AI夏令营第三期 - 用户新增预测挑战赛教程(机器学习)
Log#
<第一次更新> 2023.8.17 14:33,之前写的内容没保存,只能重写一遍了……
第一次打卡内容截止到第一条分割线,以此类推。
<第二次更新>2023.8.23 20:30
Backgound#
赛事任务#
根据给定数据集,以及给出的baseline方案,通过可视化分析、模型交叉验证、特征工程构建等方式优化 AI 模型,并预测用户新增情况target字段。
赛题数据集#
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中:
uuid为样本唯一标识eid为访问行为IDudmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段common_ts为应用访问记录发生时间(毫秒时间戳)x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
Pre#
数据集仅含 train.csv 与 test.csv 。
基线方案的基本思路是把先把udmap里的key字段提取出来,然后增加以下三项特征:
common_ts_hour(小时)、eid_freq(该eid出现的次数)、eid_mean(该eid对应的字段均值)
随后用sk_learn库中的决策树模型进行训练和预测,最终得到的 在0.62 左右。
以上为 baseline 方案的内容理解,作为第一次打卡的内容,此处为分割线。
Work#
提前加入特征工程内容 x1_freq、x8_mean 等一系列十六个特征项, 提至0.68左右。
0.引入验证#
这步我后来才做,现在想想早应如此。首先,将训练集切分为新的训练集和测试集。
from sklearn.model_selection import train_test_split
train_data = pd.read_csv('train.csv')
# test_data = pd.read_csv('test.csv')
train_data, test_data = train_test_split(train_data, test_size = 0.25)
# 设置为0.25,是考虑到本题给出的训练集和测试集比例为3:1
随后,进行完了所有特征选择、训练之后,对模型的性能进行测试。使用sklearn库自带的指标。
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
# 训练数据测试,可以看看是否欠拟合
pred = clf.predict(train_data_fix)
