
kudu介绍
概述
为什么需要这种存储 ?
- 静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。 这类存储的局限性是数据无法进行随
机的读写。 就是不支持按照行去检索, 不支持行级别的update 和 delete - 动态数据:以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。局限性是批量读取吞吐量远不如
HDFS,不适用于批量数据分析的场景。 适合大数据量的按行检索,但是批量分析能力弱,尤其SQL表现弱

大数据的特点就是涉及到的存储非常多,所以尤其需要一个存储搞定一切, 简化使用成本和减少一致性问题。 KUDU 就是这类问题的救星。
对此业界常用解决方案如下:
就是数据只是存储在 HBASE中满足 按照快速检索的需求,同时对于复杂SQL分析场景,采取hive 建外表的方式,把 HBASE 的 rowkey 、 column family 、column 映射成hive的字段,便于SQL的自定义分析。
外表的方式,查询的时候还是把SQL翻译成功 MR任务去执行的, 由于存储受限还是无法改变 HBASE 不善于做大批量数据分析的需求。

业界还有一种解决方案如下:
如上图所示,数据实时写入 HBase,实时的数据更新也在 HBase 完成,为了应对 OLAP 需求,我们定
时将 HBase 数据写成静态的文件(如:Parquet)导入到 OLAP 引擎(如:Impala、Hive)。这一架
构能满足既需要随机读写,又可以支持 OLAP 分析的场景,但他有如下缺点:
- 数据还是存储多份,存在一致性问题,运维成本高
- 时效性低,从HBASE导出成 parquet文件是周期性的,一般是一天或者一小时
- 每次发生数据更新都需要 覆盖写parquet 文件。

Kudu 应运而生。Kudu 的定位是 Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。 业界也有很多人把 kudu作为实时数仓去使用, 全部导入 KUDU,不再使用 hive那一套。
数据时效性好,运维也简单。
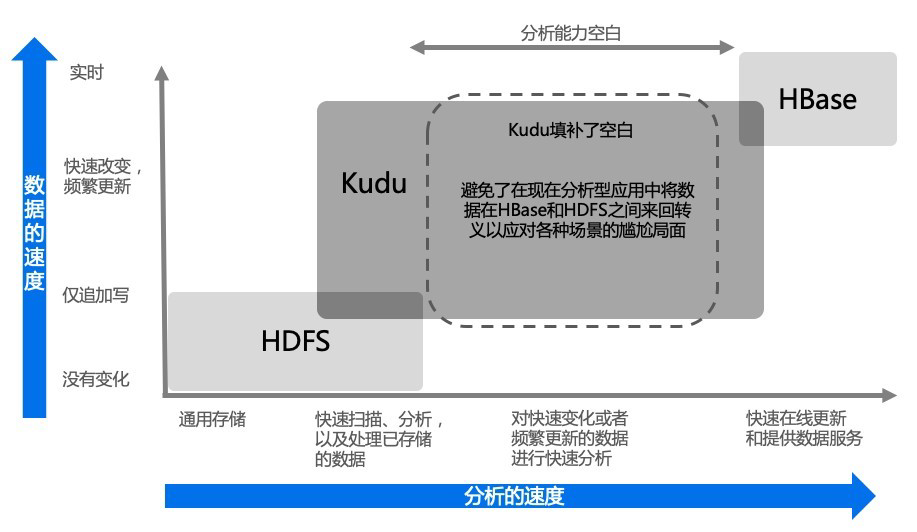
借用官网的图片如下:
Kudu 是一个折中的产品,在 HDFS 和 HBase 这两个偏科生中平衡了随机读写和批量分析的性能。

当然 Kudu 身上还有很多概念或者标签,有分布式文件系统(好比 HDFS),有一致性算法(好比
Zookeeper),有 Table(好比 Hive Table),有 Tablet(好比 Hive Table Partition),有列式存储
(好比 Parquet),有顺序和随机读取(好比 HBase),所以看起来 Kudu 是一个轻量级的 HDFS +
Zookeeper + Hive + Parquet + HBase,除此之外,Kudu 还有自己的特点,快速写入+读取,使得
kudu + Impala 非常适合 OLAP 场景,尤其是 Time-series 场景。

