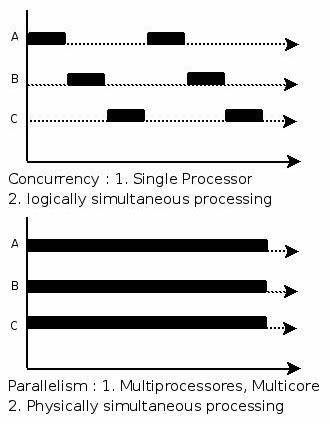
并发是指多个事件在同一时间间隔内发生,或者说并发是具有同时处理多个任务的能力。
并行是指多个事件在同一时刻发生,注意同一时刻和同一时间间隔的区别。并发在宏观上看上去,一段时间内多个任务同时执行,但是在每一时刻,单处理机只能有一道程序执行,只是操作系统会不断的切换多个任务。
举个例子,如果你在0-1分钟切菜,1-2分钟洗水果,2-3分钟切菜,那么在0-3分钟的时间间隔里,切菜和洗水果是并发的;如果你在0-3分钟的每一时刻,左手切菜,右手洗水果,那么这两个动作就是并行的。下图可以帮助你更好地理解:
2 go协程
线程又被称为轻量级进程,它是程序执行的最小单元,线程不拥有系统资源(只拥有一点运行中必须的资源),它可以与同属于一个进程的其他线程共享进程资源,线程的切换由操作系统调度。
协程又称微线程,协程运行在用户态下,由于在进程切换时会消耗很多资源,协程则避免了这个问题,协程完全由程序自己控制,操作系统并不会感知。在go中,创建一个go协程的开销很小,你可以创建千百个协程并发运行。
go协程称为goroutine,go通过goroutine支持并发,goroutine是go中最基本的执行单元。
生成一个goroutine的方式非常简单,使用go关键字就创建了:
import (
"fmt"
"time"
)
func main() {
// 创建10个goroutine
for i := 0; i < 10; i++ {
go func() {
fmt.Println("创建一个goroutine")
}()
}
time.Sleep(3 * time.Second)
}
我们创建了10个go协程,它们与main函数并发执行,main函数运行在主协程上。正如上文所说,go协程的开销很小(几kb),所以可以创建很多goroutine,多个goroutine调度的顺序是乱序的。
另外,在主进程中我们sleep等待了三秒,如果不等待会发生什么呢?尝试把它去掉,你会发现程序什么都没有输出。这就是go协程的性质,主协程不会等待go协程执行完毕。在调用协程之后,主协程会立即执行代码的下一行,忽略该协程的任何返回值。如果主协程结束运行,则其他协程也不会继续运行。所以我们暂且使用sleep等待其他协程执行完毕,才结束主协程,这样就能看到输出。
3 goroutine的GMP调度模型
goroutine的整体调度模型如下图:
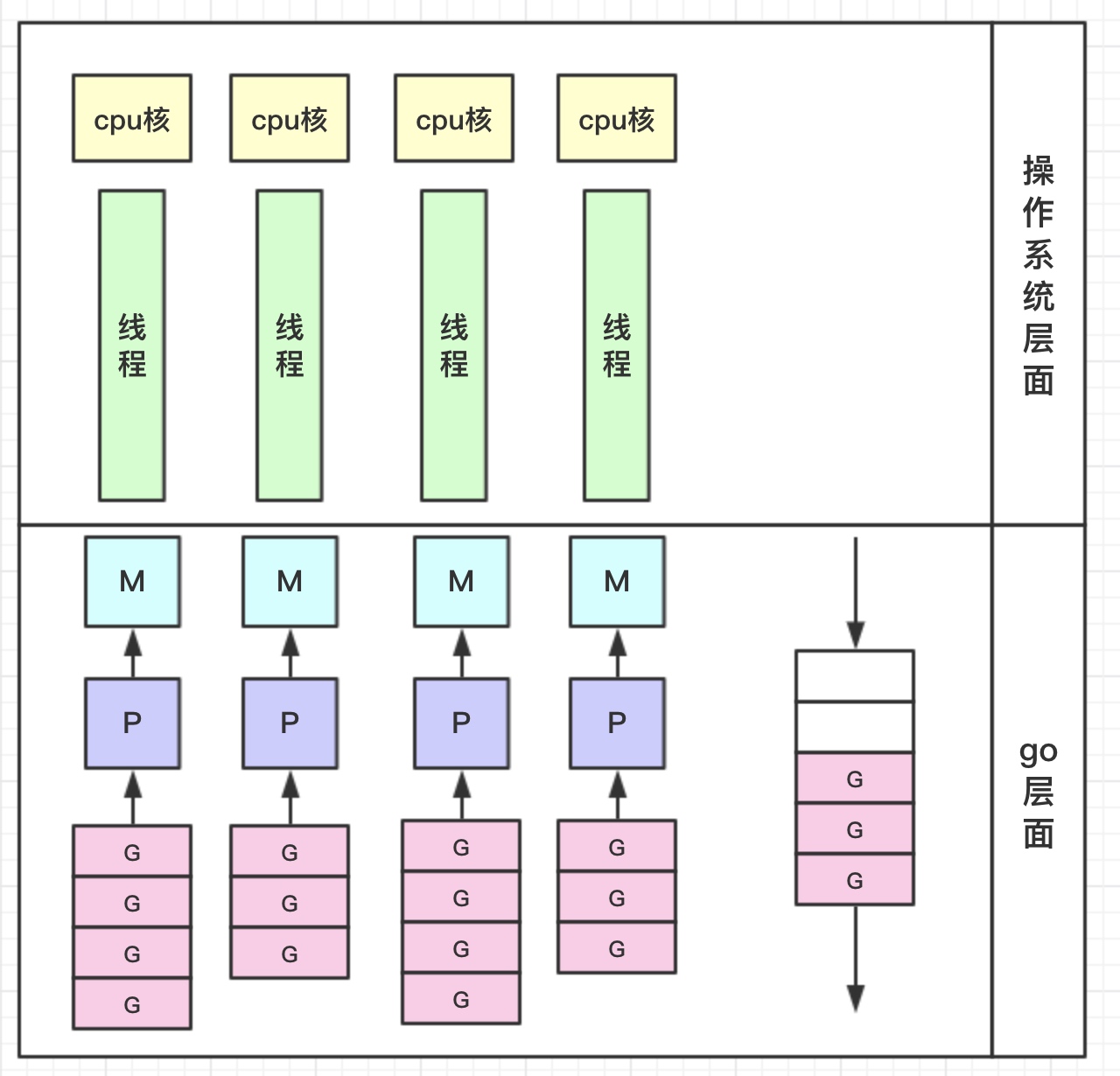
其中:
- G指goroutine,在全局有一个Global队列,每当创建一个goroutine就把它入队
- M指machine,它代表一个用户级线程,所有的G任务,最终还是在M上执行
- P指processor处理器,它也维护了一个goroutine队列,里面存储了所有需要它来执行的goroutine。它处在G和M之间,直接与M交互。P默认就是CPU可用的核数,可以通过
runtime.GOMAXPROCS修改(一般不修改)。
调度的过程是这样的,当通过go关键字创建一个新的goroutine的时候,它会优先被放入P的本地队列。为了运行goroutine,M需要持有(绑定)一个P,接着M会启动一个内核级线程,循环从P的本地队列里取出一个goroutine并执行。当M执行完了当前P的Local队列里的所有G后,P会先尝试从Global队列寻找G来执行,如果Global队列为空,它会随机挑选另外一个P,从它的队列里中拿走一半的G到自己的队列中执行。
4 channel定义
channel(信道/通道)是go的一种重要特性,类似于管道,其本质是一个先进先出的队列,它实现了goroutine之间的通信,多个goroutine可同时修改一个channel。
channel是一个变量,使用chan来定义。
var 变量名 chan 类型
// channel是有类型的,比如int类型的channel只能存放整型
channel是引用类型,和其他引用类型一样,channel 的空值为nil。channel一定要初始化后才能进行读写操作,否则会永久阻塞,所以一般使用make创建channel。