precision = precision_score(train_data['target'], pred)
recall = recall_score(train_data['target'], pred)
f1__score = f1_score(train_data['target'], pred)
print(f"训练集:\nprecision:\t{precision},\nrecall:\t{recall}\nfl_score=\t{f1__score}")
print()
# 测试数据,可以观察是否过拟合,可以大致获得预测准确率
pred = clf.predict(test_data_fix)
precision = precision_score(test_data['target'], pred)
recall = recall_score(test_data['target'], pred)
f1__score = f1_score(test_data['target'], pred)
print(f"测试集:\nprecision:\t{precision},\nrecall:\t{recall}\nfl_score=\t{f1__score}")
结果大致如图:

可以看出训练集没有欠拟合的问题,而且估计的 相对准确,提交后甚至分数更高!
1.可视化分析#
下面进行可视化分析,代码如下:
import seaborn as sns
#读取训练集
train_data = pd.read_csv('test_data.csv')#读取训练集
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
# key9_mean分组下标签均值
sns.barplot(x='key9_mean', y='target', data=train_data)
# 其中key9mean可以随意更换为其他变量
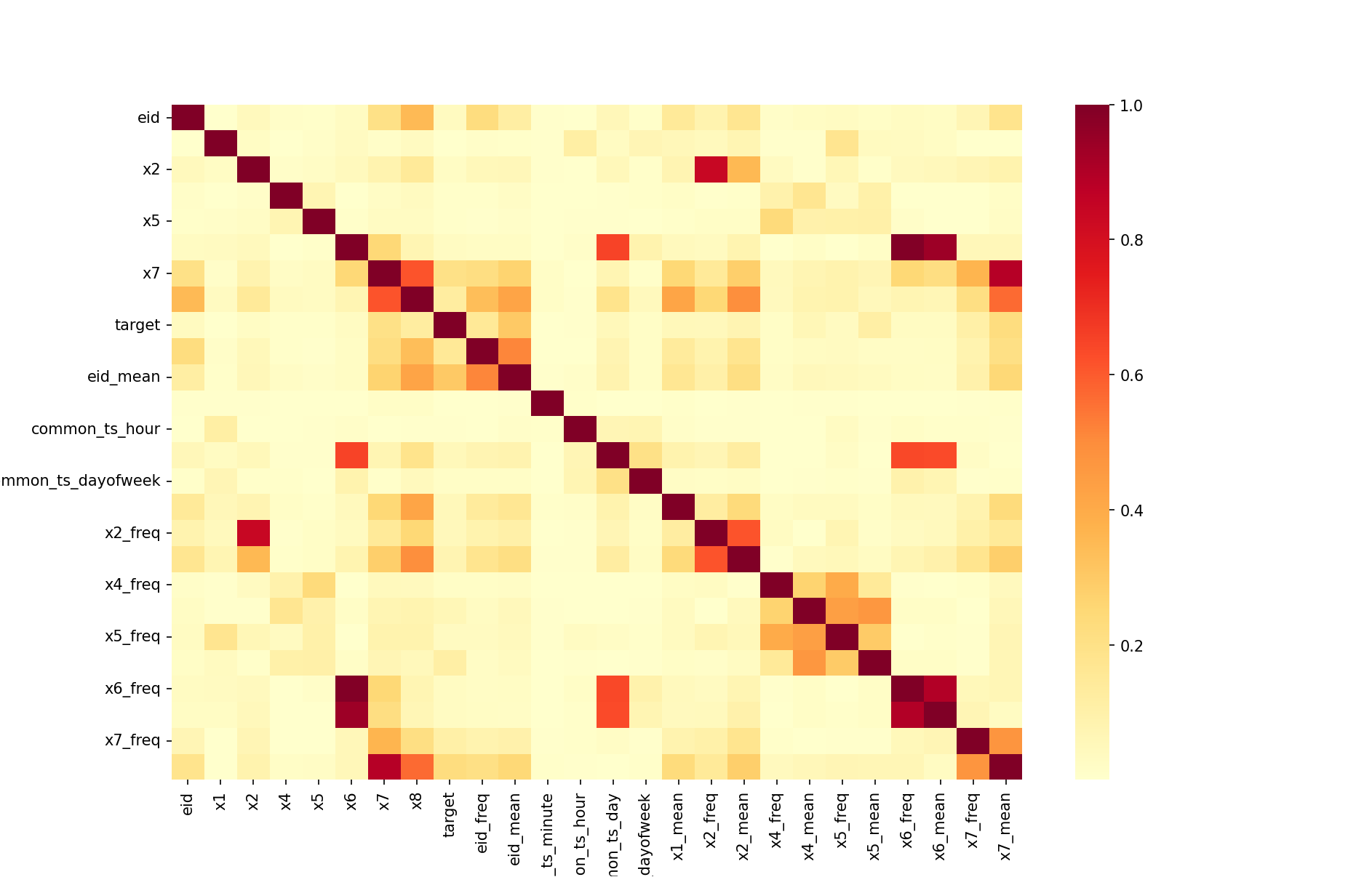
热力图可以表示相关性的强弱,如图,x7、eid_mean 等项与 target 值有着不低的相关性,可以考虑保留。
但是注意,热力图显示的相关性低不代表该特征项需要删去,而是应该综合考虑,多试几次,在结合各种可视化方
案的基础上进行取舍。(如图中common_ts_minuate 相关性显示不高,但是加入后确实能提分)
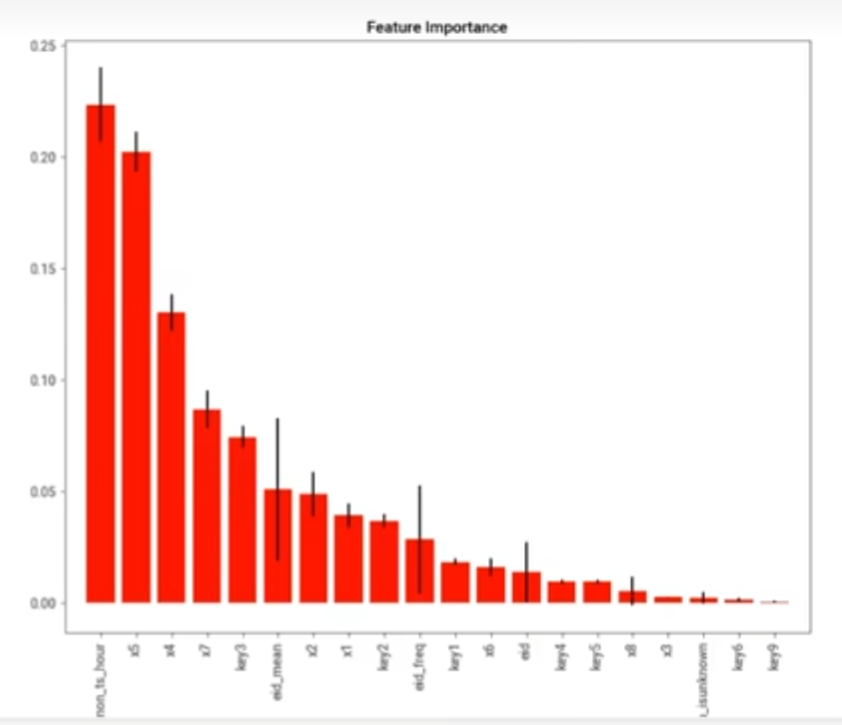
也可以通过训练后获得的 数据生成条形统计图观察权重,进行取舍。该图告诉我们时间是一个值得挖掘的特征项,权重分配较高。
