
Bert结构手动矩阵运算实现(Transform)
- 安装torch, transformers, loguru(本代码实现为下方版本,其余版本实现可比葫芦画瓢自行摸索)
pip install torch==1.13.1 transformers==4.44.1 numpy==1.26.4 loguru -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 模型文件下载
git clone https://huggingface.co/google-bert/bert-base-chinese
- 查看config.json配置文件
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
- Bert基础使用demo
import os
import torch
from transformers import BertModel, BertTokenizer
from loguru import logger
# 根据本机路径进行配置
bert_path = os.getenv('BERT')
bert = BertModel.from_pretrained(bert_path)
tokenizer = BertTokenizer.from_pretrained(bert_path)
test_sentence = '我爱你中国'
sequence = tokenizer.encode(test_sentence)
logger.info(sequence)
# [101, 2769, 4263, 872, 704, 1744, 102]
bert_outputs = bert(torch.LongTensor([sequence]))
logger.info(bert_outputs)
# BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.0292, -0.0562, -0.2319, ..., 0.0534, -0.0731, -0.0275],
# [ 0.6254, -0.4651, 0.4586, ..., -1.2470, -0.2022, -1.1478],
# [ 0.7475, -0.4633, -0.7398, ..., -0.8775, 0.0355, 0.2711],
# ...,
# [ 0.0776, -1.0977, -0.2756, ..., -0.9747, 0.0518, -1.8880],
# [-0.0557, -0.1744, 0.0198, ..., -0.7572, 0.0585, -0.4321],
# [-0.1134, 0.1983, 0.1888, ..., -0.7413, -0.2794, 0.5925]]],
# grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[ 2.9230e-01, 7.8951e-01, -8.0105e-01, 1.3462e-01, 6.6218e-01,
# 7.1210e-01, -3.7434e-01, -7.1144e-01, 4.6700e-01, -7.4768e-01,
# 8.3907e-01, -8.7077e-01, -9.1680e-02, -5.9788e-01, 9.2169e-01,
# -7.8650e-01, -7.1573e-01, 3.4637e-01, -1.2762e-01, 5.0850e-01,
# 8.9458e-01, -3.0531e-01, -4.1609e-01, 6.2962e-01, 7.7016e-01,
# 5.6260e-01, -1.4025e-01, -6.1368e-01, -9.9234e-01, -1.1799e-02,
# 1.2729e-01, 7.9623e-01, -4.6566e-01, -9.9089e-01, -2.3516e-01,
# ......
# -2.8310e-01, -4.3994e-01, 7.7100e-01]], grad_fn=<TanhBackward0>), hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)
- 导包实现必需的激活函数并拿出相关权重值
import os
from transformers import BertModel, BertConfig
import numpy as np
import math
from loguru import logger
# 根据本机模型文件路径进行配置
bert_path = os.getenv('BERT')
bert = BertModel.from_pretrained(bert_path)
state_dict = bert.state_dict()
logger.info(state_dict.keys())
# odict_keys(['embeddings.word_embeddings.weight', 'embeddings.position_embeddings.weight', 'embeddings.token_type_embeddings.weight', 'embeddings.LayerNorm.weight', 'embeddings.LayerNorm.bias',
'encoder.layer.0.attention.self.query.weight', 'encoder.layer.0.attention.self.query.bias', 'encoder.layer.0.attention.self.key.weight', 'encoder.layer.0.attention.self.key.bias', 'encoder.layer.0.attention.self.value.weight', 'encoder.layer.0.attention.self.value.bias', 'encoder.layer.0.attention.output.dense.weight', 'encoder.layer.0.attention.output.dense.bias', 'encoder.layer.0.attention.output.LayerNorm.weight', 'encoder.layer.0.attention.output.LayerNorm.bias', 'encoder.layer.0.intermediate.dense.weight', 'encoder.layer.0.intermediate.dense.bias', 'encoder.layer.0.output.dense.weight', 'encoder.layer.0.output.dense.bias', 'encoder.layer.0.output.LayerNorm.weight', 'encoder.layer.0.output.LayerNorm.bias',
