
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
摘要
该论文介绍了一种新的语言表示模型BERT,它表示转换器的双向编码器表示。与最近的语言表示模型不同,BERT利用不标记的文本通过在所有层的上下文联合调节来预训练深层双向表示。因此,只需一个额外的输出层就可以对预先训练好的BERT表示进行微调,以便为各种任务创建最先进的模型,例如问答和语言推断,而无需基本的任务特定架构修改。
BERT概念简单,经验丰富。它在11项自然语言处理任务中获得了最新的技术成果,包括将GLUE的基准值提高到80.4%(7.6%的绝对改进)、多项准确率提高到86.7%(5.6%的绝对改进)、将SQuAD v1.1的问答测试F1提高到93.2(1.5的绝对改进),比human的表现高出2.0。
简介
语言模型预训练已经证明对改进许多自然语言处理任务是有效的。这些任务包括句子级任务,如自然语言推理和释义,旨在通过整体分析来预测句子之间的关系,以及字符级任务,如命名实体识别和SQuAD问题回答,其中模型需要在字符级别生成细粒度输出。
将预训练语言表示应用于下游任务有两种现有策略:基于特征和微调。基于特征的方法,例如ELMo(Peters等,2018),使用特定于任务的体系结构,其包括预先训练的表示作为附加特征。微调方法,例如Generative Pre-trained Transformer(OpenAI GPT)(Radford等,2018),引入了最小的任务特定参数,并通过简单地微调预训练参数来训练下游任务。在以前的工作中,两种方法在预训练期间共享相同的目标函数,在这些方法中,他们使用单向语言模型来学习一般语言表示
我们认为当前的技术严重限制了预训练表示的能力,特别是对于微调方法。主要限制是标准语言模型是单向的,这限制了在预训练期间可以使用的体系结构的选择。这些限制对于句子级别任务来说是次优的,且在将基于微调的方法应用于字符级别任务(例如SQuAD问答)时可能是毁灭性的,在这些任务中,从两个方向合并上下文至关重要。
在本文中,我们通过提出BERT:变换器的双向编码器表示来改进基于微调的方法。 BERT通过提出一个新的预训练目标来解决前面提到的单向约束:“掩盖语言模型”(MLM),受到完形任务的启发。被掩盖的语言模型从输入中随机地掩盖一些标记,并且目标是仅基于其上下文来预测被掩盖的单词的原始词汇id。与从左到右的语言模型预训练不同,MLM目标允许表示融合左右上下文,这允许我们预训练一个深度双向变换器。除了蒙面语言模型,我们还引入了一个“下一句预测”任务,联合预训练文本对表示。
本文的贡献如下:
- 我们证明了双向预训练对语言表达的重要性。与Radford等人不同。其使用单向语言模型进行预训练,BERT