ch := make(chan int)
5 使用channel进行通信
初始化一个channel,就可以在里面取值放值,
ch := make(chan int)
// 放值
ch <- 3
// 取值
<- ch
默认情况下向channel发送数据和接收数据会阻塞,举例:
func foo(ch chan int) {
fmt.Println("hello world")
// 阻塞,直到有其它goroutine从ch放数据
a := <-ch
fmt.Println(a)
}
func main() {
ch := make(chan int)
go foo(ch)
// 向channel中放一个值,阻塞,直到有其它goroutine从ch取到数据
ch <- 3
}
读取数据推荐方法:
a, ok := <-ch
// 如果取到,ok=true;反之为false
6 关闭channel
go提供了内置的close函数对channel进行关闭操作。
ch := make(chan int)
close(ch)
注意以下几点:
-
关闭一个未初始化(nil) 的channel会产生panic
-
重复关闭同一个channel会产生 panic
-
向一个已关闭的channel中发送消息会产生 panic
-
从已关闭的channel读取消息不会产生panic,且能读出channel中还未被读取的消息,若消息均已读出,则会读到类型的零值。从一个已关闭的channel中读取消息永远不会阻塞,并且会返回一个为 false的ok-idiom,可以用它来判断 channel 是否关闭。
-
关闭channel会产生一个广播机制,所有向channel读取消息的goroutine都会收到消息。接收方可以用ok来检查信道是否已经关闭
7 死锁
当go协程给一个channel发送数据时,如果没有其他go协程来接收数据,就会形成死锁。同理,当有go协程等待从一个channel接收数据时,如果没有人发送,也会死锁。
8 单向channel
channel类型是可以带有方向的:
var readOnlyChan <-chan int // 只读chan,只能读channel,不可写入
var writeOnlyChan chan<- int // 只写chan,只能写channel,不可读
var ch chan int //读写channel
可能你有疑问,前面说过不管读写都会阻塞,如果定义只读或者只写channel不会发生死锁吗?实际上,单独定义确实没有意义,所以一般在主goroutine中定义读写channel,然后在一些函数参数传递时候指明可读还是可写。比如:
func foo(ch <-chan int) { // 定义只读channel 只负责读,不能写
fmt.Println("hello world")
a, ok := <-ch
fmt.Println(a, ok)
}
func main() {
ch := make(chan int)
go foo(ch)
ch <- 3
}
9 遍历channel
可以使用for range遍历信道:
func producer(ch chan int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Println("存放", i)
}
close(ch)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch {
fmt.Println("接收", v)
}
}
// 上述代码执行结果为:
存放 0
接收 0
接收 1
存放 1
存放 2
接收 2
接收 3
存放 3
存放 4
接收 4
可以看到,for range一直从信道中尝试接收数据,如果信道没有关闭也没有数据就阻塞等待,一旦某个goroutine发送数据,就立刻取出。直到信道关闭时,循环会自动结束。
10 缓冲channel
带缓冲区channel:定义声明时候制定了缓冲区长度,可以保存多个数据。只在缓冲已满的情况,发送数据时才会阻塞;同样,只有在缓冲为空的时候,接收数据才会阻塞。
不带缓冲区channel:发送数据就阻塞,直到有goroutine读;读取时也会阻塞,直到有goroutine写。
