14.容器和迭代器
14. 容器和迭代器
14.1 引言
标准库定义了功能强大的、基于模板的、可重用的组件,这些组件实现了许多用于处理这些数据结构的常见数据结构和算法。这一节介绍的特性被称作标准模板库(STL)。
标准库的三个关键组件---容器(模板化的数据结构),迭代器以及算法。容器是能够存储几乎任何数据类型的对象的数据结构(有一些限制)。
迭代器具有类似于指 针的属性,用于操作容器元素 。内置数组也可以由标准库算法操作,使用指针作为迭代器。
标准库算法是执行常见数据操作(如搜索、排序和比较元素或整个容器)的函数模板。
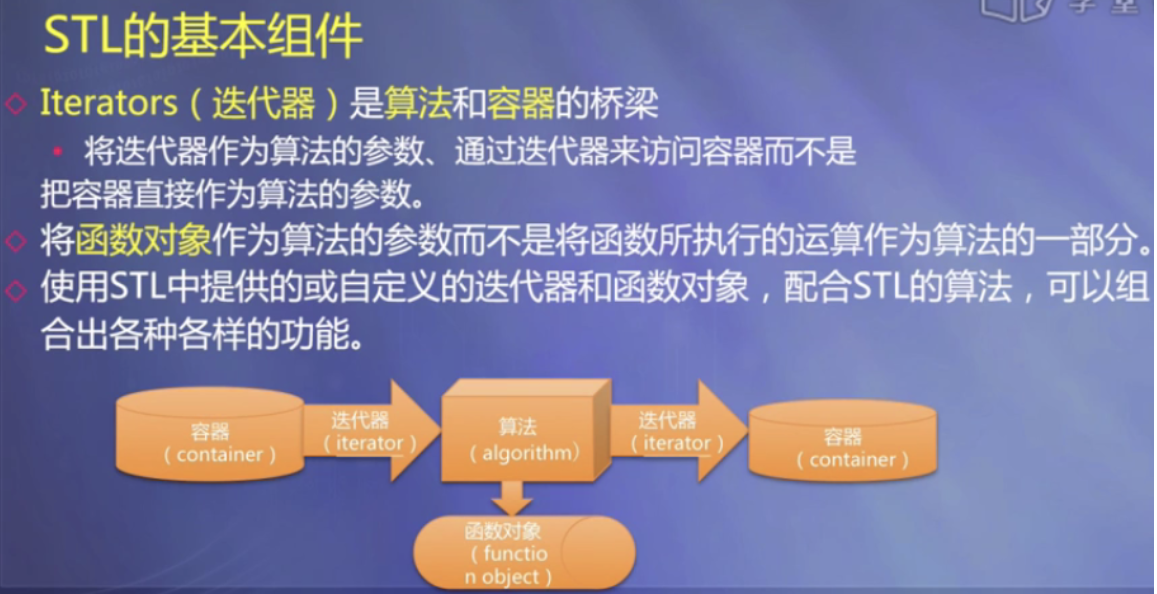
避免重新发明轮子;如果可能,请使用C++标准库的组件进行编程。
14.1.1 泛型程序设计
1.编写不依赖于具体数据类型的程序
2.将算法从特定的数据结构中抽象出来,成为通用的
3.C++的STL为泛型程序设计奠定了基础



14.2 容器的介绍
容器被分为四个主要的类别:sequence containers(顺序容器), ordered associative containers(顺序关联容器), unordered associative containers(无序关联容器) and container adapters(容器适配器).
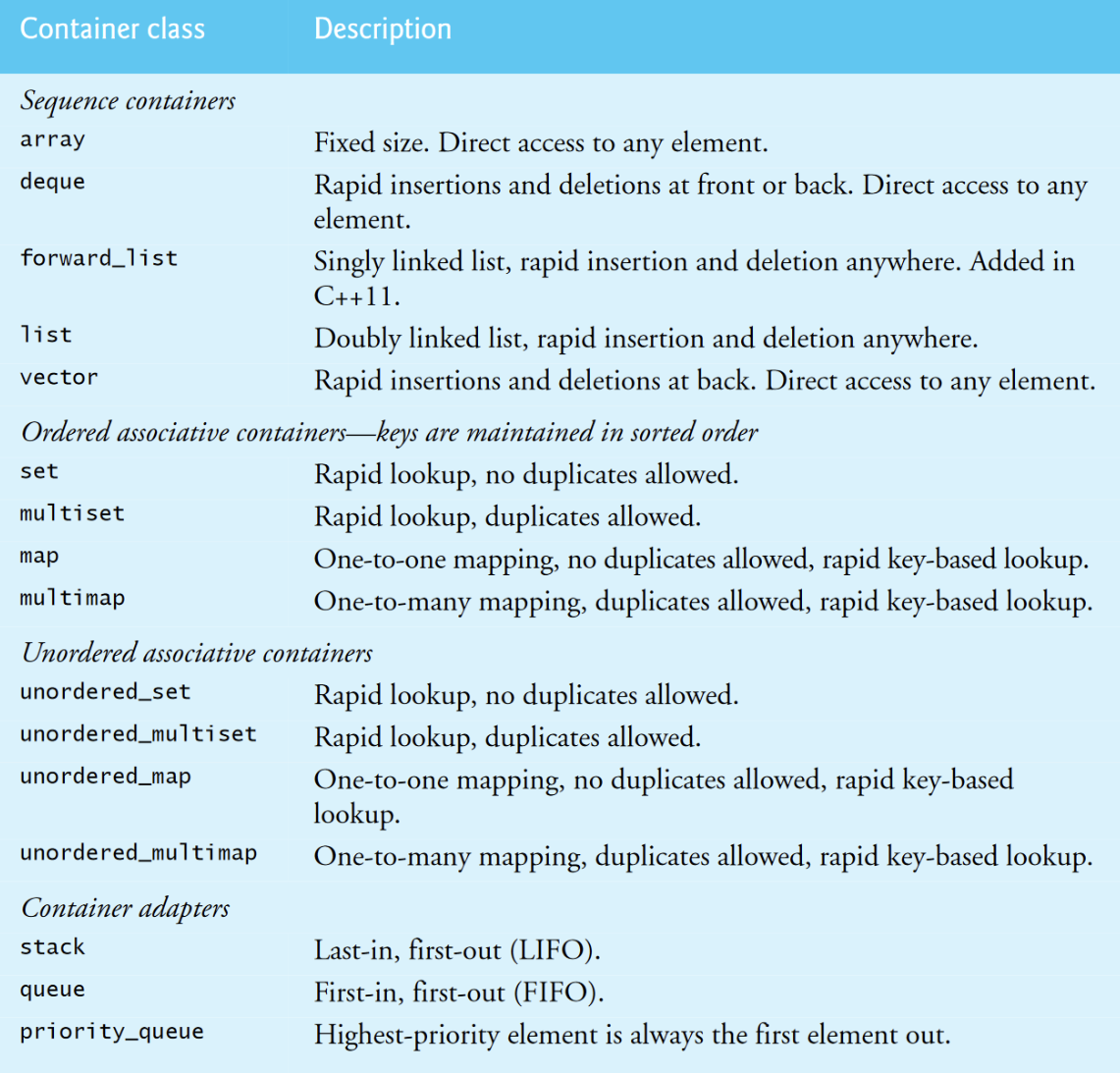
顺序容器代表线性数据结构(即,它们的所有元素在概念上都是“排成一排的"),例如arrays,vectors和链表。关联容器是非线性数据结构,通常可以快速定位存储在容器中的元素。
key–value pairs(键值对):键-值对(key- value pair)是编程语言对数学概念中映射的实现。键(key)用作元素的索引,值(value)则表示所存储和读取的数据。
顺序容器和关联容器被称为first-class containers.堆栈和队列通常是序列容器的约束版本。因此,标准库将类模板stack,queue和priority_queue实现为容器适配器,使程序能够以受约束的方式查看序列容器。
string类支持与顺序容器相同的功能,但是仅支持存储字符数据。

