
线性回归模型
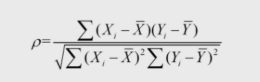
重要名词解释:
# 数据符号网站 fhdq.net/sx/14.html
# 因变量与自变量
# 哑变量
# 如何判断两个变量之间是否存在线性关系与非线性关系
1.散点图
2.公式计算
大于等于0.8 表示高度相关
绝对值大于等于0.5小于等于0.8 表示中度相关
绝对值大于等于0.3小于等于0.5 表示弱相关
绝对值小于3.0 表示几乎不相关(需要注意这里的不相干指的是没有线性关系 可能两者之间有其他关系)
# 插入数据分析三剑客 import numpy as np import pandas as pd import matplotlib.pyplot as plt
# 编写数据 X = [52,19,7,33,2] Y = [162,61,22,100,6]
# 1.公式计算均值 XMean = np.mean(X) YMean = np.mean(Y) # 输出查看结果 XMean,YMean

# 标准差 XSD = np.std(X) YSD = np.std(Y) # 输出查看结果 XSD,YSD
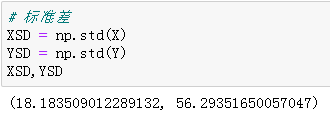
# z分数 ZX = (X-XMean)/XSD ZY = (Y-YMean)/YSD # 输出查看结果 ZX,ZY
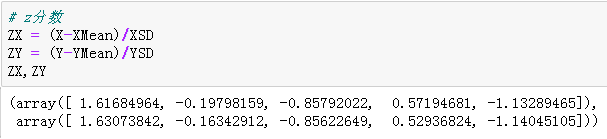
# 相关系数 r = np.sum(ZX*ZY)/(len(X)) # 输出查看结果 r
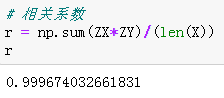
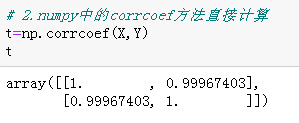
# 2.numpy中的corrcoef方法直接计算 t=np.corrcoef(X,Y) # 输出查看结果 t
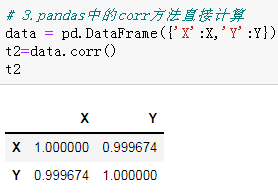
# 3.pandas中的corr方法直接计算 data = pd.DataFrame({'X':X,'Y':Y}) t2=data.corr() # 输出查看结果 t2
# 训练集与测试集
训练集一般用于模型的训练创建 # 一般情况下占比80%
测试集用于模型的测试检验 # 一般情况下占比20%
自定义哑变量:
# 哑变量
在生成算法模型的时候 有些变量可能并不是数字 无法直接代入公式
此时可构造哑变量>>> C(State)
# 生成由State变量衍生的哑变量 dummies = pd.get_dummies(Profit.State) # 将哑变量与原始数据集水平合并 Profit_New = pd.concat([Profit,dummies], axis = 1) # 删除State变量和California变量(因为State变量已被分解为哑变量,New York变量需要作为参照组) Profit_New.drop(labels = ['State','New York'], axis = 1, inplace = True) # 拆分数据集Profit_New train, test = model_selection.train_test_split(Profit_New, test_size = 0.2, random_state=1234) # 建模 model2 = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+Florida+California', data = train).fit() print('模型的偏回归系数分别为:\n', model2.params)
