Neural Architectures for Named Entity Recognition 学习笔记
简介
这篇论文主要提出了两种新型的神经网络结构——一种依赖于双向LSTM和条件随机场(CRF),另外一种是受移近/规约解析( shift-reduce)的启发,使用基于转移(transition-based)的方法去构建、标记句子段。论文总的模型依赖于两个关于单词的信息来源:(i)从监督语料库中学习的基于字符的单词表示和(ii)从未注释语料库中学习的无监督单词表示。
存在问题
目前NER是个具有挑战性的工作,原因如下:
- 只有很少的训练数据可以获得
- 可以被命名的实体时间的界限模糊,难以用较少的语料将命名实体结果通用化
目前大多数的命名实体识别都是通过详细地构建单词特征以及语言相关的知识资源(例如,地名录)来解决问题,但是在新语言和新领域中开发语言特定的资源和特性的成本非常高。
本文数据构造
由于目前用于NER识别的标记数据很少,本文提出的用于NER的神经网络结构除了使用少量的监督训练数据和未标记的语料库之外,不使用语言相关的资源或特征。本论文的实验显示,LSTM-CRF的实验效果较基于转移的算法的算法要好,因此本博客主要梳理LSTM-CRF的学习内容和实验效果。
LSTM-CRF Model
LSTM
递归神经网络是神经网络的一种,它用于处理序列化的数据。设输入的向量序列为\((x_1,x_2,...,x_n)\),将输出另一个序列\((h_q,h_2,...,h_n)\),它代表输入序列每一步的某些信息。虽然理论上RNN也可以学习序列的长期依赖关系,但实际上它们并不能这么做而是倾向于学习最新输入的序列(Bengio et al.,1994)。长短时记忆网络被设计成增加缓存单元以解决该问题,并已经被证明可以学习到序列的长期依赖关系。它利用一些“门”来控制输入到缓存单元的比例,以及遗忘先前状态的比例。(Hochreiter and Schmidhuber, 1997)。我们使用以下实现:
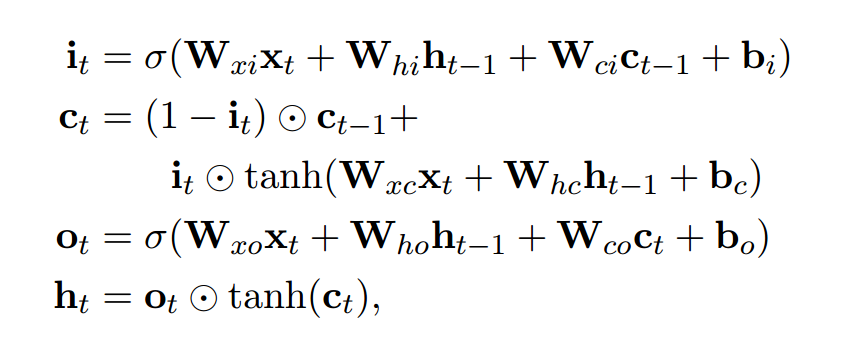
这里的\(\sigma\)指的是sigmoid函数,\(\bigodot\)指的是向量元素积,即Hadamard积。
对于一个给定包含n个词的句子\((x_1,x_2,...,x_n)\),每一个都被表示为为一个d维向量\(\vec{n_r}\),LSTM计算了句子下文每t个词的一个输出值\(\vec{n_l}\)。当然,也有特指上文的输出值 ,这可以利用LSTM读句子的反向序列实现。我们将前者称为正向LSTM,后者称为反向LSTM。他们是两个截然不同的具有不同参数的网络。正向LSTM与反向LSTM统称为双向LSTM(Gravesand Schmidhuber, 2005)。使用该模型时的词表示是通过该单词的上下文得到的,即\(h_t=[\vec{n_r},\vec{n_l}]\)。这些表征有效包括了上下文中的单词表征,这对于许多词性标注应用都很有用。
CRF Tagging Models
一个相当简单但是极其有效的词性标记系统是使用 \(h_t\)作为特征为每一个输出\(y_t\)做出独立的词性标记决策(Ling et al.,2015b)。尽管这个模型成功解决了类似 POS tagging 这样简单的问题,但是当需要输出标签之间存在有很强的依赖关系时,它的独立分类决策仍会受到限制。而NER就是这样的一个任务,因为对带多标签的序列进行表征的语法施加了许多强约束,这样的话,模型一开始的独立性假设就不满足了。
因此,我们的模型不是独立地词性标记决策,而是使用条件随机场对它们进行联合建模。对于这么一个输入句子
我们认为\(P\)是双向LSTM输出的评分矩阵。\(P\)的规模是\(n*k\) ,这里的 k 是不同标签的数量,而\(P_ij\)对应句子中第 i 个词的第 j 各标签的评分。对于一个预测的序列