常用容器函数:
大多数容器都提供类似的功能。许多操作适用于所有容器,而其他操作适用于类似容器的子集。



Overloaded operators <, <=, >, >=, == and != are not provided for priority_queues. Overloaded operators <, <=, > and >= are not provided for the unordered associative containers. Member functions rbegin, rend, crbegin and crend are not available in a forward_list.
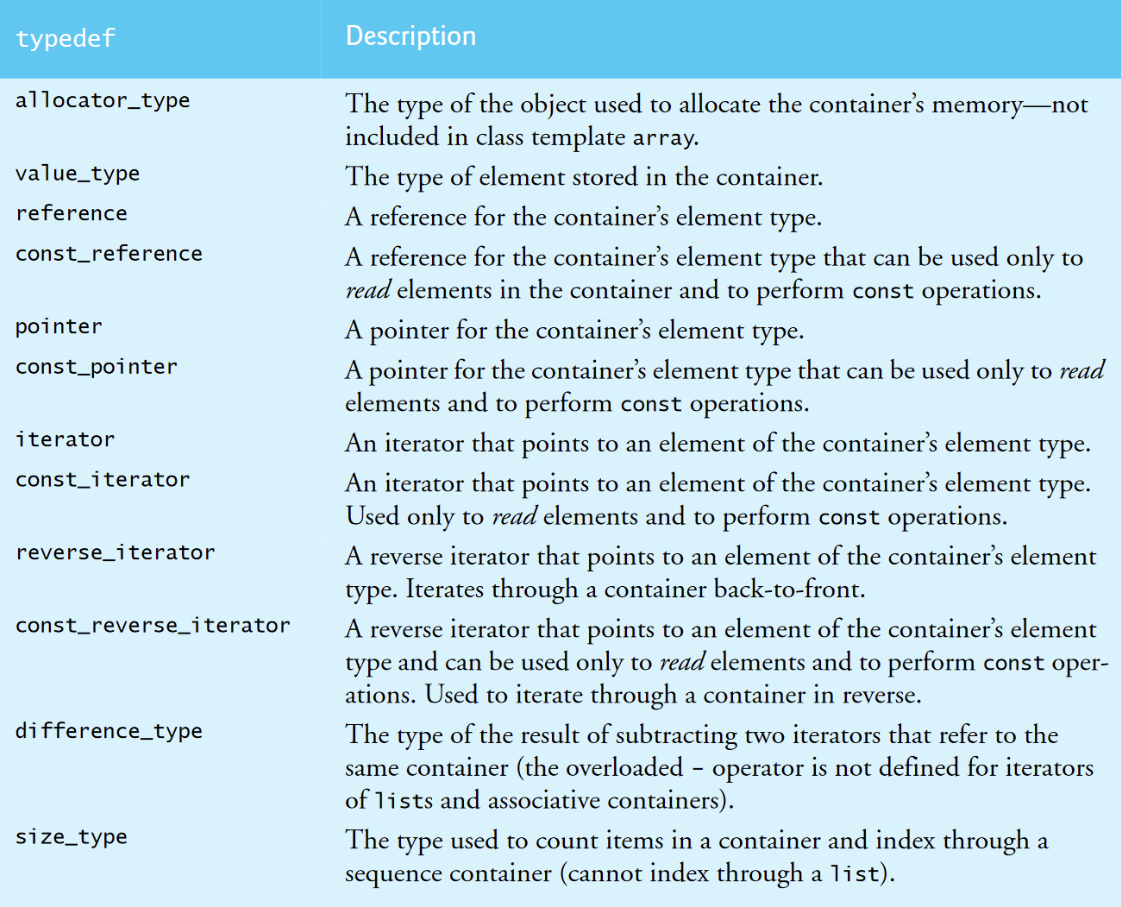
First-Class Container Common Nested Types
下图显示了常见的first-class container嵌套类型(在每个容器类定义中定义的类型)。
容器元素的要求
在使用标准库容器之前,请务必确保容器中存储的对象类型支持一组最少的功能。将对象插入容器时,将创建该对象的副本。对象类型应提供复制构造函数和复制赋值运算符(自定义版本或默认版本,具体取决于类是否使用动态内存)。此外,有序关联容器和许多算法需要比较元素,因此,对象类型应提供小于 (<) 和相等 (==) 运算符。
14.3 迭代器介绍
迭代器是专门用来遍历容器的。迭代器是专门用来遍历容器的对象(是容器类的内部类型)
假设v是一个容器,比如 vector<int> v;
v的迭代器的类型为:vector<int>::iterator
所以,定义一个迭代器变量的写法为:
vector<int>::iterator itr;
迭代器与指针有许多相似之处,用于指向first-class container的元素以及用于其他目的。迭代器保存对它们所操作的特定容器敏感的状态信息;因此,为每种类型的容器实现了迭代器。某些迭代器操作在容器之间是统一的。例如,取消引用运算符 (*) 取消引用迭代器,以便您可以使用它指向的元素。迭代器上的 ++ 操作将其移动到容器的下一个元素(就像将指针递增到内置数组中会将指针指向下一个数组元素一样)。

First-class containers提供成员函数begin和end。begin函数返回一个指向容器第一个元素的迭代器。函数 end 返回一个迭代器,该迭代器指向容器末尾之后的第一个元素(一个末尾),这是一个不存在的元素,经常用于确定何时到达容器末尾。
容器iterator类型的对象是指可以修改的容器元素。容器const_iterator类型的对象是指无法修改的容器元素。

Using istream_iterator for Input and ostream_iterator for Output
我们使用带有sequences(也称为ranges)的迭代器。istream_iterator/ostream_iterator
#include <iostream>
#include <iterator>
using namespace std;
int main() {
cout<<"Enter two integers: ";
// create istream_iterator for reading int values from cin
istream_iterator<int> inputInt{cin};
int number1{*inputInt};
++inputInt;
int number2{*inputInt};
// create ostream_iterator for writing int values to cout
ostream_iterator<int> outputInt{cout};
cout<<"The sum is: ";
*outputInt = number1 + number2;//output result to cout
cout<<endl;
}
上述代码创建一个能够从标准输入对象 cin 中提取(输入)int 值的istream_iterator。上述代码表示能够在标准输出对象cout 中插入(输出)int 值的ostream_iterator。

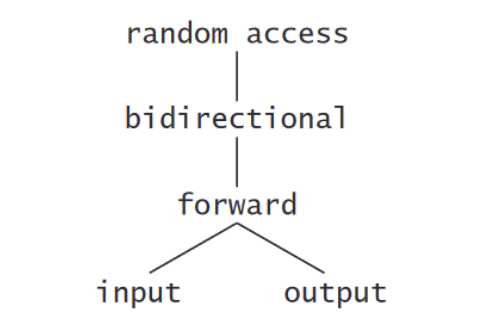
Iterator Categories and Iterator Category Hierarchy

As you follow the hierarchy from bottom to top, each iterator category supports all the functionality of the categories below it in the figure. Thus the “weakest” iterator types are at the bottom and the most powerful one is at the top. Note that this is not an inheritance hierarchy.
Container Support for Iterators(容器对迭代器的支持)
每个容器支持的迭代器类别决定了该容器是否可以与特定算法一起使用。支持随机访问迭代器的容器可以与所有标准库算法一起使用,但如果算法需要更改容器的大小,则该算法不能用于内置数组或数组对象。大多数算法都可以使用指向内置数组的指针来代替迭代器。下图显示了每个容器的迭代器类别。first-class containers、字符串和内置数组都可以使用迭代器进行遍历。

Predefined Iterator typedefs
并非每个 typedef 都是为每个容器定义的。

Iterator Operations
下图显示了每个迭代器类型可以执行的操作。


14.4 算法的介绍
标准库提供了大量算法,您将经常使用这些算法来操作各种容器。插入、删除、搜索、排序等适用于部分或全部顺序和关联容器。这些算法仅通过迭代器间接对容器元素进行操作。
14.5 顺序容器
C++提供五种顺序容器,array,vector,deque,list和forward_list。类模板array,vector和deque通常基于内置数组。类模板list和forward_list实现链表数据结构。


通常更倾向于重用标准库容器,而不是开发自定义模板化数据结构。对于大多数应用程序来说,Vector 通常是令人满意的。
需要在容器两端频繁插入和删除的应用程序通常使用 deque 而不是 vector。虽然我们可以在vector和 deque 的前面和后面插入和删除元素,但类 deque 在前面进行插入和删除比vector更有效。
在容器的中间和/或极端处频繁插入和删除的应用程序通常使用list,因为它可以有效地实现在数据结构中的任何位置插入和删除。

14.5.1 顺序容器-vector
我们在之前介绍的类模板vector提供了一个具有连续内存位置的动态数据结构。这样就可以通过下标运算符 [] 高效、直接地访问向量的任何元素,就像使用内置数组一样。当容器中的数据必须通过下标轻松访问或将要排序时,以及元素的数量可能需要增加时,最常使用类模板vector。当向量的内存耗尽时,向量会分配一个更大的内置数组,复制(或移动)将原始元素放入新的内置数组中,并解除分配旧的内置数组。