使用掩蔽语言模型来实现预训练的深度双向表示。这也与Peters等人(2018年)形成了鲜明对比,Peters等人使用的是一种由独立训练的从左到右和从右到左的LMs的浅层连接。 - 我们展示了预先训练的表示消除了许多经过大量工程设计的特定于任务的体系结构的需求。BERT是第一个基于微调的表示模型,它在大量的句子级和字符级任务上实现了最先进的性能,优于许多具有任务特定体系结构的系统。
- BERT推进了11项NLP任务的最新技术。我们还报告了对BERT的广泛消融,证明了我们模型的双向性质是最重要的新贡献。代码和预先训练的模型将在goo.gl/language/bert上提供。
BERT
模型体系结构
BERT的模型架构是一个多层双向Transformer编码器,基于Vaswani等人中描述的原始实现,并在tensor2tensor库中发布,在这项工作中,我们将层数(即变形金刚块)表示为L,将隐藏层大小表示为H,将自注意力头的数量表示为A。在所有情况下,我们将前馈/滤波器大小设置为4H,即H = 768时为3072,H = 1024时为4096。我们主要报告两种模型大小的结果:
- BERTBASE: L=12, H=768, A=12, Total Parameters=110M
- BERTLARGE: L=24, H=1024, A=16, Total Parameters=340M
![]()

输入表示
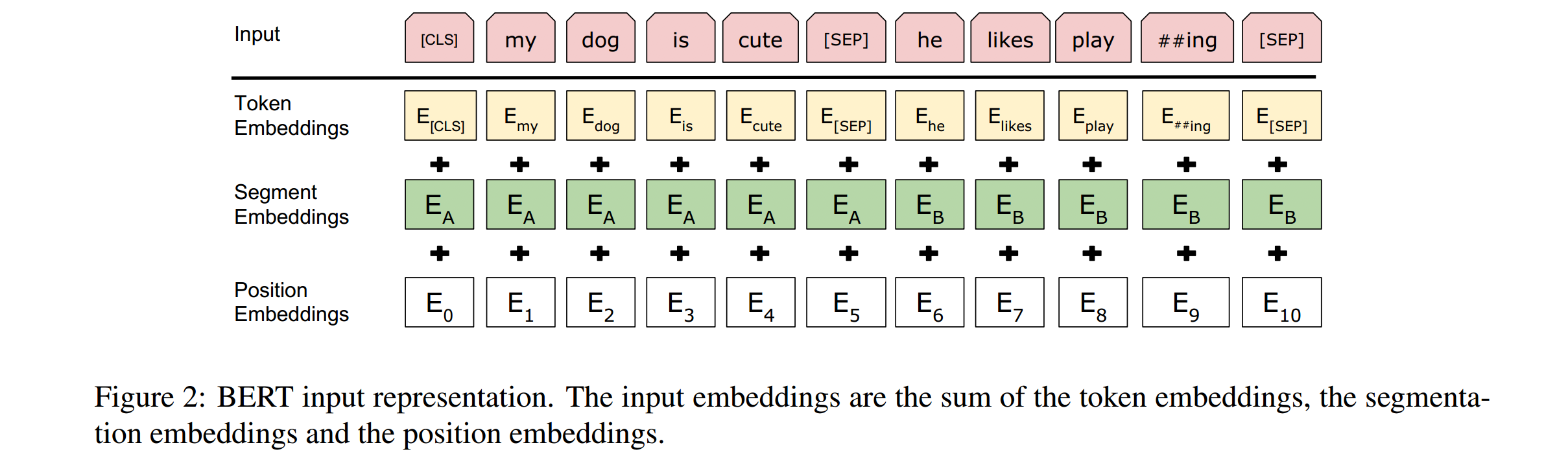
我们的输入表示能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如,[问题,答案])。在这个工作中,一个“句子”可以是任意一段连续的文本,而不是一个实际的语言句子。“序列”是指BERT的输入标记序列,它可以是一个句子,也可以是两个句子组合在一起。我们使用带有30,000个标记词汇表的WordPiece嵌入(Wu et al.,2016)。每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此标记对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被打包成一个单独的序列。我们用两种方法区分这些句子。首先,我们用一个特殊的标记(9)将它们分开。第二,我们添加一个学习到的向量到每一个标记指示是否属于句子a或句子b .如图1所示,我们表示输入E嵌入,最后隐藏向量的特殊(CLS)标记如\(C \epsilon R^{H}\),第\(i^{th}\)个输入标记的最终隐藏向量为\(T_{i}\epsilon R^{H}\)
对于给定的标记,其输入表示是通过对相应的标记、段和位置向量求和来构造的。这种结构的可视化结果可以在图2中看到。
预训练
与Peters等人(2018)和Radford等人(2018)不同的是,我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,我们使用两节新的无监督预测任务对BERT进行预训练,如图1组左图所示.
