

hashtable详解
在 红黑树详解 文章中,二叉搜索树具有对数平均时间的表现是构造在这样的假设下的:输入数据有足够的随机性。
本篇介绍的hashtable(散列表)的数据结构,在插入、删除、搜寻等操作上也具有“常数平均时间”的表现,而且这种表现是以统计数据为基础,不需仰赖输入元素的随机性。
1. hashtable
概述 hashtable 可提供对任何有名项的存取和删除操作。由于操作对象是有名项,所以hashtable也可被视为一种字典结构。这种结构尝试提供常数时间之基本操作,如: 要存取所有的16-bits且不带正负号的整数,我们可以拥有65536个元素的array A,初值全部为0,每个元素值代表相应元素的出现次数。于是不论插入、删除、搜寻,每个操作都在尝试时间内完成。
这个解法存在两个问题。第一,如果元素是32-bits而非16-bits,我们所准备的array A 的大小就必须是2^32 = 4GB, 大得不切实际;第二,如果元素的型态是字符串(或其他)而非整数,将无法被拿来作为array的索引。
如何避免使用一个大得荒谬的array呢?办法之一就是使用某种映射函数,将大数映射为小数。负责将某一元素映射为一个“大小可接受之索引”,这样的函数称为hash function(散列函数)。例如,假设x是任意整数,TableSize 是 array 大小,则 x%TableSize 会得到一个整数,范围在0 ~ TableSize - 1 之间,恰可作为表格的索引。
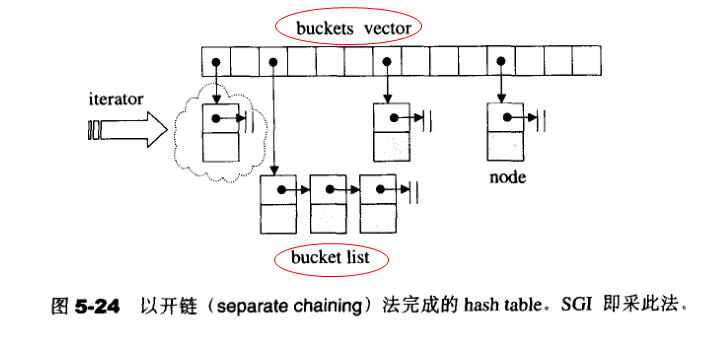
使用hash function 会带来一个问题:可能有不同的元素被映射到相同的位置(亦即有相同的索引)。这无法避免,因为元素个数大于array容量。这便是所谓的“碰撞(collision)”问题。解决碰撞问题的办法有许多种,包括线性探测(linear probing)、二次探测(quadratic probing)、开链(separate chaining).... 等做法。线性探测和二次探测在《STL源码剖析》中有介绍,请参见5.7相关章节。SGI STL 采用的是开链。
开链法,是在每一个表格元素中维护一个list;hash function 为我们分配某一个list,然后我们在那个list身上执行元素的插入、删除、搜寻等操作。使用开链法,表格的负载系数将大于1。SGI STL 的hash table 便是采用这种做法。
2. hashtable 的桶子(buckets)与节点(nodes)
//hashtable node节点定义; template <class Value> struct __hashtable_node { __hashtable_node* next; Value val; };
注意,buckets所维护的linked list ,并不采用STL的list 或 slist,而是自行维护上述的hash table node。至于buckets 聚合体,则以vector完成,以便有动态扩充能力。
3. hashtable 的迭代器
参见相关源码;
注意:
(1)hashtable 迭代器必须永远维系着与整个“buckets vector”的关系,并记录目前所指的节点(因为可能需要从bucket跳到bucket)。
(2)hashtable 迭代器没有后退操作(operator--),hashtable也没有定义所谓的逆向迭代器。
4. hashtable的数据结构
参见相关源码;
hashtable 的模板参数相当多,包括:
(1)Value:节点的实值型别;
(2)Key:节点的键值型别;
(3)HashFcn:hash function的函数型别;
(4)ExtractKey:从节点中取出键值的方法(函数或仿函数);
(5)EqualKey:判断键值相同与否的方法(函数或仿函数);
(6)Alloc:空间配置器,缺省使用std::alloc。
虽然开链法并不要求表格大小必须为质数,但SGI STL 仍然以质数来设计表格大小,并且先将28个质数(逐渐呈现大约两倍的关系)计算好,已备随时访问,同时提供一个函数__stl_next_prime(unsigned long n),用来查询在这28个质数之中,“最接近某数并大于某数”的质数。
5. hashtable 的构造与内存管理
构造函数参见相关源码;
(1)hashtable 的插入操作与表格重整 插入操作会判断是否需要重整表格,hashtable 提供了 resize 函数执行此重整过程。其对于“表格重建与否”的判断,是拿元素个数(把新增元素计入后)和bucket vector 的大小来比较。如果前者大于后者,就重建表格。由此可判知,每个bucket(list)的最大容量和buckets vector的大小相同(解释:理想情况下,元素均匀插入到bucket vector的每一个bucket(也即list)中;在极端情况下,有可能所有元素都插入到了同一个bucket下面,那么元素总个数就是该bucket下面的元素,此时,拿元素个数和bucket vector 的大小比较来判断重建与否,由此得出,极端情况下(所有元素插入到同一个bucket),bucket的元素个数不可能大于bucket vector的大小(因为如果大于,就会引发重建过程),也即,每个bucket 的最大容量 和 bucket vector 的大小相同。>o< 好像有点罗嗦。)。
参见相关源码;
(2)判知元素的落脚处 有时候我们的程序需要知道某个元素值位于哪一个bucket之内。SGI 提供了bkt_num() 函数来执行此操作,再由bkt_num()函数调用hash function,取得一个可以执行modulus(取模)运算的数值。之所以加了一层包装,是因为有些元素型别无法直接拿来对hashtable 的大小进行模运算,如字符串const char*, 这时候我们需要做一些转换。
(3)复制和整体删除 由于整个hash table 由vector 和 linked-list 组合而成,因此,复制和整体删除,都需要特别注意内存的释放问题。hashtable提供了两个相关函数:clear()和copy_from()。
参见相关源码;
6. hash functions
<stl_hash_fun.h>定义有数个现成的hash functions,全都是仿函数。 有关hash的STL_TEMPLATE_NULL ,在<stl_config.h> 中皆被定义为template<>。其中针对 char*, const char*, char, unsigned char, signed char, short, unsigned short, int, unsigned int, long, unsigned long 都提供了特化版本,由此观之,SGI hashtable 无法处理上述所列各项型别以外的元素,例如 string,double,float 。欲处理这些型别,用户必须自行为它们定义hash function。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号