#include <iostream>
#include <vector>// vector class-template definition
using namespace std;
// prototype for function template printVector
template <typename T> void printVector(const vector<T>& integers2);
int main() {
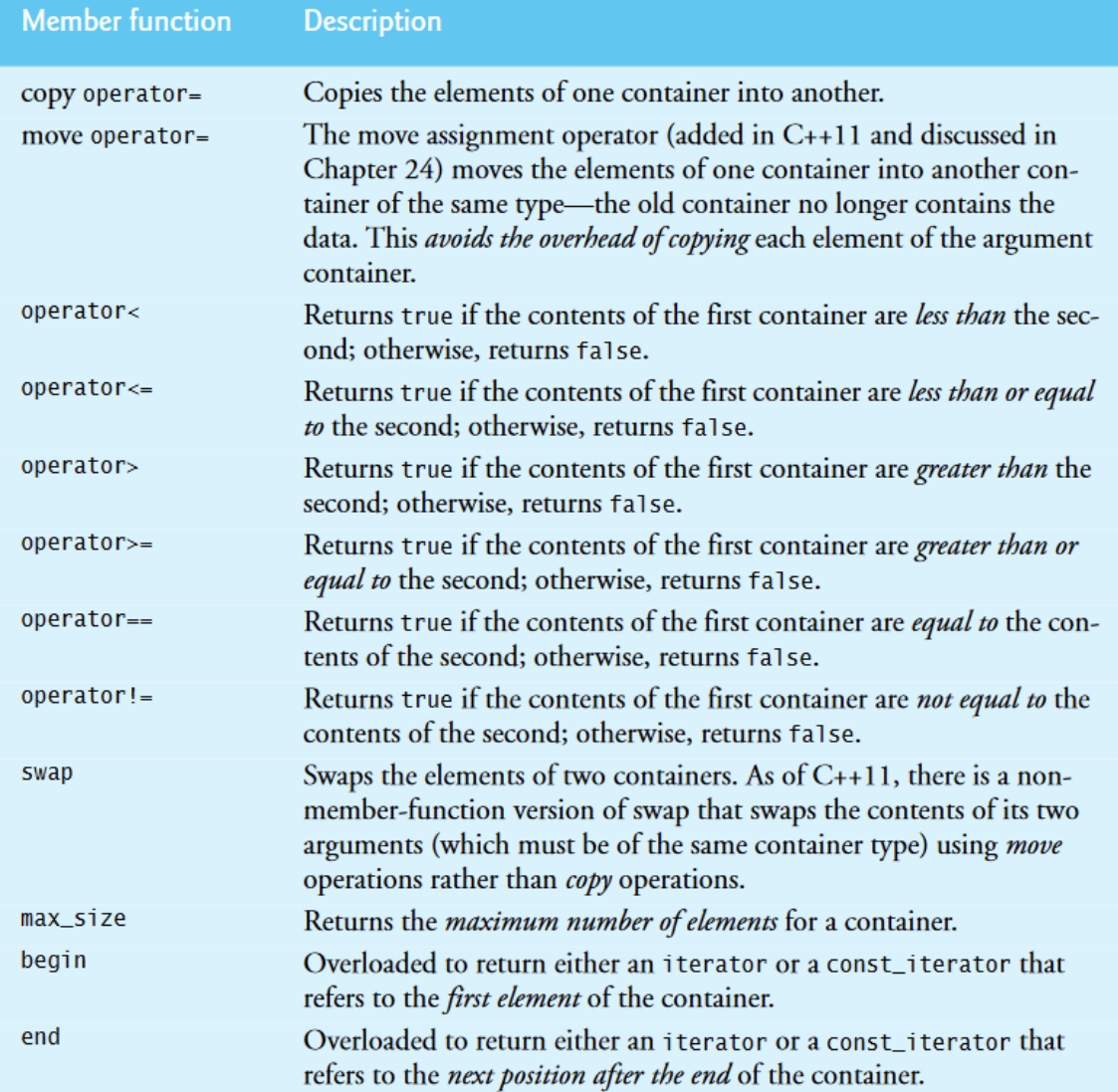
vector<int> integers;
cout<<"The initial size of integers is: "<<integers.size()
<<"\nThe initial capacity of integers is: "<<integers.capacity();
//function push_back is in vector, deque and list
integers.push_back(2);
integers.push_back(3);
integers.push_back(4);
cout<<"\nThe size of integers is: "<<integers.size()
<<"\nThe capacity of integers is: "<<integers.capacity();
cout<<"\n\nOutput built-in array using pointer notation: ";
const size_t SIZE{6};
int values[SIZE]{1,2,3,4,5,6};// initialize values
// display array using pointer notation
for(const int* ptr = cbegin(values); ptr!= cend(values);++ptr){
cout<<*ptr<<' ';
}
cout<<"\nOutput vector using iterator notation: ";
printVector(integers);
cout << "\nReversed contents of vector integers: ";
// display vector in reverse order using const_reverse_iterator
for(auto reverseIterator=integers.crbegin();reverseIterator != integers.crend(); ++reverseIterator){
cout << *reverseIterator << ' ';
}
cout<<endl;
}
// function template for outputting vector elements
template <typename T> void printVector(const vector<T>& integers2){
// display vector elements using const_iterator
for(auto constIterator=integers2.cbegin();constIterator != integers2.cend();++constIterator){
cout << *constIterator << ' ';
}
}

创建vector:
下列语句生成了一个类模板vector的名为integers的对象,用以存储int类型的值。vector的默认构造函数创造一个空的vector,没有存储任何元素(即,vector的size为0),并且没有存储元素的空间(即,它的capacity为0)。所以向vector中添加元素时,需要分配内存。
vector<int> integers;
vector的成员函数size和capacity:
size函数可以在处除了forward_list之外的所有容器中使用,此函数返回容器中当前存储的元素个数。capacity函数(只在vector和deque中使用),返回在向量需要动态调整自身大小以容纳更多元素之前可以存储在向量中的元素数。
vector的成员函数push_back:
push_back函数(在array和forward_list之外的顺序容器中可以使用)将元素附加到vector中。如果vector的容量已满(即其capacity等于其size),则vector会增加其大小 - 某些实现将vector的容量增加一倍。array和vector以外的顺序容器也提供push_front函数。

在修改vector后更新size和capacity:
当我们向vector中添加一个元素时,vector会为这一个元素分配空间,size函数会返回1,以说明当前vector中存储了一个元素。
当我们向vector中添加第二个元素时,vector的capacity会翻倍,即,变为2。size函数的返回值也会变成2。
当我们向vector中添加第三个元素时,vector的capacity会翻倍,即,变为4。size函数的返回值为3。
当vector中被元素填满以后,再试图添加元素,vector的capacity会变成8。
使用指针输出内置数组的内容:
指向内置数组的指针可用作迭代器。使用 C++14 的全局 cbegin 和 cend 函数,它们的工作方式与函数begin和end的方式相同,但返回不能用于修改数据的const迭代器。C++14提供了rbegin,rend,crbegin和crend函数用以遍历整个内置数组或者容器。rbegin和rend返回的迭代器可以用来修改数据,crbegin和crend返回的const迭代器不可以修改数据。
使用迭代器输出vector的内容:
上述代码调用函数printVector使用迭代器输出vector中的内容。函数接收const vector的引用。vector的成员函数cbegin返回指向vector首元素的const_iterator。vector的成员函数cend返回指向vector最后一个元素下一个位置的const_iterator。
函数 cbegin、begin、cend 和 end 可用于所有first-class containers。
请记住,迭代器的作用类似于指向元素的指针,并且运算符 * 被重载以返回对元素的引用。
// function template for outputting vector elements
template <typename T> void printVector(const vector<T>& integers2){
// display vector elements using const_iterator
for(auto constIterator=integers2.cbegin();constIterator != integers2.cend();++constIterator){
cout << *constIterator << ' ';
}
}
上述代码中的for循环可以使用基于范围的for循环替换:
for (auto const& item : integers2) {
cout << item << ' ';
}
试图解引用一个位于容器外的迭代器会导致错误---即由end或cend函数返回的迭代器不能解引用以及进行递增操作。
使用const_reverse_iterator反向输出vector中的元素:
C++11 添加了vector成员函数 crbegin 和 crend,它们在反向遍历容器时返回表示起点和终点的const_reverse_iterators。大部分first-class containers支持这种类型的迭代器。vector类还提供了成员函数rbegin rend以获得non-const reverse_iterator。
C++11:shrink_to_fit:
在C++11中,可以使vector和deque调用成员函数shrink_to_fit以返回系统不需要的内存。这要求容器将其容量减少到容器中的元素数。根据 C++ 标准,实现可以忽略此请求,以便它们可以执行特定于实现的优化。
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
#include <stdexcept>
using namespace std;
int main(){
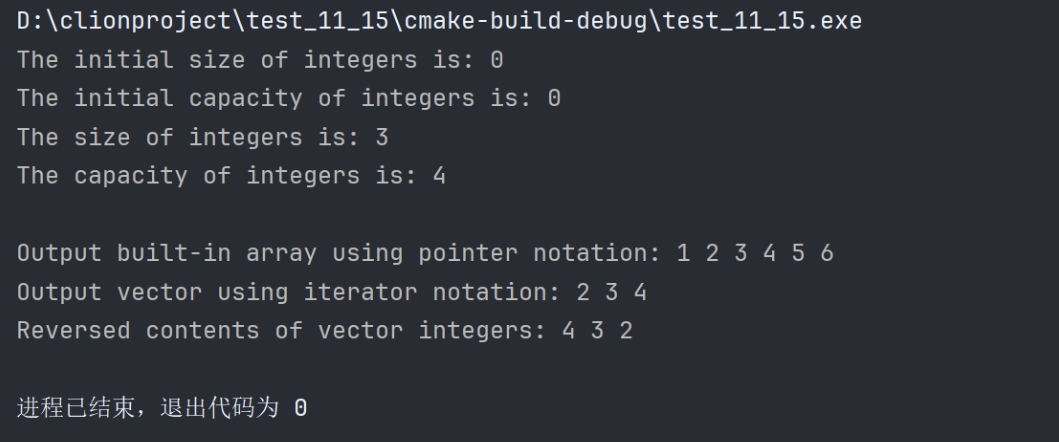
vector<int> values{1, 2, 3, 4, 5, 6};
vector<int> integers{values.cbegin(), values.cend()};
ostream_iterator<int> output{cout, " "};
cout << "Vector integers contains: ";
copy(integers.cbegin(), integers.cend(), output);
cout << "\nFirst element of integers: "<<integers.front()
<<"\nLast element of integers: "<<integers.back();
integers[0] = 7;//set first element to 7
integers.at(2) = 10;// set element at position 2 to 10
// insert 22 as 2nd element
integers.insert(integers.cbegin() + 1, 22);
cout << "\n\nContents of vector integers after changes: ";
copy(integers.cbegin(), integers.cend(), output);
// access out-of-range element
try{
integers.at(100) = 777;
}
catch(out_of_range &outOfRange){// out_of_range exception
cout << "\n\nException: " << outOfRange.what();
}
integers.erase(integers.cbegin());// erase first element
cout << "\n\nVector integers after erasing first element: ";
copy(integers.cbegin(), integers.cend(), output);
// erase remaining elements
integers.erase(integers.cbegin(), integers.cend());
cout << "\nAfter erasing all elements, vector integers "
<<(integers.empty() ? "is" : "is not")<<" empty";
// insert elements from the vector values
integers.insert(integers.cbegin(), values.cbegin(), values.cend());
cout << "\n\nContents of vector integers before clear: ";
copy(integers.cbegin(), integers.cend(), output);
// empty integers; clear calls erase to empty a collection
integers.clear();
cout << "\nAfter clear, vector integers "
<<(integers.empty()?"is":"is not")<<" empty" << endl;
}
ostream_iterator<int> output{cout, " "};
上述代码定义了一个名为output的ostream_iterator,可以通过cout输出以单个空格分隔的整数。一个ostream_iterator
copy算法:
copy(integers.cbegin(), integers.cend(), output);
上述代码使用了copy算法,来自头文件
vector的成员函数front和back:
cout << "\nFirst element of integers: "<<integers.front()
<<"\nLast element of integers: "<<integers.back();
上述代码使用的函数front和back分别决定vector的第一个和最后一个元素。front返回vector中第一个元素的引用,begin函数返回指向vector第一个元素的random-access iterator。back函数返回vector最后一个元素的引用,而end函数返回指向vector最后一个元素下一个位置的random-access iterator。
The results of front and back are undefined when called on an empty vector.
访问vector的元素:
integers[0] = 7;//set first element to 7
integers.at(2) = 10;// set element at position 2 to 10
上述访问vector元素的方式也可以用在deque容器中。第一行代码使用重载的下标运算符返回对指定位置值的引用或对该 const 值的引用,具体取决于容器是否为 const。at函数具有相同的功能,但是此函数会执行边界检查。如果元素不在容器内,函数会抛出异常(out_of_range)。下图为一些标准库异常类型。

