数据库知识补充 事务 索引 约束 视图
1、事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务
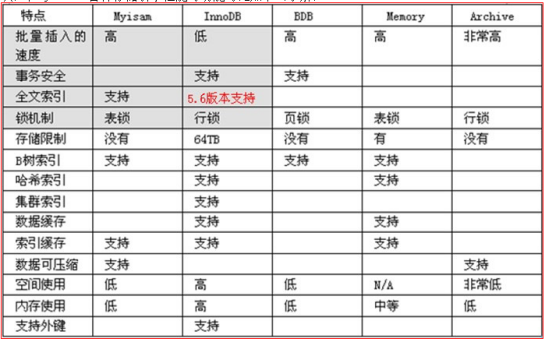
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
engine = “表的存储引擎名”;
存储引擎就是将数据存入硬盘(或其他媒介)的方式方法。通常就几个可用,默认是InnoDB
存储引擎决定一个数据表的各方面的信息:功能和性能。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
² 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
² 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
² 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
² 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
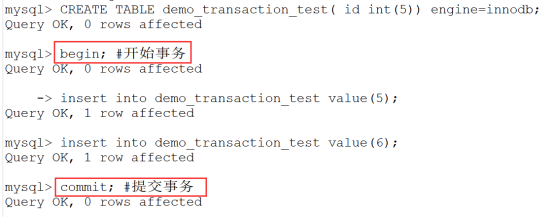
注意:在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
事务控制语句:
- BEGIN或START TRANSACTION;显式地开启一个事务;
- COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改成为永久性的;
- ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT;
- RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier;把事务回滚到标记点;
- SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚--取消事务
COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
例子:
2、索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方 ,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
什么是索引:
索引是一个“内置表”,该表的数据是对某个真实表的某个(些)字段的数据做了“排序”之后的存储形式。
对创建(设计)表来说,建立索引是非常简单的事,形式如下:
索引类型 (字段名1,字段名2, .... ) //可以使用多个字段建立索引,但通常是一个
有以下几种索引:
- 普通索引:key(字段名1,字段名2, .... ):它只具有索引的基本功能——提速
- 唯一索引:unique key (字段名1,字段名2, .... )
- 主键索引:primary key (字段名1,字段名2, .... )
- 全文索引:fulltext (字段名1,字段名2, .... )

3、约束
什么叫约束:约束就是一种限定数据以符合某种要求的形式(机制)
约束主要有:
- 主键约束:primary key (字段名1,字段名2, .... )
其实就是主键索引,也是主键属性。即primary key有3个角度的理解(说法):字段属性设置为主键,或建立的主键索引,或设定一个主键约束,但他们的本质是一样
- 唯一约束:unique key (字段名1,字段名2, .... ),其实也是“3体合一”(类似primary key)
- 外键约束:
外键:就是设定一个表中的某个字段的值,必须“来源于”另一个表的某个主键字段的值。
语法形式:foreign key (字段名1,字段名2, .... ) references 表名2(字段名1,字段名2, .... )
说明:对某个(些)字段设定外键,则其相对应的其他表的对应字段需要设置为主键。
4、视图
视图可以看作是一个“临时存储的数据所构成的表”(非真实表),其实本质上只是一个select语句。只是将该select语句(通常比较复杂)进行一个“包装”,并设定了一个名字,其后就可以通过该名字并把该名字当作一个表来使用。
如果一个select语句比较复杂,又在多个页面需要使用它,则可以将它做成一个视图,方便使用。
又如果,某个数据表中的某些字段不想给别人看(不同公司之间的数据业务交换的时候),但另一个又需要给人看,此时也可以使用视图。
视图创建:
create view 视图名 [(列名1,列名2,...)] as 一条复杂select语句;
可以将select语句所取得的列重新命名,但也可以不重新命名,则使用select语句中的给定列名
视图的使用
其实就是当作一个查询表来用(通常只用于select)
select * from 视图名 where 条件 order by .....。
修改视图:
alter view 视图名 [(列名1,列名2,...)] as select语句;
删除视图:
drop view [if exists] 视图名;