'encoder.layer.1.attention.self.query.weight', 'encoder.layer.1.attention.self.query.bias', 'encoder.layer.1.attention.self.key.weight', 'encoder.layer.1.attention.self.key.bias', 'encoder.layer.1.attention.self.value.weight', 'encoder.layer.1.attention.self.value.bias', 'encoder.layer.1.attention.output.dense.weight', 'encoder.layer.1.attention.output.dense.bias', 'encoder.layer.1.attention.output.LayerNorm.weight', 'encoder.layer.1.attention.output.LayerNorm.bias', 'encoder.layer.1.intermediate.dense.weight', 'encoder.layer.1.intermediate.dense.bias', 'encoder.layer.1.output.dense.weight', 'encoder.layer.1.output.dense.bias', 'encoder.layer.1.output.LayerNorm.weight', 'encoder.layer.1.output.LayerNorm.bias',
'encoder.layer.2.attention.self.query.weight', 'encoder.layer.2.attention.self.query.bias', 'encoder.layer.2.attention.self.key.weight', 'encoder.layer.2.attention.self.key.bias', 'encoder.layer.2.attention.self.value.weight', 'encoder.layer.2.attention.self.value.bias', 'encoder.layer.2.attention.output.dense.weight', 'encoder.layer.2.attention.output.dense.bias', 'encoder.layer.2.attention.output.LayerNorm.weight', 'encoder.layer.2.attention.output.LayerNorm.bias', 'encoder.layer.2.intermediate.dense.weight', 'encoder.layer.2.intermediate.dense.bias', 'encoder.layer.2.output.dense.weight', 'encoder.layer.2.output.dense.bias', 'encoder.layer.2.output.LayerNorm.weight', 'encoder.layer.2.output.LayerNorm.bias',
'encoder.layer.3.attention.self.query.weight', 'encoder.layer.3.attention.self.query.bias', 'encoder.layer.3.attention.self.key.weight', 'encoder.layer.3.attention.self.key.bias', 'encoder.layer.3.attention.self.value.weight', 'encoder.layer.3.attention.self.value.bias', 'encoder.layer.3.attention.output.dense.weight', 'encoder.layer.3.attention.output.dense.bias', 'encoder.layer.3.attention.output.LayerNorm.weight', 'encoder.layer.3.attention.output.LayerNorm.bias', 'encoder.layer.3.intermediate.dense.weight', 'encoder.layer.3.intermediate.dense.bias', 'encoder.layer.3.output.dense.weight', 'encoder.layer.3.output.dense.bias', 'encoder.layer.3.output.LayerNorm.weight', 'encoder.layer.3.output.LayerNorm.bias',
'encoder.layer.4.attention.self.query.weight', 'encoder.layer.4.attention.self.query.bias', 'encoder.layer.4.attention.self.key.weight', 'encoder.layer.4.attention.self.key.bias', 'encoder.layer.4.attention.self.value.weight', 'encoder.layer.4.attention.self.value.bias', 'encoder.layer.4.attention.output.dense.weight', 'encoder.layer.4.attention.output.dense.bias', 'encoder.layer.4.attention.output.LayerNorm.weight', 'encoder.layer.4.attention.output.LayerNorm.bias', 'encoder.layer.4.intermediate.dense.weight', 'encoder.layer.4.intermediate.dense.bias', 'encoder.layer.4.output.dense.weight', 'encoder.layer.4.output.dense.bias', 'encoder.layer.4.output.LayerNorm.weight', 'encoder.layer.4.output.LayerNorm.bias',