vector的成员函数insert:
// insert 22 as 2nd element
integers.insert(integers.cbegin() + 1, 22);
每个顺序容器都提供了重载的insert函数(数组除外,它具有固定大小,forward_list除外,它具有函数 insert_after)。在上述语句中,迭代器指向容器中的第二个元素,所以将22插入容器作为新的第二个元素,原先的第二个元素就变为了第三个元素。此函数返回指向插入元素的迭代器。
vector的成员函数erase:
integers.erase(integers.cbegin());// erase first element
cout << "\n\nVector integers after erasing first element: ";
copy(integers.cbegin(), integers.cend(), output);
// erase remaining elements
integers.erase(integers.cbegin(), integers.cend());
cout << "\nAfter erasing all elements, vector integers "
<<(integers.empty() ? "is" : "is not")<<" empty";
每个first-class containers都提供了erase函数(数组除外,它具有固定大小,forward_list除外,它具有函数 erase_after)。第一行代码擦除了容器中第一个元素。第二个erase函数擦除两个迭代器指明的元素位置之间的所有元素。empty函数(所有的容器和适配器都可用)用以证明容器已经为空。
通常,“擦除”会销毁从容器中擦除的对象。但是,擦除作为指向动态分配对象的指针的元素不会删除动态分配的内存,这可能会导致内存泄漏。如果该元素是unique_ptr(第 17.9 节),则unique_ptr将被销毁,动态分配的内存将被删除。如果元素是shared_ptr(第 24 章),则动态分配对象的引用计数将递减,并且仅当引用计数达到 0 时才会删除内存。
vector的成员函数insert(三个参数):
integers.insert(integers.cbegin(), values.cbegin(), values.cend());
上述代码将values的全部元素都插入到vector中,从vector的第二个元素的位置开始插入。函数返回第一个插入的元素的迭代器,如果没有插入任何元素,则返回函数的第一个参数。
vector的成员函数clear:
clear函数(在除了array以外的所有first-class containers均可以找到)清空vector---这不一定将vector的任何内存返回给系统。
14.5.2 顺序容器-list
顺序容器list,来自头文件<list>。允许在容器的任意位置进行插入和删除操作。如果大部分插入和删除操作都出现在容器的最后,deque容器会更加有效。类模板list是作为双向链表实现的,即列表中的每个节点都包含指向列表中前一个节点和列表中下一个节点的指针。这使类模板列表能够支持双向迭代器,这些迭代器允许向前和向后遍历容器。任何需要输入、输出、正向或双向迭代器的算法都可以对列表进行操作。许多列表成员函数将容器的元素作为一组有序的元素进行操作。

C++11:forward_list容器:

forward_list的头文件为<forward_list>实现为单向链表,即列表中的每个节点都包含指向list中下一个节点的指针。这使类模板list能够支持正向迭代器,这些迭代器允许容器在正向遍历。任何需要输入、输出或正向迭代器的算法都可以在forward_list
list成员函数:
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
#include <iterator>
using namespace std;
//prototype for function template printList
template <typename T> void printList(const list<T>& listRef);
int main(){
list<int> values;
list<int> otherValues;
//insert items in values
values.push_front(1);
values.push_front(2);
values.push_back(4);
values.push_back(3);
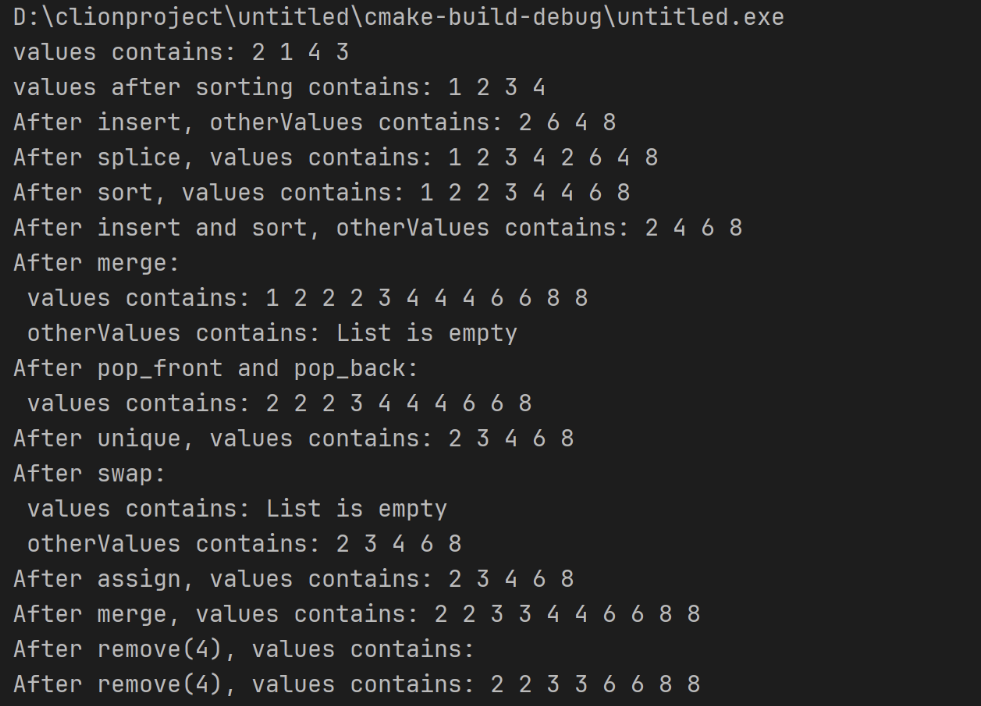
cout << "values contains: ";
printList(values);
values.sort(); // sort values
cout << "\nvalues after sorting contains: ";
printList(values);
// insert elements of ints into otherValues
vector<int> ints{2, 6, 4, 8};
otherValues.insert(otherValues.cbegin(), ints.cbegin(), ints.cend());
cout << "\nAfter insert, otherValues contains: ";
printList(otherValues);
// remove otherValues elements and insert at end of values
values.splice(values.cend(), otherValues);
cout << "\nAfter splice, values contains: ";
printList(values);
values.sort(); // sort values
cout << "\nAfter sort, values contains: ";
printList(values);
// insert elements of ints into otherValues
otherValues.insert(otherValues.cbegin(), ints.cbegin(), ints.cend());
otherValues.sort(); // sort the list
cout << "\nAfter insert and sort, otherValues contains: ";
printList(otherValues);
// remove otherValues elements and insert into values in sorted order
values.merge(otherValues);
cout << "\nAfter merge:\n values contains: ";
printList(values);
cout << "\n otherValues contains: ";
printList(otherValues);
values.pop_front(); // remove element from front
values.pop_back(); // remove element from back
cout << "\nAfter pop_front and pop_back:\n values contains: ";
printList(values);
values.unique(); // remove duplicate elements
cout << "\nAfter unique, values contains: ";
printList(values);
values.swap(otherValues);// swap elements of values and otherValues
cout << "\nAfter swap:\n values contains: ";
printList(values);
cout << "\n otherValues contains: ";
printList(otherValues);
// replace contents of values with elements of otherValues
values.assign(otherValues.cbegin(), otherValues.cend());
cout << "\nAfter assign, values contains: ";
printList(values);
// remove otherValues elements and insert into values in sorted order
values.merge(otherValues);
cout << "\nAfter merge, values contains: ";
printList(values);
values.remove(4);// remove all 4s
cout << "\nAfter remove(4), values contains: ";
cout << "\nAfter remove(4), values contains: ";
printList(values);
cout << endl;
}
// printList function template definition; uses
// ostream_iterator and copy algorithm to output list elements
template <typename T> void printList(const list<T>& listRef){
if (listRef.empty()){
cout << "List is empty";
}
else{
ostream_iterator<T> output{cout, " "};
copy(listRef.cbegin(), listRef.cend(), output);
}
}
创建list对象:
list<int> values;
list<int> otherValues;
上述代码创建了两个list对象,可以存储int类型的值。
values.push_front(1);
values.push_front(2);
上述代码使用函数push_front将整数插入到values的起始位置。push_front函数只能在forward_list,list和deque中使用。push_back函数将值插入到容器的末尾位置。push_back函数在除了array和forward_list之外的所有顺序容器中都可以使用。
list的成员函数sort:
成员函数sort将list中的元素以升序排列。
values.sort(); // sort values
list的成员函数splice:
splice函数删除otherValues中的元素并将这些元素插入到values指定位置的前面。
// remove otherValues elements and insert at end of values
values.splice(values.cend(), otherValues);
list的成员函数merge:
// remove otherValues elements and insert into values in sorted order
values.merge(otherValues);
merge函数移除otherValues的所有元素,并将他们排序后插入到values中。进行操作的两个list必须先进行相同的排序后再使用merge函数。
list成员函数pop_front:
values.pop_front(); // remove element from front
values.pop_back(); // remove element from back
pop_front函数移除list中的第一个元素。pop_back移除list中的最后一个函数。
list的成员函数unique:
unique函数移除list中的重复元素。在进行此操作之前,需要先将list排序。
values.unique(); // remove duplicate elements
list成员函数swap:
swap函数(available to all first-class containers)交换两个list中的元素。
values.swap(otherValues);// swap elements of values and otherValues
list成员函数assign和remove:
assign函数(available to all sequence containers)将指定范围的otherValues中的元素插入到values中。
// replace contents of values with elements of otherValues
values.assign(otherValues.cbegin(), otherValues.cend());
values.remove(4);// remove all 4s
remove函数将values中的数值4删除。
14.5.3 顺序容器-deque
The term deque is short for “double-ended queue.”类 deque 提供对随机访问迭代器的支持,因此 deque 可以与所有标准库算法一起使用。One of the most common uses of a deque is to maintain a first-in, first-out queue of elements. 事实上,deque 是queue适配器的默认底层实现
deque 的额外存储可以在 deque 的任一端以内存块的形式分配,这些内存块通常作为指向这些块的指针的内置数组进行维护。由于 deque 的内存布局不连续,deque 迭代器必须比用于遍历向量,arrays和内置数组的指针更“智能”。

一般的,使用deque的开销比vector更大。
在deque中间的插入和删除经过优化,以最大程度地减少复制的元素数量,因此它比向量更有效,但比列表的效率逊色。
使用类deque时必须包含头文件<deque>
#include <iostream>
#include <deque>
#include <algorithm>
#include <iterator>
using namespace std;
int main() {
deque<double> values;
ostream_iterator<double> output{cout," "};
//insert elements in values
values.push_front(2.2);
values.push_front(3.5);
values.push_back(1.1);
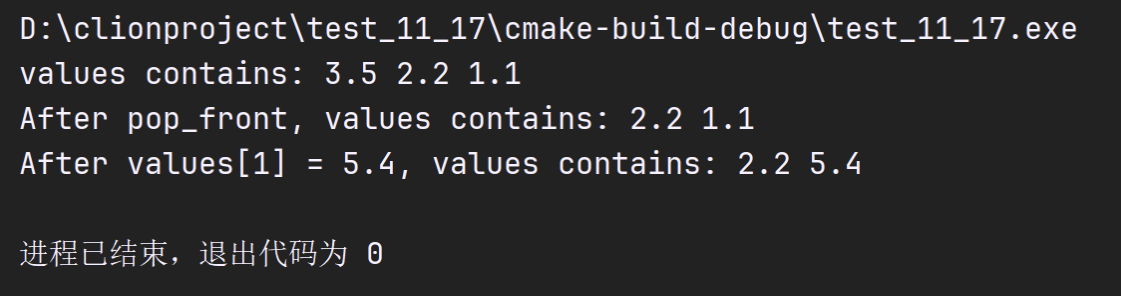
cout << "values contains: ";
// use subscript operator to obtain elements of values
for (size_t i{0}; i < values.size(); ++i){
cout <<values[i] << ' ';
}
values.pop_front();// remove first element
cout << "\nAfter pop_front, values contains: ";
copy(values.cbegin(), values.cend(), output);
// use subscript operator to modify element at location 1
values[1] = 5.4;
cout << "\nAfter values[1] = 5.4, values contains: ";
copy(values.cbegin(), values.cend(), output);
cout << endl;
}
14.5.4 顺序容器的插入迭代器

14.6 关联容器

关联容器通过key(通常称为search keys)提供对存储和检索元素的直接访问。四种有序关联容器为multiset,set,multimap和map。还有四种无序关联容器,unordered_multiset, unordered_set, unordered_multimap 和 unordered_map。

Classes multiset and set provide operations for manipulating sets of values where the values themselves are the keys.The primary difference between a multiset and a set is that a multiset allows duplicate keys and a set does not.Classes multimap and map provide operations for manipulating values associated with keys (these values are sometimes referred to as mapped values).The primary difference between a multimap and a map is that a multimap allows duplicate keys with associated values to be stored and a map allows only unique keys with associated values.
14.6.1 关联容器-multiset
multiset来自头文件<set>。

