【Datawhale 11月组队学习】深度强化学习基础
深度强化学习笔记
第一章:简介&辨析
Definition
强化学习(
reinforcement learning,RL)讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)中最大化它能获得的奖励。
根据我粗浅的理解,强化学习是一种 AI 学习范式,它并不是用于培养预测集的 AI 的学习范式,而是培养智能体的学习范式,根据我之前学习机器学习的经验来看,在实现上两者大不相同。
简单来说,强化学习训练的过程是一个智能体与环境进行交互的过程,大体流程如下:
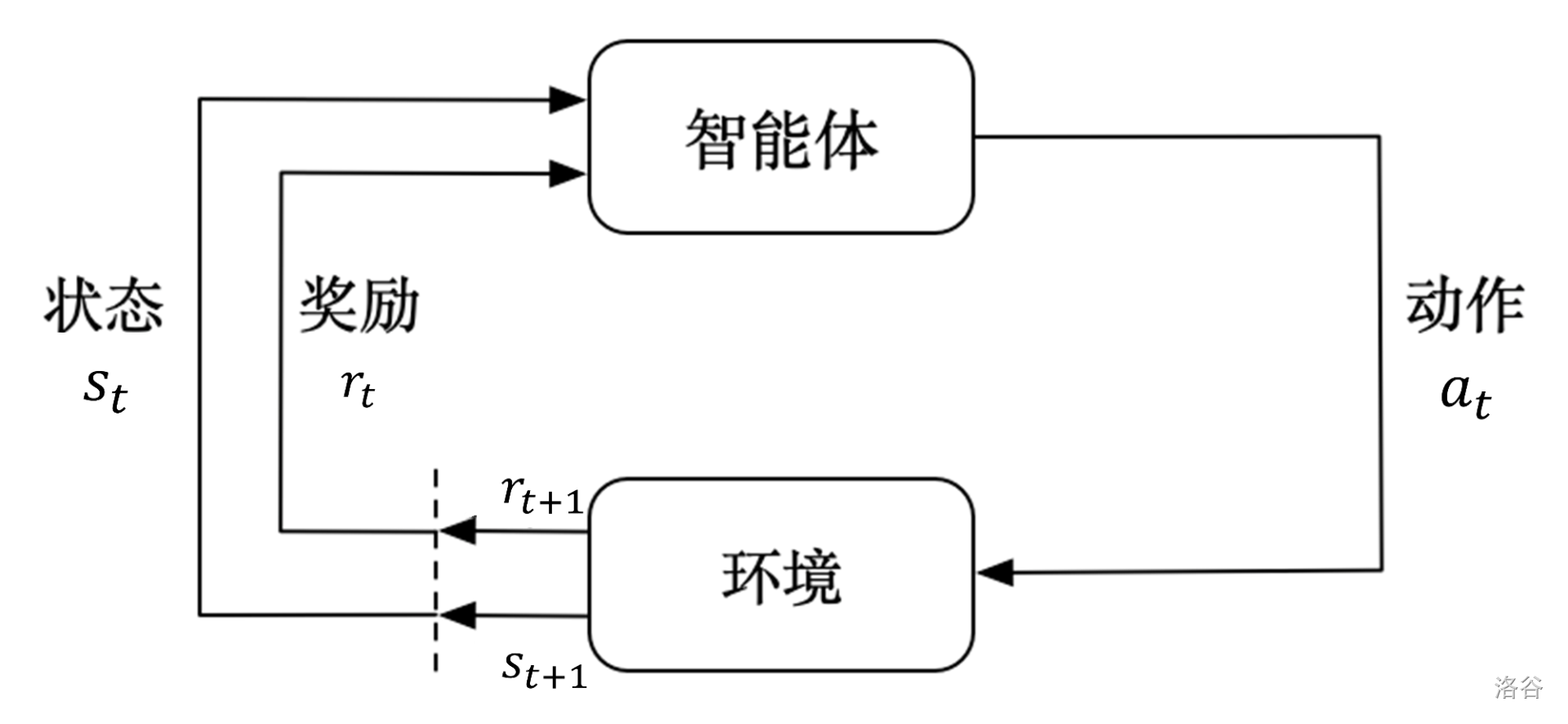
值得一提的是奖励机制。智能体的目的是最大化标量“奖励”,所以我们会唤醒估值函数、DP思想等死去的记忆。
Comparison
这里是强化学习与监督学习的比较。虽然我并未学习过监督学习的训练,但是大致明白它的思想。我想,教程《第一章:习题》的部分已经非常简练明确地指出了他们的区别。大致如下:
- 标准强化学习: 不需要标签样本,在设计特征之后,在与
环境交互中根据奖励多少训练预测函数和决策函数,试错时间长。解决序列数据的问题。 - 监督学习:需要标签样本,解决一些具有明确类别的问题,
反向传播修正网络权重。数据需要满足独立同分布。 - 无监督学习:不太了解,但是根据介绍好像类似于强行抽提特征建模,适用于
聚类问题,无需标签样本。 - 深度强化学习: 深度强化学习=深度学习+强化学习。将特征工程的过程省去,通过神经网络拟合价值函数或策略网络隐式地寻找特征,直接输入状态就可以输出动作。
Features
这里是强化学习中的几个特点,可以帮助我们决定应用条件和训练方法。
一. 序列决策
1.奖励设置:对于不同情况,作为最终指标的奖励根据环境不同有所变化。如:象棋中,输赢作为唯一评判;股票中,盈亏的过程会不断给出奖惩。
相信大家都发现一个问题,那就是延时奖励的现象,如象棋一盘棋有成百上千步,但是反馈奖励只在最后给出一个,最终的失败甚至可能是因为前几步就胡乱送兵。这种模式产生了两个后果:
- 成功的模型训练难度大,试错多,算力要求大,有盲目性。
- 每一步选取的动作必须有长期的影响,简单的说,不能使用贪心的策略,因为一直取局部最优解非常可能陷入死胡同,而应该使用动态规划(
DP)。
2.序列决策:对于每一次观测 \(o_i\),所有的下一步决策(动作 \(a_i\))都依据过去的决策史 \(H_t\),并且获得一个反馈(奖励 \(r_i\))。故决策史是观测、动作、奖励的序列:
所以整个游戏的状态看成关于决策史的函数:\(\large S_t=f(H_t)\)。
上图是一个决策史的例子。需要注意的是:图中用了状态(state)代替观测(observation),这只在假设环境是完全可观测的(fully observed)的时候成立,这时候建模为马尔可夫决策过程 (Markov decision process,MDP)即可。否则,则通常建模为部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)。
二.动作空间
简单来说就是可选用的决策个数,和它们组成的集。可分为离散的(discrete)和连续的(continuous)。
三.智能体
对于一个强化学习智能体,它可能有一个或多个如下的组成成分。
- 策略(
policy)。智能体会用策略来选取下一步的动作。- 价值函数(
value function)。用价值函数来对当前状态进行评估。价值函数用于评估智能体进入某个状态后,可以对后面的奖励带来多大的影响。价值函数值越大,说明智能体进入这个状态越有利。- 模型(