'encoder.layer.5.attention.self.query.weight', 'encoder.layer.5.attention.self.query.bias', 'encoder.layer.5.attention.self.key.weight', 'encoder.layer.5.attention.self.key.bias', 'encoder.layer.5.attention.self.value.weight', 'encoder.layer.5.attention.self.value.bias', 'encoder.layer.5.attention.output.dense.weight', 'encoder.layer.5.attention.output.dense.bias', 'encoder.layer.5.attention.output.LayerNorm.weight', 'encoder.layer.5.attention.output.LayerNorm.bias', 'encoder.layer.5.intermediate.dense.weight', 'encoder.layer.5.intermediate.dense.bias', 'encoder.layer.5.output.dense.weight', 'encoder.layer.5.output.dense.bias', 'encoder.layer.5.output.LayerNorm.weight', 'encoder.layer.5.output.LayerNorm.bias',
'encoder.layer.6.attention.self.query.weight', 'encoder.layer.6.attention.self.query.bias', 'encoder.layer.6.attention.self.key.weight', 'encoder.layer.6.attention.self.key.bias', 'encoder.layer.6.attention.self.value.weight', 'encoder.layer.6.attention.self.value.bias', 'encoder.layer.6.attention.output.dense.weight', 'encoder.layer.6.attention.output.dense.bias', 'encoder.layer.6.attention.output.LayerNorm.weight', 'encoder.layer.6.attention.output.LayerNorm.bias', 'encoder.layer.6.intermediate.dense.weight', 'encoder.layer.6.intermediate.dense.bias', 'encoder.layer.6.output.dense.weight', 'encoder.layer.6.output.dense.bias', 'encoder.layer.6.output.LayerNorm.weight', 'encoder.layer.6.output.LayerNorm.bias',
'encoder.layer.7.attention.self.query.weight', 'encoder.layer.7.attention.self.query.bias', 'encoder.layer.7.attention.self.key.weight', 'encoder.layer.7.attention.self.key.bias', 'encoder.layer.7.attention.self.value.weight', 'encoder.layer.7.attention.self.value.bias', 'encoder.layer.7.attention.output.dense.weight', 'encoder.layer.7.attention.output.dense.bias', 'encoder.layer.7.attention.output.LayerNorm.weight', 'encoder.layer.7.attention.output.LayerNorm.bias', 'encoder.layer.7.intermediate.dense.weight', 'encoder.layer.7.intermediate.dense.bias', 'encoder.layer.7.output.dense.weight', 'encoder.layer.7.output.dense.bias', 'encoder.layer.7.output.LayerNorm.weight', 'encoder.layer.7.output.LayerNorm.bias',
'encoder.layer.8.attention.self.query.weight', 'encoder.layer.8.attention.self.query.bias', 'encoder.layer.8.attention.self.key.weight', 'encoder.layer.8.attention.self.key.bias', 'encoder.layer.8.attention.self.value.weight', 'encoder.layer.8.attention.self.value.bias', 'encoder.layer.8.attention.output.dense.weight', 'encoder.layer.8.attention.output.dense.bias', 'encoder.layer.8.attention.output.LayerNorm.weight', 'encoder.layer.8.attention.output.LayerNorm.bias', 'encoder.layer.8.intermediate.dense.weight', 'encoder.layer.8.intermediate.dense.bias', 'encoder.layer.8.output.dense.weight', 'encoder.layer.8.output.dense.bias', 'encoder.layer.8.output.LayerNorm.weight', 'encoder.layer.8.output.LayerNorm.bias',
'encoder.layer.9.attention.self.query.weight', 'encoder.layer.9.attention.self.query.bias', 'encoder.layer.9.attention.self.key.weight', 'encoder.layer.9.attention.self.key.bias', 'encoder.layer.9.attention.self.value.weight', 'encoder.layer.9.attention.self.value.bias', 'encoder.layer.9.attention.output.dense.weight', 'encoder.layer.9.attention.output.dense.bias', 'encoder.layer.9.attention.output.LayerNorm.weight', 'encoder.layer.9.attention.output.LayerNorm.bias', 'encoder.layer.9.intermediate.dense.weight', 'encoder.layer.9.intermediate.dense.bias', 'encoder.layer.9.output.dense.weight', 'encoder.layer.9.output.dense.bias', 'encoder.layer.9.output.LayerNorm.weight', 'encoder.layer.9.output.LayerNorm.bias',