#include <array>
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
#include <vector>
using namespace std;
int main(){
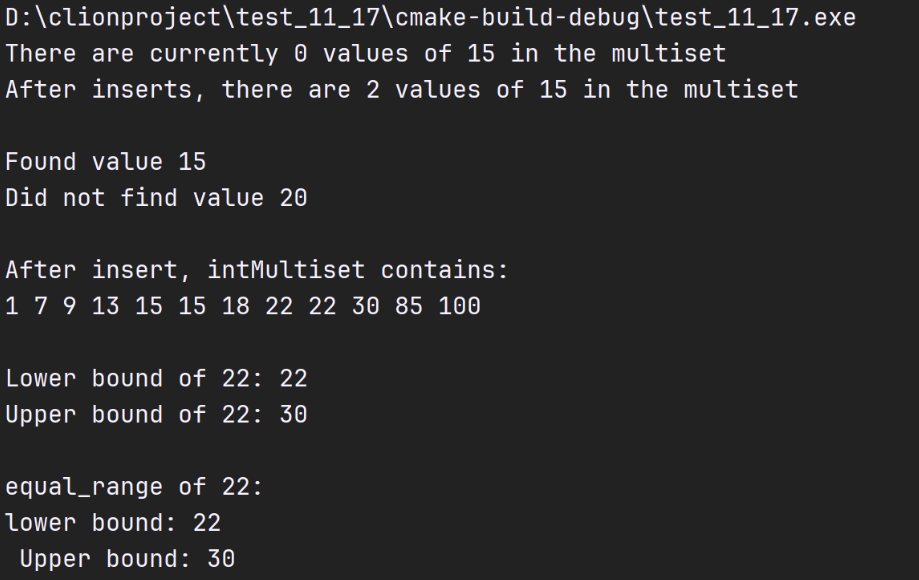
multiset<int,less<int>> intMultiset;//multiset of ints
cout<<"There are currently "<<intMultiset.count(15)
<<" values of 15 in the multiset\n";
intMultiset.insert(15);// insert 15 in intMultiset
intMultiset.insert(15);// insert 15 in intMultiset
cout << "After inserts, there are "<<intMultiset.count(15)
<<" values of 15 in the multiset\n\n";
// find 15 in intMultiset; find returns iterator
auto result{intMultiset.find(15)};
if (result != intMultiset.end()){// if iterator not at end
cout << "Found value 15\n"; // found search value 15
}
// find 20 in intMultiset; find returns iterator
result = intMultiset.find(20);
if (result == intMultiset.end()){// will be true hence
cout << "Did not find value 20\n"; // did not find 20
}
// insert elements of array a into intMultiset
vector<int> a{7, 22, 9, 1, 18, 30, 100, 22, 85, 13};
intMultiset.insert(a.cbegin(), a.cend());
cout << "\nAfter insert, intMultiset contains:\n";
ostream_iterator<int> output{cout, " "};
copy(intMultiset.begin(), intMultiset.end(), output);
// determine lower and upper bound of 22 in intMultiset
cout << "\n\nLower bound of 22: "
<<*(intMultiset.lower_bound(22));
cout << "\nUpper bound of 22: "<<*(intMultiset.upper_bound(22));
// use equal_range to determine lower and upper bound
// of 22 in intMultiset
auto p{intMultiset.equal_range(22)};
cout << "\n\nequal_range of 22:"<<"\nlower bound: "
<<*(p.first)<<"\n Upper bound: "<<*(p.second);
cout<<endl;
}
创建multiset:
下述语句创建了multiset,存储Int类型的值,以升序存储。升序存储是此容器的默认设置,所以可以省略less
multiset<int,less<int>> intMultiset;//multiset of ints
上述语句可以写为:
multiset<int> intMultiset; // multiset of ints
multiset成员函数count:
count函数对所有关联容器可用。
cout<<"There are currently "<<intMultiset.count(15)
<<" values of 15 in the multiset\n";
上述count函数用以返回intMultiset中数值15的个数。
multiset成员函数insert:
intMultiset.insert(15);// insert 15 in intMultiset
上述函数将15插入到intMultiset中。
vector<int> a{7, 22, 9, 1, 18, 30, 100, 22, 85, 13};
intMultiset.insert(a.cbegin(), a.cend());
上述语句将a中的元素从开始到末尾,插入到intMultiset中,插入后为排序完成的容器。
multiset成员函数find:
find函数(对所有关联容器可用)用以确定容器中元素的位置。
auto result{intMultiset.find(15)};
返回一个iterator 或者 const_iterator(取决于容器是否为const的)。如果没有找到元素的位置,则返回一个和end函数返回的迭代器一样的迭代器。
multiset成员函数lower_bound和upper_bound
lower_bound 和 upper_bound对所有关联容器可用。
// determine lower and upper bound of 22 in intMultiset
cout << "\n\nLower bound of 22: "
<<*(intMultiset.lower_bound(22));
cout << "\nUpper bound of 22: "<<*(intMultiset.upper_bound(22));
使用函数 lower_bound 和 upper_bound来查找intMultiset中最早出现值 22 以及值 22 最后一次出现之后的元素。
lower_bound 和 upper_bound返回iterators 或者 const_iterators指向恰当的位置,或者在没有相应元素的情况下,指向和end函数返回结果一样的位置。
multiset成员函数equal_range:
auto p{intMultiset.equal_range(22)};
cout << "\n\nequal_range of 22:"<<"\nlower bound: "
<<*(p.first)<<"\n Upper bound: "<<*(p.second);
cout<<endl;
equal_range会返回一个pair类型的值,包含两个迭代器。此处p的值将会是两个const_iterators。两个const_iterators分别是函数lower_bound 和 upper_bound返回的迭代器。pair类包含两个public数据成员,first和second。如果需要解引用lower_bound 和 upper_bound返回的迭代器,则需要提前保证返回的迭代器在容器的范围之内。
14.6.2 关联容器-set
set关联容器,需要头文件<set>。用于快速存储和检索容器中的唯一的键。set容器的实现和multiset的实现一样,除了set容器要求容器中的键是各不相同的。set支持bidirectional iterators(不支持random-access iterators)。集合可以用来存储一组无重复的元素。由于集合元素本身是有序的,可以高效的查找指定元素,也可以方便的得到指定大小范围的元素在容器中所处得空间。
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
#include <iterator>
using namespace std;
int main(){
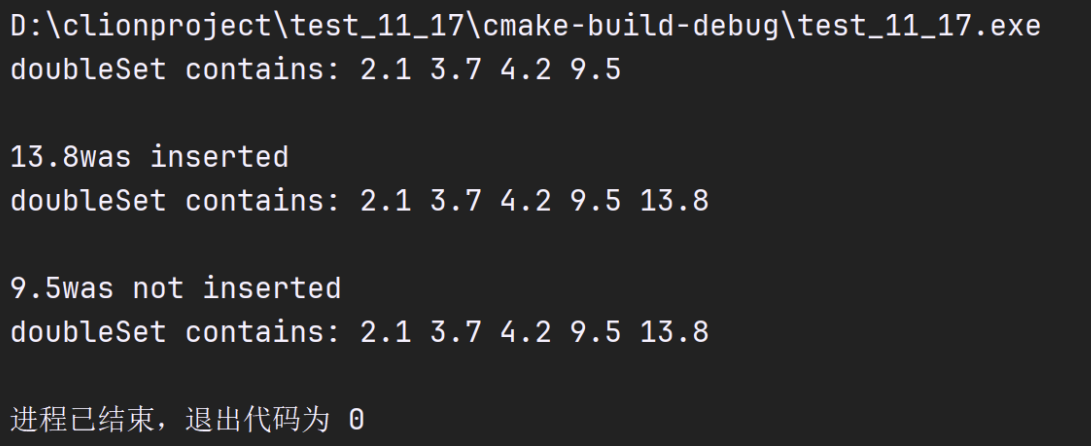
vector<double> a{2.1, 4.2, 9.5, 2.1, 3.7};
set<double, less<double>> doubleSet{a.begin(), a.end()};
cout << "doubleSet contains: ";
ostream_iterator<double> output{cout," "};
copy(doubleSet.begin(),doubleSet.end(),output);
//insert 13.8 in doubleSet; insert returns pair in which
// p.first represents location of 13.8 in doubleSet and
// p.second represents whether 13.8 was inserted
auto p{doubleSet.insert(13.8)}; // value not in set
cout<<"\n\n"<<*(p.first)
<<(p.second?"was":"was not")<<" inserted";
cout<<"\ndoubleSet contains: ";
copy(doubleSet.begin(),doubleSet.end(),output);
// insert 9.5 in doubleSet
p = doubleSet.insert(9.5); // value already in set
cout << "\n\n"<<*(p.first)
<<(p.second?"was":"was not")<<" inserted";
cout<<"\ndoubleSet contains: ";
copy(doubleSet.begin(), doubleSet.end(), output);
cout << endl;
}
14.6.3 关联容器-multimap
The elements of multimaps and maps are pairs of keys and values instead of individual values.multimap来自头文件
#include <iostream>
#include <map>
using namespace std;
int main(){
multimap<int, double, less<int> > pairs; // create multimap
cout << "There are currently "<< pairs.count(15)
<<" pairs with key 15 in the multimap\n";
// insert two value_type objects in pairs
pairs.insert(make_pair(15, 99.3));
pairs.insert(make_pair(15, 2.7));
cout << "After inserts, there are "<<pairs.count(15)
<<" pairs with key 15\n\n";
// insert five value_type objects in pairs
pairs.insert(make_pair(30, 111.11));
pairs.insert(make_pair(10, 22.22));
pairs.insert(make_pair(25, 33.333));
pairs.insert(make_pair(20, 9.345));
pairs.insert(make_pair(5, 77.54));
cout << "Multimap pairs contains:\nKey\tValue\n";
// walk through elements of pairs
for (auto mapItem : pairs){
cout << mapItem.first << '\t' << mapItem.second << '\n';
}
cout<<endl;
}
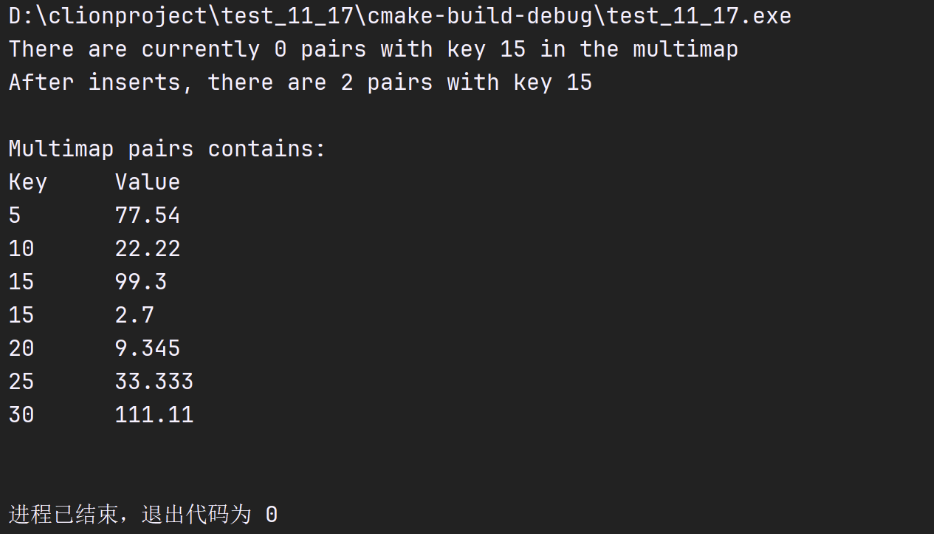
multimap<int, double, less<int> > pairs; // create multimap
pairs.insert(make_pair(15, 99.3));
pairs.insert(make_pair(15, 2.7));
上述语句使用insert函数向pairs中插入新的键值对。标准库函数make_pair创造键值pair对象。在此种情况下,first成员代表int类型的键(15),second成员代表值(99.3)。make_pair函数会自动使用用户指定的键值对的类型。也可以使用列表初始化将上述代码简化如下:
pairs.insert({15, 2.7});
14.6.4 关联容器-map
Duplicate keys are not allowed—a single value can be associated with each key.This is called a one-to-one mapping.头文件<map>必须包含。

