flink state专项练习
目录
简介
flink state 毫不夸张的讲是 flink最核心的功能,个人理解是比 spark强大百倍的最关键实现,既然如此核心,所以接下来就进行专项练习以求彻底搞懂并且学习。
案例执行
测试代码
public class TestKeyedStateMain {
public static void main(String[] args) {
//程序入口
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//数据源
DataStreamSource<Tuple2<Long, Long>> dataStreamSource =
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(1L, 5L),Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
// new AggregatingStateContainValue() 可以依据不同的测试, new 不同的对象
SingleOutputStreamOperator<Tuple2<Long, String>> tuple2SingleOutputStreamOperator = dataStreamSource.keyBy(0).flatMap(new AggregatingStateContainValue());
tuple2SingleOutputStreamOperator.print();
try {
env.execute("TestKeyedStateMain");
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用ValueState 计算窗口平均值
public class CountWindowAverageWithValueState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
private ValueState<Tuple2<Long, Long>> countAndSum;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Tuple2<Long, Long>> average = new ValueStateDescriptor<>(
"average",
Types.TUPLE(Types.LONG, Types.LONG)
);
countAndSum = getRuntimeContext().getState(average);
}
/**
* state tuple f1+count f2 + value
* @param value
* @param out
* @throws Exception
*/
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Double>> out) throws Exception {
Tuple2<Long, Long> valueStateTuple = countAndSum.value();
if (valueStateTuple==null) {
valueStateTuple = new Tuple2<>(0L, 0L);
}
valueStateTuple.f0 += 1;
valueStateTuple.f1 += value.f1;
countAndSum.update(valueStateTuple);
if (valueStateTuple.f0>=3) {
//每三个元素触发计算
double v = valueStateTuple.f1 / (double) valueStateTuple.f0;
out.collect(Tuple2.of(value.f0,v));
//触发之后清除状态
countAndSum.clear();
}
}
}
触发效果:

使用 ListState 计算窗口平均值
public class CountWindowAverageWithListState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
private ListState<Tuple2<Long, Long>> elementsByKey;
@Override
public void open(Configuration parameters) throws Exception {
ListStateDescriptor<Tuple2<Long, Long>> average = new ListStateDescriptor<>(
"average",
Types.TUPLE(Types.LONG, Types.LONG)
);
elementsByKey = getRuntimeContext().getListState(average);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Double>> out) throws Exception {
// list state 直接 add tuple
elementsByKey.add(value);
List<Tuple2<Long, Long>> listStateResult = Lists.newArrayList(elementsByKey.get());
if (listStateResult.size()>=3) {
int size = listStateResult.size();
Long aLong1 = listStateResult.stream().map(longLongTuple2 -> longLongTuple2.f1).reduce((aLong, aLong2) -> aLong + aLong2).get();
double v = aLong1 / (double)size;
out.collect(Tuple2.of(value.f0, v));
// 清除 list state 状态
elementsByKey.clear();
}
}
}
触发效果:

使用 MapState 计算窗口平均值
public class CountWindowAverageWithMapState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
private MapState<String, Long> mapState;
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
MapStateDescriptor<String, Long> descriptor =
new MapStateDescriptor<String, Long>(
"average", // 状态的名字
String.class, Long.class); // 状态存储的数据类型
mapState = getRuntimeContext().getMapState(descriptor);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Double>> out) throws Exception {
mapState.put(UUID.randomUUID().toString(), value.f1);
List<Long> longs = Lists.newArrayList(mapState.values());
if (longs.size()>=3) {
int size = longs.size();
Long aLong1 = longs.stream().reduce((aLong, aLong2) -> aLong + aLong2).get();
double v = aLong1 / (double)size;
out.collect(Tuple2.of(value.f0, v));
mapState.clear();
}
}
}
触发效果:

使用 AggregatingState 实现 字符串拼装游戏
public class AggregatingStateContainValue extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, String>> {
/**
* 1, contains:3 and 5
*/
private AggregatingState<Long, String> totalStr;//辅助字段
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
AggregatingStateDescriptor<Long, String, String> descriptor =
new AggregatingStateDescriptor<Long, String, String>(
"totalStr", // 状态的名字
//SparkSQL 自定义聚合函数
new AggregateFunction<Long, String, String>() {
//初始化的操作,只运行一次哦
@Override
public String createAccumulator() {
return "Contains:";
}
// 字符 拼凑
@Override
public String add(Long value, String accumulator) {
if ("Contains:".equals(accumulator)) {
return accumulator + value;
}
return accumulator + " and " + value;
}
// 不同 slot的结果 merge
@Override
public String merge(String a, String b) {
return a + " and " + b;
}
// 得到最终结果
@Override
public String getResult(String accumulator) {
//contains:1
//contains: 1 and 3 and
return accumulator;
}
}, String.class); // 状态存储的数据类型
totalStr = getRuntimeContext().getAggregatingState(descriptor);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, String>> out) throws Exception {
totalStr.add(value.f1);
out.collect(Tuple2.of(value.f0, totalStr.get()));
}
}
触发效果:
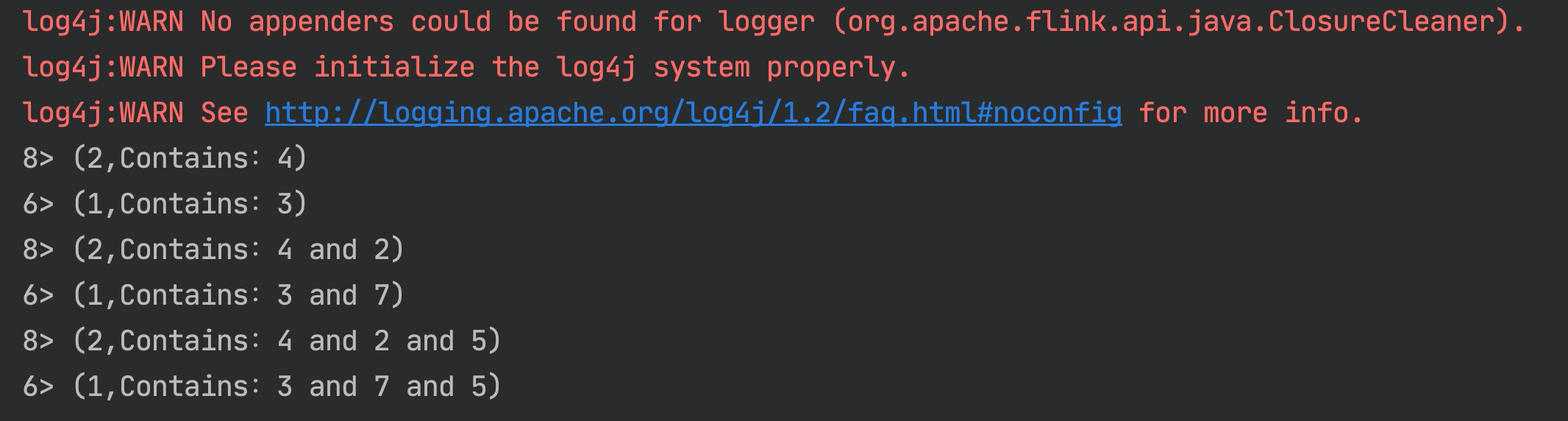
使用 ReducingState 实现数字累加效果
public class ReducingStateSumFunction
extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
//sum = 最终累加的结果的数据类型
private ReducingState<Long> sumState;
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
ReducingStateDescriptor<Long> descriptor =
new ReducingStateDescriptor<Long>(
"sum", // 状态的名字
new ReduceFunction<Long>() { // 聚合函数
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
}, Long.class); // 状态存储的数据类型
sumState = getRuntimeContext().getReducingState(descriptor);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
sumState.add(value.f1);
out.collect(Tuple2.of(value.f0, sumState.get()));
}
}
触发效果:

总结
以上刻意练习绝对会对 flink state 的使用,得心应手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号