'encoder.layer.10.attention.self.query.weight', 'encoder.layer.10.attention.self.query.bias', 'encoder.layer.10.attention.self.key.weight', 'encoder.layer.10.attention.self.key.bias', 'encoder.layer.10.attention.self.value.weight', 'encoder.layer.10.attention.self.value.bias', 'encoder.layer.10.attention.output.dense.weight', 'encoder.layer.10.attention.output.dense.bias', 'encoder.layer.10.attention.output.LayerNorm.weight', 'encoder.layer.10.attention.output.LayerNorm.bias', 'encoder.layer.10.intermediate.dense.weight', 'encoder.layer.10.intermediate.dense.bias', 'encoder.layer.10.output.dense.weight', 'encoder.layer.10.output.dense.bias', 'encoder.layer.10.output.LayerNorm.weight', 'encoder.layer.10.output.LayerNorm.bias',
'encoder.layer.11.attention.self.query.weight', 'encoder.layer.11.attention.self.query.bias', 'encoder.layer.11.attention.self.key.weight', 'encoder.layer.11.attention.self.key.bias', 'encoder.layer.11.attention.self.value.weight', 'encoder.layer.11.attention.self.value.bias', 'encoder.layer.11.attention.output.dense.weight', 'encoder.layer.11.attention.output.dense.bias', 'encoder.layer.11.attention.output.LayerNorm.weight', 'encoder.layer.11.attention.output.LayerNorm.bias', 'encoder.layer.11.intermediate.dense.weight', 'encoder.layer.11.intermediate.dense.bias', 'encoder.layer.11.output.dense.weight', 'encoder.layer.11.output.dense.bias', 'encoder.layer.11.output.LayerNorm.weight', 'encoder.layer.11.output.LayerNorm.bias',
'pooler.dense.weight', 'pooler.dense.bias'])
config = BertConfig.from_pretrained(bert_path)
logger.info(config)
# BertConfig {
# "architectures": [
# "BertForMaskedLM"
# ],
# "attention_probs_dropout_prob": 0.1,
# "classifier_dropout": null,
# "directionality": "bidi",
# "hidden_act": "gelu",
# "hidden_dropout_prob": 0.1,
# "hidden_size": 768,
# "initializer_range": 0.02,
# "intermediate_size": 3072,
# "layer_norm_eps": 1e-12,
# "max_position_embeddings": 512,
# "model_type": "bert",
# "num_attention_heads": 12,
# "num_hidden_layers": 12,
# "pad_token_id": 0,
# "pooler_fc_size": 768,
# "pooler_num_attention_heads": 12,
# "pooler_num_fc_layers": 3,
# "pooler_size_per_head": 128,
# "pooler_type": "first_token_transform",
# "position_embedding_type": "absolute",
# "transformers_version": "4.44.1",
# "type_vocab_size": 2,
# "use_cache": true,
# "vocab_size": 21128
# }
# softmax归一化
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True)
# gelu激活函数
def gelu(x):
return 0.5 * x * (1 + np.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * np.power(x, 3))))
-
Bert参考:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding -
定义类并接收相关权重值
class DiyBert:
def __init__(self):
self.state_dict = state_dict
self.config = config
- Bert embedding层实现
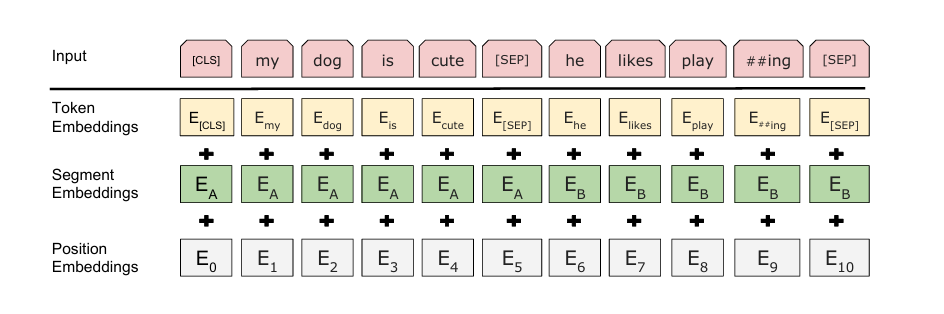
Bert embedding实现有三层,以下为三层embedding的代码实现(实现顺序为上图从上到下)
def get_word_embedding(self, x):
word_embeddings = self.state_dict["embeddings.word_embeddings.weight"].numpy()