#include <iostream>
#include <map>
using namespace std;
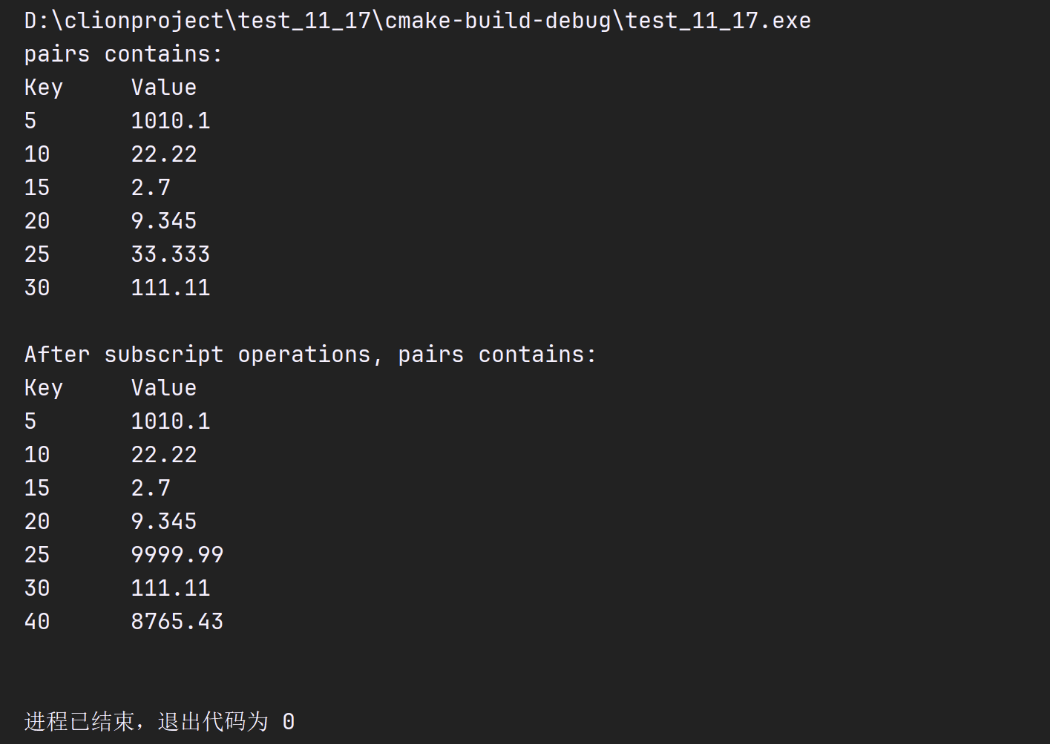
int main(){
map<int, double, less<int>> pairs;
// insert eight value_type objects in pairs
pairs.insert(make_pair(15, 2.7));
pairs.insert(make_pair(30, 111.11));
pairs.insert(make_pair(5, 1010.1));
pairs.insert(make_pair(10, 22.22));
pairs.insert(make_pair(25, 33.333));
pairs.insert(make_pair(5, 77.54)); // dup ignored
pairs.insert(make_pair(20, 9.345));
pairs.insert(make_pair(15, 99.3)); // dup ignored
cout << "pairs contains:\nKey\tValue\n";
// walk through elements of pairs
for (auto mapItem : pairs){
cout << mapItem.first << '\t' << mapItem.second << '\n';
}
pairs[25] = 9999.99;// use subscripting to change value for key 25
pairs[40] = 8765.43;// use subscripting to insert value for key 40
cout << "\nAfter subscript operations, pairs contains:\nKey\tValue\n";
// use const_iterator to walk through elements of pairs
for (auto mapItem : pairs){
cout << mapItem.first << '\t' << mapItem.second << '\n';
}
cout<<endl;
}
14.7 容器适配器
三种容器适配器分别为:stack,queue和priority_queue。容器适配器不支持迭代器。适配器类的好处是可以选择适当的基础数据结构。三种适配器都提供push和pop函数。

栈和队列的模板:
template <class T,class Sequence=deque<T> > class stack;//栈
template <class T,class FrontInsertionSequence=deque<T> > class queue;//队列
栈可以用任何一种顺序容器作为基础容器,而队列只允许使用前插顺序容器(双端队列deque或列表list)

14.7.1 stack
stack类来自头文件<stack>。允许在称为顶部的一端插入和删除,因此堆栈通常称为后进先出数据结构。
#include <iostream>
#include <stack>
#include <vector>
#include <list>
using namespace std;
// pushElements function-template prototype
template<typename T> void pushElements(T& stackRef);
// popElements function-template prototype
template<typename T> void popElements(T& stackRef);
int main(){
// stack with default underlying deque
stack<int> intDequeStack;
// stack with underlying vector
stack<int, vector<int>> intVectorStack;
// stack with underlying list
stack<int, list<int>> intListStack;
// push the values 0-9 onto each stack
cout << "Pushing onto intDequeStack: ";
pushElements(intDequeStack);
cout << "\nPushing onto intVectorStack: ";
pushElements(intVectorStack);
cout << "\nPushing onto intListStack: ";
pushElements(intListStack);
cout << endl << endl;
// display and remove elements from each stack
cout << "Popping from intDequeStack: ";
popElements(intDequeStack);
cout << "\nPopping from intVectorStack: ";
popElements(intVectorStack);
cout << "\nPopping from intListStack: ";
popElements(intListStack);
cout << endl;
}
// push elements onto stack object to which stackRef refers
template<typename T> void pushElements(T& stackRef){
for (int i{0}; i < 10; ++i){
stackRef.push(i); // push element onto stack
cout << stackRef.top() << ' '; // view (and display) top element
}
}
// pop elements from stack object to which stackRef refers
template<typename T> void popElements(T& stackRef){
while(!stackRef.empty()){
cout << stackRef.top() << ' '; // view (and display) top element
stackRef.pop(); // remove top element
}
}
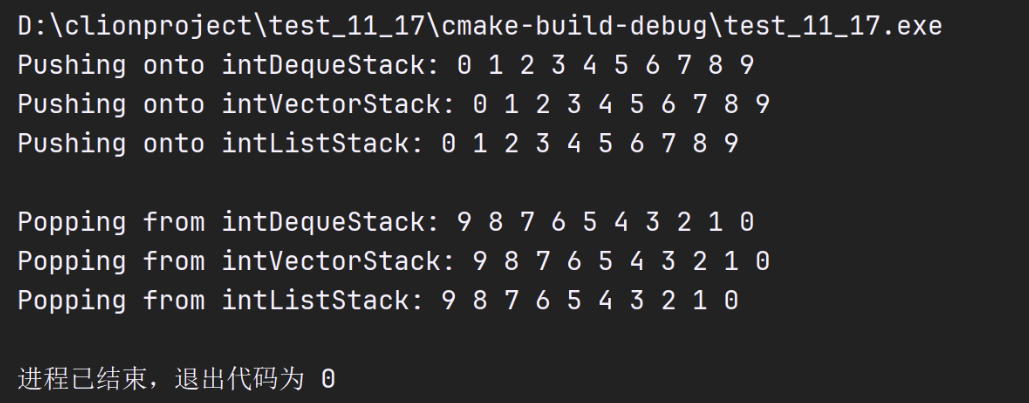
top函数并没有移除栈中的元素。pop函数移除位于栈顶部的元素,并不返回任何值。push函数向栈中添加元素,top函数显示位于栈顶的元素,pop函数移除位于栈顶部的元素。
14.7.2 queue
queue来自头文件<queue>,queue中停留时间最长的元素是下一个删除的元素,因此队列称为先进先出 (FIFO) 数据结构。queue只允许从后面插入新元素,从前面删除元素。