任务1:Masked LM
直观地说,我们有理由相信,深度双向模型比从左到右模型或从左到右和从右到左模型的浅层连接更强大。不幸的是,标准的条件语言模型只能训练成从左到右或从右到左,因为双向条件作用可以让每个单词间接地“看到自己”,而且该模型可以在多层的上下文中轻松地预测目标单词。
为了训练深度双向表示,我们采用直接的方法随机屏蔽一定比例的输入单词,然后仅预测那些被屏蔽的单词。我们将这个程序称为“Masked LM”(MLM),尽管它在文献中通常被称为完形任务。在这种情况下,对应于掩码单词的最终隐藏向量被馈送到词汇表上的输出softmax,如在标准LM中。在我们的所有实验中,我们随机地屏蔽每个序列中所有WordPiece标记的15%。与去噪自动编码器(Vincent et al,2008)相反,我们只预测掩蔽的单词而不是重建整个输入。
虽然这确实允许我们获得双向预训练模型,但这种方法有两个缺点。首先,我们预训练和微调之间建立了一个不匹配,因为[MASK]的单词在微调期间从未出现。为了减轻这种影响,我们并不总是用实际的[MASK]单词替换“掩蔽”词。相反,训练数据生成器随机选择15%的令牌,例如,在句子中,我的狗是多毛的,它选择毛茸茸的。然后执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80%的时间:用[MASK]标记替换单词,例如,我的狗是多毛的!我的狗是[MASK]
- 10%的时间:用随机单词替换单词,例如,我的是狗多毛的!我的狗是苹果
- 10%的时间:保持单词不变,例如,我的是狗多毛的!我的是狗多毛的。这样做的目的是将表示偏向于实际观察到的单词。
任务2:下一句话预测
许多重要的下游任务,例如问答(QA)和自然语言推理(NLI),都是基于理解两个文本句子之间的关系,而这两个文本句子并不是由语言建模直接捕获的。 为了训练理解句子关系的模型,我们预先训练了一个可以从任何单语语料库轻松生成的二值化的下一个句子预测任务。具体地,当为每个预训练示例选择句子A和B时,50%的时间B是跟随A的实际下一句子,并且50%的时间是来自语料库的随机句子。NSP任务与使用的表征学习目标密切相关。然而,在以前的工作中,只有语句嵌入被传输到下游任务,在下游任务中BERT传输所有的参数来初始化最终任务模型参数。
预训练数据
训练前的程序很大程度上遵循了现有的语言模型训练的文献。对于训练前的语料库,我们使用BooksCorpus(8亿单词)(Zhu et al., 2015)和英语维基百科(2500亿单词)。对于Wikipedia,我们只提取文本段落,而忽略列表、表格和标题。为了提取长连续序列,关键是要使用文档级的语料库,而不是像十亿词基准(Chelba et al., 2013)这样打乱的句子级语料库。
微调模型
微调是很简单的,因为转换器中的自我注意机制允许BERT通过交换适当的输入和输出来对许多下游任务进行建模——不管它们是单个文本还是文本对。对于涉及文本对的应用,一种常见的模式是在应用双向交叉注意之前对文本对进行独立编码,如Parikh等(2016);Seo等(2017)。BERT使用了自我注意机制来统一这两个阶段,由于在编码一个具有自我注意的连接文本对时,有效地包含了两个句子之间的双向交叉注意。
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并对所有参数进行端到端的微调。在输入端,训练前的句子A和句子B类似于
(1)句子对释义
(2)假设前提对引申
(3)问题回答中的问题-短文对
(4)简并的文本-?在文本分类或序列标记中配对。
在输出中,token表示形式被输入到一个输出层,用于进行token级别的任务,例如序列标记或问题回答,而[CLS]表示形式被输入到一个输出层,用于分类,例如entailment或情感分析。
与培训前相比,微调相对便宜。本文中所有的结果都可以在一个单一的云TPU上最多1小时内复制,或者在GPU上最多几个小时,从完全相同的预训练模型开始。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号