return np.array([word_embeddings[index] for index in x])
def get_token_type_embeddings(self, x):
token_type_embeddings = self.state_dict["embeddings.token_type_embeddings.weight"].numpy()
return np.array([token_type_embeddings[index] for index in [0]*len(x)])
def get_position_embedding(self, x):
position_embeddings = self.state_dict["embeddings.position_embeddings.weight"].numpy()
return np.array([position_embeddings[index] for index in range(len(x))])
层归一化,此处实现三层embedding加和以及层归一化
def layer_norm(self, x, w, b):
x = (x - np.mean(x, axis=1, keepdims=True)) / np.std(x, axis=1, keepdims=True)
x = x * w + b
return x
def embedding(self, x):
"""
三层embeding加和
word embedding
token embedding
position embedding
:param x:
:return:
"""
x_word = self.get_word_embedding(x)
x_token = self.get_token_type_embeddings(x)
x_position = self.get_position_embedding(x)
w = self.state_dict["embeddings.LayerNorm.weight"].numpy()
b = self.state_dict["embeddings.LayerNorm.bias"].numpy()
return self.layer_norm(x_word + x_token + x_position, w, b)
- Transformer参考
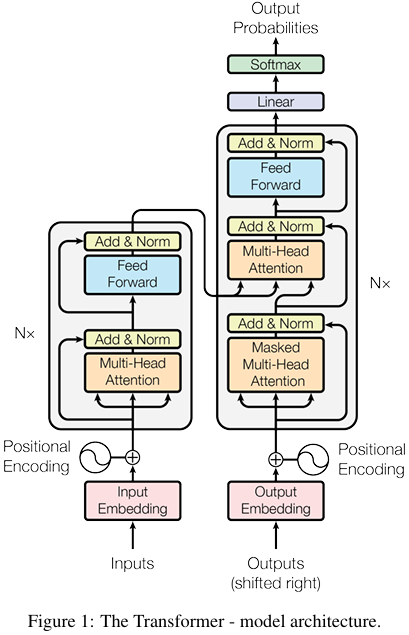
- Transformer层实现
def self_attention(self, x, q_w, q_b, k_w, k_b, v_w, v_b, attention_output_w, attention_output_b):
num_attention_heads = config.num_attention_heads
hidden_size = config.hidden_size
attention_heads_size = int(hidden_size / num_attention_heads)
_len, hidden_size = x.shape
q = np.dot(x, q_w.T) + q_b
q = q.reshape(_len, num_attention_heads, attention_heads_size)
q = q.swapaxes(1, 0)
k = np.dot(x, k_w.T) + k_b
k = k.reshape(_len, num_attention_heads, attention_heads_size)
k = k.swapaxes(1, 0)
v = np.dot(x, v_w.T) + v_b
v = v.reshape(_len, num_attention_heads, attention_heads_size)
v = v.swapaxes(1, 0)
qk = np.matmul(q, k.swapaxes(1, 2))
qk /= np.sqrt(attention_heads_size)
qk = softmax(qk)
qkv = np.matmul(qk, v)
qkv = qkv.swapaxes(0, 1).reshape(-1, hidden_size)
attention = np.dot(qkv, attention_output_w.T) + attention_output_b
return attention
def feed_forward(self, x, intermediate_weight, intermediate_bias, output_weight, output_bias):
x = np.dot(x, intermediate_weight.T) + intermediate_bias
x = gelu(x)
x = np.dot(x, output_weight.T) + output_bias
return x
def single_transform(self, x, layer_index):
q_w = self.state_dict[f'encoder.layer.{layer_index}.attention.self.query.weight'].numpy()
q_b = self.state_dict[f'encoder.layer.{layer_index}.attention.self.query.bias'].numpy()
k_w = self.state_dict[f'encoder.layer.{layer_index}.attention.self.key.weight'].numpy()
k_b = self.state_dict[f'encoder.layer.{layer_index}.attention.self.key.bias'].numpy()
v_w = self.state_dict[f'encoder.layer.{layer_index}.attention.self.value.weight'].numpy()
v_b = self.state_dict[f'encoder.layer.{layer_index}.attention.self.value.bias'].numpy()
attention_output_w = self.state_dict[f'encoder.layer.{layer_index}.attention.output.dense.weight'].numpy()
attention_output_b = self.state_dict[f'encoder.layer.{layer_index}.attention.output.dense.bias'].numpy()
# self_attention
attention_output = self.self_attention(x, q_w, q_b, k_w, k_b, v_w, v_b, attention_output_w, attention_output_b)
attention_layer_norm_w = state_dict[f'encoder.layer.{layer_index}.attention.output.LayerNorm.weight'].numpy()
