

Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取新浪新闻网站中的新闻信息
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取新浪新闻网站中的新闻信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要依靠request库新闻网站访问,采用scrapy框架配合BeautifulSoup解析结构获取新闻信息,从而实现数据的快速采集、清洗、入库等功能实现,最后以Json格式将数据保存在本地。
技术难点主要包括对新闻网站的不同页面结构分析、对数据的采集清洗。
二、主题页面的结构特征分析(15分)
1.新闻列表页面的结构特征
打开新浪新闻(http://news.sina.com.cn),通过在浏览器中用鼠标右键点击查看“查看元素”选项或者按“F12”打开网页源代码,分析页面可以发现新浪新闻存在两种Html格式的显示方案,一种是新闻标题的链接显示,另一种是图片+新闻标题的链接显示。


现在,由于要采集新闻,肯定需要采集列表后每个新闻进行单独的采集。采用正则表达式来提取新闻列表中的新闻链接最为方便。
https://news.sina.com.cn/c/2019-12-13/doc-iihnzhfz5603092.shtml
r'http://(\w+)\.sina.com.cn/(\w+)/(\d{4}-\d{2}-\d{2})/doc-([a-zA-Z0-9]{15}).(?:s)html'
这样就可以提取到列表中所有的新闻内页的链接了!
2.Htmls页面解析
通过在浏览器中用鼠标右键点击查看“查看元素”选项或者按“F12”打开网页源代码。

<h1 class="main-title"> 主标题
<div class="second-title"> 副标题
<span class="date"> 日期
<div class="article" id="article"> 正文结构
通过BeautifulSoup解析Html即可获取,进行采集。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
利用查找方法find_all()可以对特定标签进行查找

从这里可以看出搜寻特定需要的链接跳转信息存在<script src>中如需要特定查找某条信息可以定位都这个标签即可
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
本次爬虫框架是以scrapy框架配合BeautifulSoup库解析结构获取信息
首先需要在python3.7的基础上安装scrapy框架
#首先安装wheel支持 Pip install wheel #安装scrapy框架用以爬取 Pip install scrapy

程序代码:
#在已经建立好的scrapy环境下建立scrapy工程开始 class SinaNewsSpider(scrapy.Spider): name = 'sina_news_spider' start_urls = ['http://news.sina.com.cn'] #起始地址 allowed_domains = ['sina.com.cn'] #过滤器 url_pattern r'http://(\w+)\.sina.com.cn/(\w+)/(\d{4}-\d{2}-\d{2})/doc-([a-zA-Z0-9]{15}).(?:s)html' pattern="<meta name=\"sudameta\" content=\"comment_channel:(\w+);comment_id:comos-([a-zA-Z0-9]{14})\" />" def parse(self, response): pat = re.compile(self.url_pattern) next_urls = re.findall(pat, str(response.body)) for url in next_urls: article = 'http://'+url[0]+'.sina.com.cn/'+url[1]+'/'+url[2]+'/doc-'+url[3]+'.shtml' #拼凑出新闻链接
print(article) yield Request(article,callback=self.parse_news) def parse_news(self, response): item = SinaItem() pattern = re.match(self.url_pattern, str(response.url)) item['source'] = 'sina' item['date'] = ListCombiner(str(pattern.group(3)).split('-')) print(item['date']) sel = requests.get(response.url) sel.encoding = 'utf-8' sel = sel.text pat = re.compile(self.pattern) res = re.findall(pat, str(sel)) if res == []: return commentsUrl = 'http://comment5.news.sina.com.cn/comment/skin/default.html?channel='+str(res[0][0])+'&newsid=comos-'+str(res[0][1])+'&group=0' #新闻评论链接
soup = BeautifulSoup(sel,'html.parser') title = soup.find('h1',class_='main-title') #不同类型的新闻html不一样
if title == None: title = soup.find('h1',id='main_title') title = title.text #获取标题内容 temp = BeautifulSoup(str(soup.find('div',id='article')),'html.parser') #两种不同情况的处理
temp1 = BeautifulSoup(str(soup.find('div',id='artibody')),'html.parser') if len(temp.text)>len(temp1.text): temps = temp.find_all('p') else: temps = temp1.find_all('p') passage = '' #拼凑新闻内容
for new in temps: passage+=new.text item['newsId'] = 'comos-'+str(res[0][1]) item['cmtId'] = item['newsId'] item['channelId'] = str(res[0][0]) item['comments'] = {'link': str(commentsUrl)} item['contents'] = {'link': str(response.url), 'title': u'', 'passage': u''} item['contents']['title'] = title item['contents']['passage'] = passage yield item #数据持久化 def process_item(self, item, spider): dir_path = self.current_dir + '/docs/' + item['source'] + '/' + item['date'] print(dir_path) if not os.path.exists(dir_path): os.makedirs(dir_path) news_file_path = dir_path + '/' + item['newsId'] + '.json' if os.path.exists(news_file_path) and os.path.isfile(news_file_path): print("*****************************") print(item['newsId'] + '.json exists, just skip') print("*****************************") news_file = codecs.open(news_file_path, 'w', 'utf-8') line = json.dumps(dict(item)) news_file.write(line) news_file.close() return item
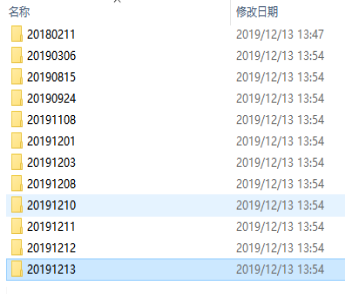
运行结果:


1.数据爬取与采集
class SinaNewsSpider(scrapy.Spider): name = 'sina_news_spider' start_urls = ['http://news.sina.com.cn'] #起始地址 allowed_domains = ['sina.com.cn'] #过滤器 url_pattern = r'http://(\w+)\.sina.com.cn/(\w+)/(\d{4}-\d{2}-\d{2})/doc-([a-zA-Z0-9]{15}).(?:s)html' pattern="<meta name=\"sudameta\" content=\"comment_channel:(\w+);comment_id:comos-([a-zA-Z0-9]{14})\" />" def parse(self, response): pat = re.compile(self.url_pattern) next_urls = re.findall(pat, str(response.body)) for url in next_urls: article = 'http://'+url[0]+'.sina.com.cn/'+url[1]+'/'+url[2]+'/doc-'+url[3]+'.shtml' #拼凑出新闻链接 print(article) yield Request(article,callback=self.parse_news) def parse_news(self, response): item = SinaItem() pattern = re.match(self.url_pattern, str(response.url)) item['source'] = 'sina' item['date'] = ListCombiner(str(pattern.group(3)).split('-')) print(item['date']) sel = requests.get(response.url) sel.encoding = 'utf-8' sel = sel.text pat = re.compile(self.pattern) res = re.findall(pat, str(sel)) if res == []: return commentsUrl = 'http://comment5.news.sina.com.cn/comment/skin/default.html?channel='+str(res[0][0])+'&newsid=comos-'+str(res[0][1])+'&group=0'
2.对数据进行清洗与处理
soup = BeautifulSoup(sel,'html.parser') title = soup.find('h1',class_='main-title') #不同类型的新闻html不一样 if title == None: title = soup.find('h1',id='main_title') title = title.text #获取标题内容 temp = BeautifulSoup(str(soup.find('div',id='article')),'html.parser') #两种不同情况的处理 temp1 = BeautifulSoup(str(soup.find('div',id='artibody')),'html.parser') if len(temp.text)>len(temp1.text): temps = temp.find_all('p') else: temps = temp1.find_all('p') passage = ''
3.数据持久化
def process_item(self, item, spider): dir_path = self.current_dir + '/docs/' + item['source'] + '/' + item['date'] print(dir_path) if not os.path.exists(dir_path): os.makedirs(dir_path) news_file_path = dir_path + '/' + item['newsId'] + '.json' if os.path.exists(news_file_path) and os.path.isfile(news_file_path): print("*****************************") print(item['newsId'] + '.json exists, just skip') print("*****************************") news_file = codecs.open(news_file_path, 'w', 'utf-8') line = json.dumps(dict(item)) news_file.write(line) news_file.close() return item
将数据加入Json结构体中,每个新闻单独存放一个json文件。
存储路径:/docs/日期/新闻分类/newsId.json

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对页面结构的分析,可以得到新闻的相关信息,更好的对相关信息进行数据挖掘和分析。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次任务,基本实现把想要的数据爬取下来,以及对其进行数据清洗及分析,按照中国大学Mooc的教程使用scrapy框架结合老师所教导的beautifulSoup库进行代码爬取,这次代码爬取没有使用requests库的原因是:偶然中国大学Mooc上发现了Scrapy框架爬虫而这个框架是以python为基础的一个开源爬虫框架,爬虫特点像堆积木一样的拼写爬虫,只需要beautifulsoup库对结构解析就可以快速处理文本信息。并且自动入库,保存文件。这次实验存在不足之处很明显,由于只是初次尝试对于scrapy框架来获取页面信息以及大部分结构的不熟悉,代码的数量不够多。但我会继续学习requests库以及scrapy这种较为新颖的框架结构提高自我能力,争取早日读懂爬虫吃透爬虫。
