PS:所有问题均在caffe-windows下产生
1、为什么AlexNet中,InnerProduct_Layer(fc8)层的输出可以直接作为Accuracy_Layer层的输出?
答:首先,我们要搞清楚,全连接层的输出是什么。全连接层的操作其实也是卷积操作,只不过要求卷积核的尺寸与输入进来的FeatureMap相同,因此全连接层输出的向量大小为1*1。
其次,为什么全连接层输出可以作为accuracy。因为该输出表示输入的样本属于某一类的可能性的大小,但并不是概率,所以如果仅仅是做预测,全连接层的输出就够了。
2、caffe源码中,各layer的forward_gpu()和backward_gpu()实现在哪里?对应的*_layer.cpp中只有*_cpu的实现。
答:在*.cu文件中,具体位置在.\caffe\caffe-windows\src\caffe\layers\。具体区别是:cuda的程序就放到cu中,其他的都可以放到c中
其实都可以直接写到cu中,nvcc的编译器会自动把host段的代码放到c的编译器编译。(我自己也不是很懂,是从网上招来的答案)
3、InnerProduct_Layer输出的featuremap大小是多少?
答:在全连接层,其实进行的也是卷积的操作。只不过卷积核的尺寸等于输入的FeatureMap的尺寸。因此全连接层的输出大小为1*1。
4、卷积层的卷积操作是如何实现的?
答:见http://blog.csdn.net/mounty_fsc/article/details/51290446,该文作者给出了详细的解释。
5、为什么用python进行“import caffe”时,会出现“No Module Named Caffe”错误?
答:原因是因为caffe文件中的pycaffe未编译。解决方法:(1)修改$\caffe\caffe-windows\windows下的CommonSettings.props文件,如下图:
 ;
;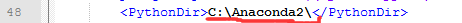
将13行false改为true,将PythonDir改为当前Anaconda2所在位置。
(2)编译pycaffe成功后,将build/x64/Release/pycaffe/caffe文件夹拷贝到c:\Anaconda2\Lib\site-packages即可。
6、在python中使用均值文件,为什么mean.binaryproto文件不可用?
答:在python环境中使用均值文件,需要将mean.binaryproto文件转为为mean.npy文件。
7.如何计算当前卷积层的参数数目?
答:假设当前层的输出数目为N,卷积层的大小为K*K,输入进来的特征图为M*S*S,其中M为输入的特征图的个数,S*S为特征图的大小。
那么当前卷积层的参数数目为M*K*K*N。
8.用训练好的caffemodel来finetune已知的网络时,出现“check failed:error==cudaSuccess<2 vs. 0> out of memory”错误,该怎么解决?
答:原因是数据本身的batch_size设置过大,导致所需的GPU显存过大,而本身的GPU无法满足导致的。解决办法是:降低训练和测试所需的batch_size即可。
举例:我设置的batch_size=256时,所需的显存为:3901009924,此时出现错误;当我重置batch_size=128时,所需显存为:1950504964,此时可以顺利进行训练。
注:caffe的batch_size,表明一次iteration(迭代)有多少张图片,越大则耗费的显存越多,所以适当降低batch_size即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号