定义一个带缓冲的channel很简单:
ch := make(chan type, [capacity])// 创建channel信道的语法,capacity可选,如果不写默认为0
// 举例
ch := make(chan int) // 不带缓冲区,此时capacity为0
ch := make(chan int,10) // 带缓冲区
要让一个信道有缓冲,上面语法中的 capacity 应该大于 0,一旦定义了缓冲channel,在缓冲满之前不会阻塞。
11 waitgroup
使用waitgroup可以实现同步,即等待所有的goroutine执行完成。举个例子:
func foo(i int) {
fmt.Printf("foo执行了%d次\n", i+1)
}
func main() {
for i := 0; i < 5; i++ {
go foo(i)
}
}
如果直接执行,主协程不会等待go协程执行完毕,所以看不到任何输出。我们可以定义一个waitgroup:
var wg sync.WaitGroup
// 它不是引用类型,当作参数传递时是值传递,要想修改原来的值需要传指针(地址)
WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。我们在上述代码的基础上使用WaitGroup:
func foo(i int, wg *sync.WaitGroup) {
fmt.Printf("foo执行了%d次\n", i+1)
wg.Done() // Done() 表示把计数器-1
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1) // Add(1)表示把计数器+1
go foo(i, &wg) // 使用指针类型才可以修改原值
}
wg.Wait() // wait() 会阻塞代码运行,直到计数器的值减为0
}
输出结果为
// 顺序是不固定的
foo执行了5次
foo执行了1次
foo执行了4次
foo执行了2次
foo执行了3次
另外,Add(delta int)函数中,参数delta可以为负值;但是如果计数器为负值,会提示panic: sync: negative WaitGroup counter 错误。
12 Mutex
go提供了mutex用多个goroutine的互斥访问。互斥问题的场景很多,比如并发更新同一个资源、并发更新计数器、秒杀活动等等,这些都需要保证数据准确。首先要明确临界资源的概念。不论是进程、线程还是goroutine,互斥问题的概念都是相通的:我们把一次仅允许一个goroutine使用的资源称为临界资源。为了保证临界资源的正确使用,可以划分为四部分
- 进入区:在进入临界区之前,负责阻止其它goroutine同时进入临界区
- 临界区:使用临界资源
- 退出区:某个goroutine退出临界区之后,负责更改临界区状态,允许其它goroutine访问临界区
- 剩余区:其余部分
实现互斥访问的方式有很多,mutex是互斥锁,可确保在某时刻只有一个goroutine在临界区运行,以防止出现竞态条件。
在go的标准库中,package sync提供了锁相关的一系列同步原语,还定义了一个Locker的接口,mutex就实现了这个接口。
type Locker interface {
Lock()
Unlock()
}
使用mutex解决互斥问题:
func incr(wg *sync.WaitGroup, m *sync.Mutex) { // mutex需要引用传递
m.Lock()
x = x + 1
m.Unlock()
wg.Done()
}
func main() {
var x = 0
var w sync.WaitGroup
var m sync.Mutex
for i := 0; i < 100; i++ {
w.Add(1)
go incr(&w, &m) // 传递引用
}
w.Wait()
fmt.Println("x结果是", x)
}
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15681013.html