#include <iostream>
#include <queue>
using namespace std;
int main(){
queue<double> values; // queue with doubles
// push elements onto queue values
values.push(3.2);
values.push(9.8);
values.push(5.4);
cout << "Popping from values: ";
// pop elements from queue
while(!values.empty()){
cout << values.front() << ' '; // view front element
values.pop(); // remove element
}
cout<<endl;
}

14.7.3 priority_queue
priority_queue来自头文件<queue>。允许按排序后的顺序将元素插入到容器中,并从前面删除元素。默认情况下,priority_queue的元素存储在向量中。将元素添加到priority_queue时,它们将按优先级顺序插入,这样优先级最高的元素(即最大值)将成为从priority_queue中删除的第一个元素。这通常是通过在称为堆的数据结构中排列元素来实现的(不要与动态分配的内存的堆混淆),该堆始终在数据结构的前面保持最大值(即最高优先级的元素)。默认情况下,元素的比较是使用comparator function object less<T>,但您可以提供不同的比较器。

有几种常见的priority_queue操作。函数push根据priority_queue的优先级顺序在适当的位置插入元素,然后按优先级顺序对元素进行重新排序。函数 pop 删除priority_queue中优先级最高的元素。top 获取对 priority_queue 的 top 元素的引用(通过调用基础容器的函数 front 来实现)。empty 确定priority_queue是否为空(通过调用基础容器的函数 empty 来实现)。size 获取priority_queue中的元素数(通过调用基础容器的函数 size 实现)。
#include <iostream>
#include <queue>
using namespace std;
int main(){
priority_queue<double> priorities; // create priority_queue
// push elements onto priorities
priorities.push(3.2);
priorities.push(9.8);
priorities.push(5.4);
cout << "Popping from priorities: ";
// pop element from priority_queue
while(!priorities.empty()){
cout << priorities.top() << ' '; // view top element
priorities.pop(); // remove top element
}
cout<<endl;
}

14.8 bitset类
bitset是 C++ 标准库中的一个类,用于表示二进制位序列。它提供了一种方便的方式来处理二进制数据,尤其适用于位运算操作。表示一个固定长度的位序列,每个位都只能是 0 或 1。这个固定长度在创建对象时指定,并且不能在运行时更改。类似于整数类型,std::bitset 支持多种操作,包括位运算、位查询和位设置。
#include <bitset>
std::bitset<N> bitset1; // 创建一个长度为 N 的 bitset,所有位都被初始化为 0
std::bitset<N> bitset2(value); // 使用二进制整数 value 初始化一个长度为 N 的 bitset
std::bitset<N> bitset3(string); // 使用二进制字符串 string 初始化一个长度为 N 的 bitset
std::bitset<N> bitset4(bitset); // 使用另一个 bitset 初始化一个长度为 N 的 bitset
其中,value 是一个无符号整数,string 是一个只包含 '0' 和 '1' 的字符串,bitset 是另一个 std::bitset 对象。
size() 返回std::bitset 的长度count() 返回std::bitset 中值为 1 的位的数量any() 返回std::bitset 中是否存在值为 1 的位none() 返回std::bitset 中是否所有位都是 0all() 返回std::bitset 中是否所有位都是 1test(pos) 返回std::bitset 中位于pos 位置的值set(pos) 将std::bitset 中位于pos 位置的值设为 1reset(pos) 将std::bitset 中位于pos 位置的值设为 0flip(pos) 将std::bitset 中位于pos 位置的值取反to_ulong() 返回std::bitset 转换成的无符号整数值to_ullong() 返回std::bitset 转换成的无符号长整数值
std::bitset 重载了许多二进制运算符,如 &、|、^、~ 等,使其支持类似于整数类型的位运算操作。例如:
std::bitset<4> bitset1("1010");
std::bitset<4> bitset2("0110");
std::bitset<4> bitset3 = bitset1 & bitset2; // 按位与运算
std::bitset<4> bitset4 = bitset1 | bitset2; // 按位或运算
std::bitset<4> bitset5 = bitset1 ^ bitset2; // 按位异或运算
std::bitset<4> bitset6 = ~bitset
还可以使用左移、右移运算符进行位移操作:
std::bitset<4> bitset1("0101");
std::bitset<4> bitset2 = bitset1 << 2; // 左移 2 位,结果为 "010100"
std::bitset<4> bitset3 = bitset1 >> 1; // 右移 1 位,结果为 "0010"
std::bitset 还支持 to_string() 方法,将其转换成二进制字符串表示:
std::bitset<4> bitset1("1010");
std::string str = bitset1.to_string(); // "1010"
std::bitset 可以作为容器类型使用,可以使用下标访问、迭代器等方式访问其元素。
14.9 auto关键字
auto 是在变量定义的时候,用别人的类型作为自己类型的一种定义变量的方式。也叫做类型自动推断。
1.auto必须在定义的时候初始化。
int a = 1;
auto b = a;//b的类型为a的类型 int
auto b1;//编译器无法推导b1的类型
b1=10;//错误!
2.定义在一个auto序列的变量必须始终推导成同一类型
auto a1=10,a2=20;//正确
auto b1=20,b2=2.5//错误,没有推导为同一类型
3.如果初始化表达式是引用或const,则去除引用或cons语义。auto不管&和const
int a{10};int& b=a;
auto c=b;//c的类型为int而非int&
const int a1{90};
auto b1=a1;//b1的类型为int而非const int
4.如果auto关键字带上&号,则不去除引用或const语义。
int a{10};int& b=a;
auto& c=b;//c的类型为int&
const int a1{90};
auto& b1=a1;//b1的类型为const int
5.初始化表达式为数组时,auto关键字推导类型为指针。
int a3[3]={1,3,4};
auto b3=a3;
cout<<typeid(b3).name()<<endl;//输出为int*
6.若表达式为数组且auto带上&,则推导类型为数组类型。
int a3[3]={2,4,5};
auto& b7=a3;
cout<<typeid(b7).name()<<endl;//输出int [3]
7.C++14中,auto可以作为函数的返回值类型和参数类型。
8.要避免在一行中使用直接列表初始化和拷贝列表初始化。
auto x{1},y={2};//有问题,不要同时使用直接和拷贝列表初始化
示例:

auto最常用的场景是对于复杂类型的简化。
#include <iostream>
#include <typeinfo>
using std::cout;
using std::cin;
using std::endl;
auto max(int x,int y){
return x>y?x:y;
}
int main() {
//auto变量必须在定义时初始化
auto x=3;
auto y{42};//初始化列表的方式
//定义在一个auto序列的变量必须始终推导成为同一类型
auto x1{2},x2{7},x3{4};
//如果初始表达式是引用或者const,则去除引用或者const
int y1{4},&y2{y1};
auto y3{y2};
cout<<typeid(y3).name()<<endl;
//如果auto关键字带上&,则不去除引用或const语义
auto& z1{y2};
cout<<typeid(z1).name()<<endl;
//初始化表达式为数组时,auto关键字推导类型为指针
int p[3]{1,2,3};
auto p1=p;
cout<<typeid(p1).name()<<endl;
//若表达式为数组且auto带上&,则推导类型为是数组类型
auto& p2=p;
cout<<typeid(p2).name()<<endl;
//C++14中,auto可以作为函数的返回值类型和参数类型
cout<<max(x1,x2)<<endl;
return 0;
}
尽量使用auto关键字:
使用auto是为了代码的正确性、性能、可维护性、健壮性和方便性。
对于C++的原生数组,是不能使用auto直接做类型推断的。不可以使用auto关键字来定义数组的类型。
auto a[3]{1,4,6};//错误!
14.10 decltype关键字
利用已知类型声明新变量,在编译时期推导一个表达式的类型,而不用初始化,语法格式有些像sizeof
decltype主要用于泛型编程
代码示例:
#include <iostream>
using namespace std;
int fun1(){
return 10;
}
auto fun2(){
return 'g';
}//C++14
int main(){
decltype(fun1()) x;//不会执行fun1()函数
decltype(fun2()) y=fun2();
cout<<typeid(x).name()<<endl;
cout<<typeid(y).name()<<endl;
return 0;
}
decltype和auto都是C++11自动类型推导的关键字。它们有很多差别:
- auto忽略最上层的const,decltype则保留最上层的const
- auto忽略原有类型的引用,decltype则保留原有类型的引用
- 对解引用操作,auto推断出原有类型,decltype推断出引用;
- auto推断时会实际执行,decltype不会执行,只做分析。
- 总之在使用中过程中和const、引用和指针结合时需要特别小心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号