model)。模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式。
1.策略。策略通常分为随机性策略(stochastic policy)和确定性策略(deterministic policy)。前者返回一个决策可能性的概率分布,通过取样获得决策;后者的输出对于相同状态来说是固定的。
Questions
Appendix I
- 强化学习(
reinforcement learning,RL):智能体可以在与复杂且不确定的环境进行交互时,尝试使所获得的奖励最大化的算法。 - 动作(
action): 环境接收到的智能体基于当前状态的输出。 - 状态(
state):智能体从环境中获取的状态。状态是对世界的完整描述,不会隐藏世界的信息。 - 观测(
observation): 观测是对状态的部分描述,可能会遗漏一些信息。 - 奖励(
reward):智能体从环境中获取的反馈信号,这个信号指定了智能体在某一步采取了某个策略以后是否得到奖励,以及奖励的大小。 - 探索(
exploration):在当前的情况下,继续尝试新的动作。其有可能得到更高的奖励,也有可能一无所有。 - 利用(
exploitation):在当前的情况下,继续尝试已知的可以获得最大奖励的过程,即选择重复执行当前动作。 - 深度强化学习(
deep reinforcement learning):不需要手动设计特征,仅需要输入状态就可以让系统直接输出动作的一个端到端(end-to-end)的强化学习方法。通常使用神经网络来拟合价值函数(value function)或者策略网络(policy network)。 - 全部可观测(
full observability)、完全可观测(fully observed)和部分可观测(partially observed):当智能体的状态与环境的状态等价时,我们就称这个环境是全部可观测的;当智能体能够观察到环境的所有状态时,我们称这个环境是完全可观测的;一般智能体不能观察到环境的所有状态时,我们称这个环境是部分可观测的。 - 部分可观测马尔可夫决策过程(
partially observable Markov decision process,POMDP):即马尔可夫决策过程的泛化。部分可观测马尔可夫决策过程依然具有马尔可夫性质,但是其假设智能体无法感知环境的状态,只能知道部分观测值。 - 动作空间(
action space)、离散动作空间(discrete action space)和连续动作空间(continuous action space):在给定的环境中,有效动作的集合被称为动作空间,智能体的动作数量有限的动作空间称为离散动作空间,反之,则被称为连续动作空间。 - 基于策略的(
policy-based):智能体会制定一套动作策略,即确定在给定状态下需要采取何种动作,并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。 - 基于价值的(
valued-based):智能体不需要制定显式的策略,它维护一个价值表格或者价值函数,并通过这个价值表格或价值函数来执行使得价值最大化的动作。 - 有模型(
model-based)结构:智能体通过学习状态的转移来进行决策。 - 免模型(
model-free)结构:智能体没有直接估计状态的转移,也没有得到环境的具体转移变量,它通过学习价值函数或者策略网络进行决策。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号