Kudu 是一个分布式列式存储引擎/系统,官方给 Kudu 的定位是:在更新更及时的基础上实现更快的数据分析
Kudu 的特性决定了它适合以下场景:
1、适用于那些既有随机访问,也有批量数据扫描的复合场景
2、CPU 密集型的场景
3、使用了高性能的存储设备,包括使用更多的内存
4、要求支持数据更新,避免数据反复迁移的场景
5、支持跨地域的实时数据备份和查询
缺点:
(1)只有主键可以设置 range 分区,且只能由一个主键,也就是一个表只能有一个字段 range 分区,
且该字段必须是主键。
(2)如果是 pyspark 连接 kudu,则不能对 kudu 进行额外的操作;而 scala 的 spark 可以调用 kudu
本身的库,支持 kudu 的各种语法。
(3)kudu 的 shell 客户端不提供表 schema 查看。如果你不通过 imapla 连接 kudu,且想要查看表
的元数据信息,需要用 spark 加载数据为 dataframe,通过查看 dataframe 的 schema 查看表的元数
据信息。
(3)kudu 的 shell 客户端不提供表内容查看。如果你想要表的据信息,要么自己写脚本,要么通过
spark、imapla 查看。
(4)如果使用 range 分区需要手动添加分区。假设 id 为分区字段,需要手动设置第一个分区为 1-
30,第二个分区为 30-60 等等
(5)时间格式是 utc 类型,需要将时间戳转化为 utc 类型,注意 8 个小时时差
Kudu 和 RDBMS 对比
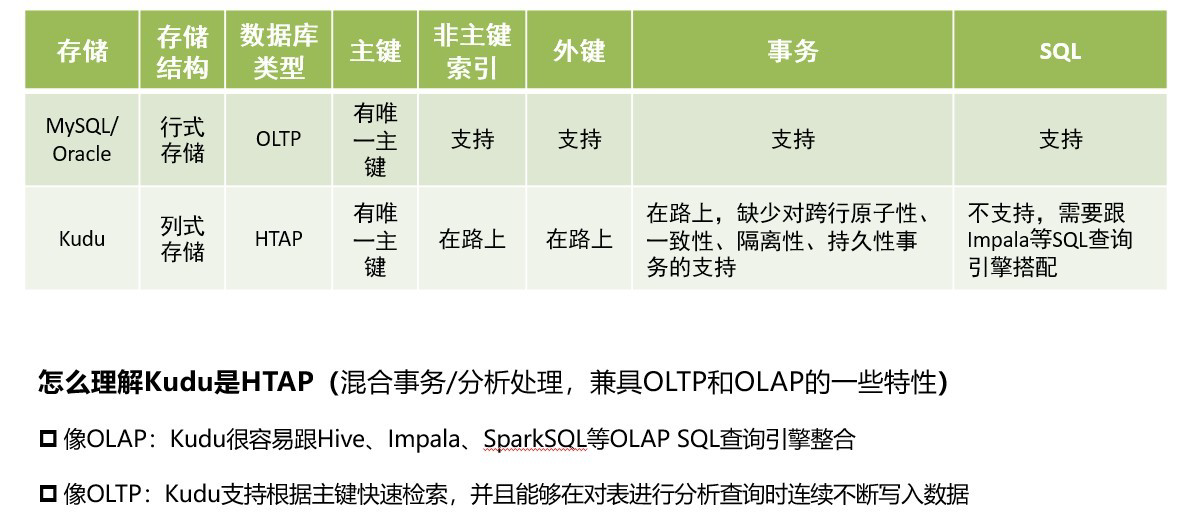
总之一句话: 如果你正在找寻一款既支持实时查询又支持大规模数据分析和机器学习场景的存储,Kudu 将是一 个很
好的选择,它将在搞定需求的同时极大降低运维复杂度。
高层架构
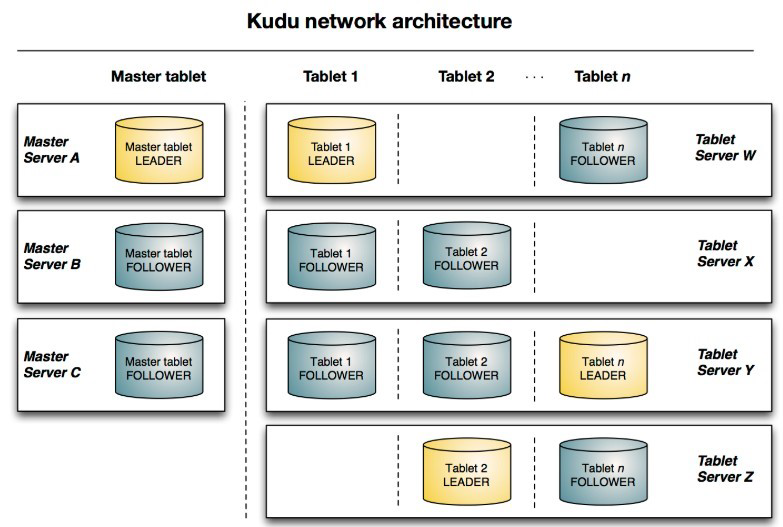
跟 HBase 类似,Kudu 是典型的主从架构。一个 Kudu 集群由主节点即 Master 和若干个从节
点即 Tablet Server 组成。Master 负责管理集群的元数据(类似于 HBase 的 Master),Tablet
Server 负责数据存储(类似 HBase 的 RegionServer)。在生产环境,一般部署多个 Master 实现高可
用(奇数个、典型的是 3 个),Tablet Server 一般也是奇数个。
Table 表
表具有 schema(表结构)和全局有序的 primary key(主键)。table 被水平分成很多段,每个段称为Tablet。
Tablet:
分区,一张表的所有 tablet 包含了这张表的所有 key 空间。
Tablet Server:
Tablet server 是 Kudu 集群中的从节点,负责数据存储,并提供数据读写服务。
Master:
集群中的主节点,负责集群管理、元数据管理等功能。
保持跟踪所有的 tablets、tablet servers、catalog tables(目录表)和其它与集群相关的 metadata。
在给定的时间点,只能有一个起作用的 Master(也就是 leader)。

