流处理 —— Spark Streaming中的Window操作
窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个可配置的速率向前移动窗口,根据窗口函数的具体内容,分别对当前窗口中的这一波数据采取某个对应的操作算子。
需要注意的是窗口长度,和窗口移动速率需要是batch time的整数倍。
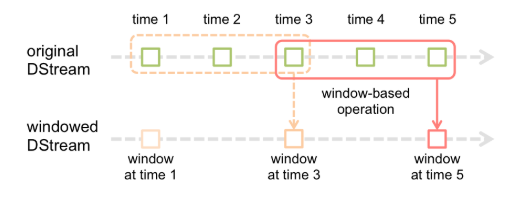
1.window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
//input: ------- java scala ------- java scala ------- val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .map((_, 1)) .window(Seconds(50), Seconds(10)) .print() ssc.start() ssc.awaitTermination() //output: //input: ------- java scala ------- java scala java scala -------
2. countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数。
注:需要设置checkpoint
//input: ------- java ------- java scala ------- val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 设置checkpoint ssc.checkpoint("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\checkpoint") // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .map((_, 1)) .countByWindow(Seconds(30), Seconds(10)) .print() ssc.start() ssc.awaitTermination() // output: ------ 1 ------ 3 ------
3. countByValueAndWindow(windowLength,slideInterval, [numTasks])
统计当前时间窗口中元素值相同的元素的个数
注:需要设置checkpoint
// input: ----------- java ----------- java scala ----------- val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 设置checkpoint ssc.checkpoint("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\checkpoint") // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .countByValueAndWindow(Seconds(30), Seconds(10)) .print() ssc.start() ssc.awaitTermination() // ouput: --------- (java,1) --------- (java,2) (scala,1) ---------
4. reduceByWindow(func, windowLength,slideInterval)
在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
// input: ---------- java ---------- java spark ---------- val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 设置checkpoint // ssc.checkpoint("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\checkpoint") // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .reduceByWindow(_ + ":" + _, Seconds(30), Seconds(10)) .print() ssc.start() ssc.awaitTermination() // output: ---------- java ---------- java:java:spark ----------
5.reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据进行计算。该操作有一个可选的并发数参数。
// input: ---------- java ----------- java scala ----------- val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 设置checkpoint // ssc.checkpoint("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\checkpoint") // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .map((_, 1)) .reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(30), Seconds(10)) .print() ssc.start() ssc.awaitTermination() //output: ----------- (java,1) ----------- (java,2) (scala,1) -----------
6. reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
val spark = SparkSession.builder() .master("local[2]") .appName("UpdateStateByKeyDemo") .getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(10)) // 设置checkpoint // ssc.checkpoint("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\checkpoint") // 注意:窗口长度,窗口移动速率需要是batch time的整数倍 ssc.textFileStream("file:\\D:\\workspace\\idea\\silent\\src\\main\\resources\\stream") .map((_, 1)) .reduceByKeyAndWindow((a: Int, b: Int) => a + b, (a: Int, b: Int) => a - b, Seconds(20), Seconds(10)) .print() ssc.start() ssc.awaitTermination()