attention_layer_norm_b = state_dict[f'encoder.layer.{layer_index}.attention.output.LayerNorm.bias'].numpy()
# 残差机制: x + attention_output; 层归一化
x = self.layer_norm(x + attention_output, attention_layer_norm_w, attention_layer_norm_b)
intermediate_weight = self.state_dict[f'encoder.layer.{layer_index}.intermediate.dense.weight'].numpy()
intermediate_bias = self.state_dict[f'encoder.layer.{layer_index}.intermediate.dense.bias'].numpy()
output_weight = self.state_dict[f'encoder.layer.{layer_index}.output.dense.weight'].numpy()
output_bias = self.state_dict[f'encoder.layer.{layer_index}.output.dense.bias'].numpy()
# feed_forward层, 线性层+gelu+线性层
feed_forward_x = self.feed_forward(x, intermediate_weight, intermediate_bias, output_weight, output_bias)
feed_forward_layer_norm_w = state_dict[f'encoder.layer.{layer_index}.output.LayerNorm.weight'].numpy()
feed_forward_layer_norm_b = state_dict[f'encoder.layer.{layer_index}.output.LayerNorm.bias'].numpy()
# 残差机制: x + feed_forward_x; 层归一化
x = self.layer_norm(x + feed_forward_x, feed_forward_layer_norm_w, feed_forward_layer_norm_b)
return x
def all_transform(self, x):
for i in range(config.num_hidden_layers):
x = self.single_transform(x, i)
- 输出为两个输出, 一个是去cls对应的输出token过pooler层
def pooler(self, x):
pooler_dense_weight = self.state_dict["pooler.dense.weight"].numpy()
pooler_dense_bias = self.state_dict["pooler.dense.bias"].numpy()
x = np.dot(x, pooler_dense_weight.T) + pooler_dense_bias
x = np.tanh(x)
return x
def forward(self, x):
x = self.embedding(x)
x = self.all_transform(x)
# 取clstoken过pooler
pooler_output = self.pooler(x[0])
return x, pooler_output
- 输出结果对比验证
if __name__ == '__main__':
test_sequence = np.array([101, 2769, 4263, 872, 704, 1744, 102])
diy_bert = DiyBert()
logger.info(diy_bert.forward(test_sequence))
# (array([[ 0.02919707, -0.05620748, -0.23188461, ..., 0.05366788,
# -0.07292913, -0.02798794],
# [ 0.62560517, -0.4647462 , 0.4585261 , ..., -1.2470298 ,
# -0.20228532, -1.1482794 ],
# [ 0.74754083, -0.46312463, -0.7397772 , ..., -0.8773532 ,
# 0.03555918, 0.27088365],
# ...,
# [ 0.07756959, -1.0983126 , -0.27554095, ..., -0.97481126,
# 0.05165857, -1.8881842 ],
# [-0.05534615, -0.17468977, 0.01989254, ..., -0.75721925,
# 0.05806921, -0.4322922 ],
# [-0.11392401, 0.19793215, 0.18854302, ..., -0.74105257,
# -0.27930856, 0.592124 ]], dtype=float32),
# array([ 2.92377859e-01, 7.89579988e-01, -8.01233768e-01, 1.34701118e-01,
# 6.62115276e-01, 7.12266684e-01, -3.74676973e-01, -7.11457253e-01,
# 4.66780514e-01, -7.47641563e-01, 8.39061558e-01, -8.70800555e-01,
# -9.22896639e-02, -5.97684383e-01, 9.21678185e-01, -7.86481202e-01,
# -7.15697348e-01, 3.46471399e-01, -1.27438813e-01, 5.08564353e-01,
# 8.94545972e-01, -3.04769695e-01, -4.16091025e-01, 6.29832745e-01,
# 7.70113349e-01, 5.62517822e-01, -1.40060395e-01, -6.13778293e-01,
# -9.92343605e-01, -1.18257217e-02, 1.27685279e-01, 7.96244562e-01,
# -4.66091394e-01, -9.90892828e-01, -2.35101596e-01, 5.28025210e-01,
# ......
# -2.87711918e-01, -2.82953620e-01, -4.40009236e-01, 7.71043062e-01],
# dtype=float32))
- 由于计算精度问题, 结果不会完全一直,但也相差甚微。