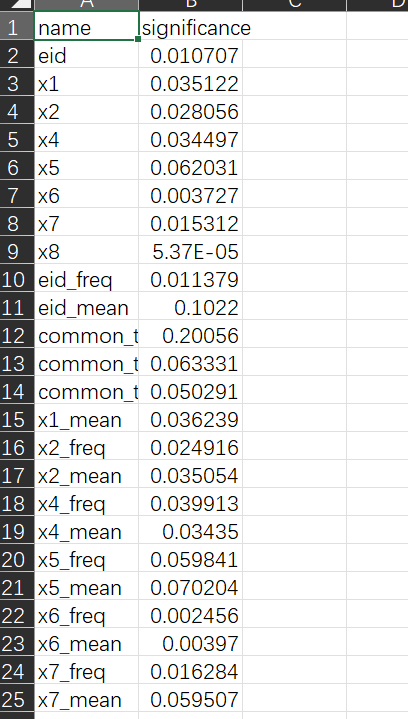
如图为某一次训练中特征项权重的表格。(我们可以先把想到的特征全部加入,然后做图表看看是否应该保留)
Q&A#
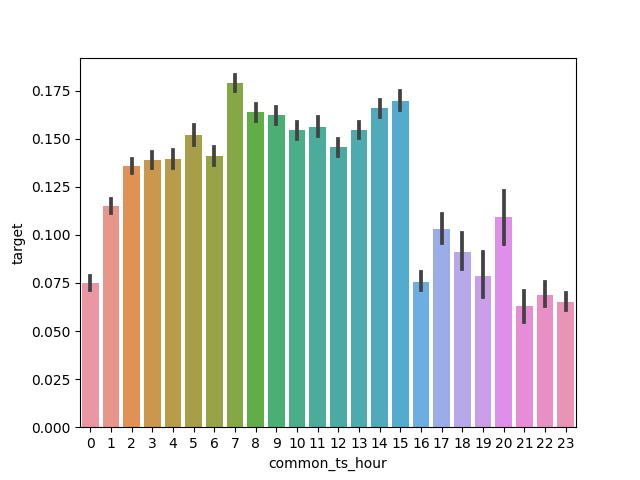
2.特征工程,数据处理#
特征筛选#
理清各个特征项的重要程度之后,可以逐步删除相关性低的特征,注意每删一次运行一次看看分数变化,及时
止损,而且能发现很多应该保留的特征。
最后,我保留的特征有二十多个,其中一些关键要点:
eid及其衍生特征。- 时间特征
weekday、day、hour、minuate等。 - 中 删去能提分,其余最好保留,虽然作用也不大,聊胜于无,但是删去会没分。
- 中仅保留了 。
数据处理#
缺失值: 少量缺失值,可以考虑平均值、中位数填充,我选用中位数填充。
其他暂时没有什么处理,如果引入 的话可能还要搞一下,也可以选用多模型统计投票的方式:
clf = DecisionTreeClassifier()
clf.fit(train_data_fix, train_data['target'])
pred = clf.predict(test_data_fix)
pred = np.concatenate((pred, pred)) #因为其他模型表现不是很好,为决策树模型加权
clf = MultinomialNB()
clf.fit(train_data_fix, train_data['target'])
pred = np.concatenate((pred, clf.predict(test_data_fix)))
clf = RandomForestClassifier(n_estimators=10)
clf.fit(train_data_fix, train_data['target'])
pred = np.concatenate((pred, clf.predict(test_data_fix)))
#(4,-1)表示重组为四排,列数不限
#.T转置是因为投票为同行投票
pred = pred.reshape(4, -1).T
# 对每个样本的30次预测结果进行投票,选出最多的类别作为该样本的最终预测类别,存储在pred_label列表中。
pred_label = [Counter(x).most_common(1)[0][0] for x in pred]
经过这些处理,调优后我获得的分数为 0.77 左右,经过助教提点,接下来引入 模型进行优化提分。
以上为第二次打卡内容,此处为分割线。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律