我们定义它的评分为
这里的\(A\)是一个转换分数的矩阵,使得\(A_{ij}\)表示为从标签\(i\)到标签\(j\)转换的分数。\(y_0\)和\(y_n\)是一个句子的起始标签与尾标签,我们将它们添加到一个可能标签的集合里。因此\(A\)是一个规模为\(K+2\)的方阵。
对于所有可能的标签序列,一个 softmax 产生序列\(y\)的概率是:
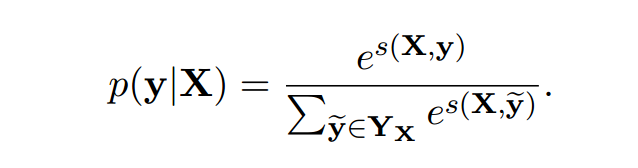
在训练过程中,我们将预测正确的标签序列的对数概率最大化:
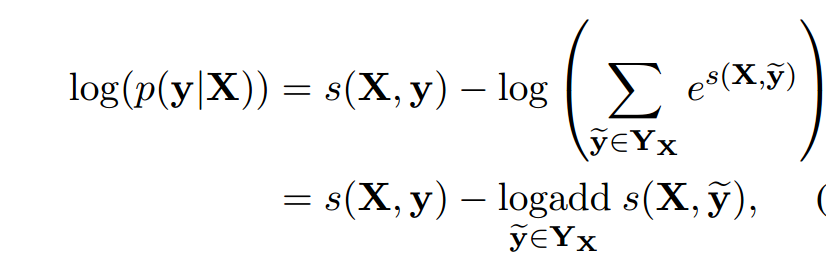
这里的\(Y_X\)指的是对于一个句子\(X\)所有可能的标签序列(甚至有些还没有验证为 IOB 格式)。对于上面的数学公式,很明显我们鼓励我们的网络输出一个有效的标签序列。当解码时,我们利用下面的式子:
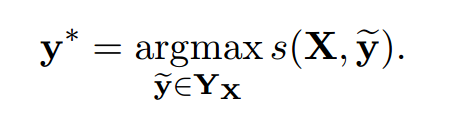
获得最大评分从而预测出输出序列。
Parameterization and Training
与每个词条(即\(p_{ij}\))的每个词性标注决策相关的评分是由双向LSTM计算的输出(每个词的向量)和二元语法的转移评分(即\(A_{y,{y}'}\))一起计算出来的。结构示意图如 Figure 1 。圆圈代表观测变量,菱形代表其父母的确定性函数,双圆圈代表随机变量。

Figure 1:网络的主要结构。词向量输入到BILSTM,\(l_i\)代表单词\(i\)与它的上文,\(r_i\)代表单词\(i\)与它的下文,把这两者联系起来,用\(c_i\)代表单词i与它的上下文。
因此,该模型的参数是二元语法模型的转移分数矩阵\(A\),而产生评分矩阵\(P\)的参数即双向LSTM的参数——线性的特征权重与词向量,如 2.2 部分所述,令\(x_i\)为句子中每个单词的词向量序列,\(y_i\)为它们相关联的标签。我们将在第4部分分析如何对\(x_i\)进行建模。词向量序列作为双向LSTM的输入,而后双向LSTM模型返回每个单词的上下文表示,如2.1。
这些表示可以在\(c_i\)中被联系起来并被线性投影到一个尺寸等于独立标签数量的层上。我们不使用 softmax 作为该层的输出,而是使用之前说过的CRF以考虑到相邻标签的相关性,从而产生每一个词的最终预测\(y_i\)。另外,我们观察到在\(c_i\)和CRF层之间添加一个隐含层可以稍稍改进我们的结果。所以本论文所有模型的实验也都加入了隐含层。给出观察的词,对于一个已注释语料库中的NER标签观测序列,这些参数通过训练将其对应的等式(1)最大化。
Tagging Schemes
命名实体识别的任务是给句子中的每一个词都分配一个命名实体标签。一个命名实体可以标记句子中的多个词条。句子通常以 IOB 格式(Inside, Outside, Beginning)表示,如果词条是一个命名实体的开始那么就标记其为 B 标签,同理 I 标签指词条在一个命名实体的内部,而 O 标签指词条在一个命名实体的外部。然而在这里我们使用的是命名实体识别更常用的 IOBES 词性标注方案,它是 IOB 的一种变体,用 S 标签标记词条是一个命名实体的开始,E 标签标记词条是一个命名实体的结束。使用这种办法能够以高置信度将标注为 I 标签的词的后续单词的词性选项缩小为 I 标签或者是 E 标签,而 IOB 方案仅仅能够确定后续单词是不是在命名实体内部。 Ratinov 、 Roth(2009)与 Dai et al.(2015)提出使用 IOBES 方案可以改善模型的性能。
Transition-Based Chunking Model
作为上一节讨论的LSTM-CRF的替代方案,我们将探索一种新的体系结构,它使用类似于基于转换的依赖项解析的算法对输入序列进行块处理和标记。这个模型直接构造了多标记名称的表示(例如,Mark Watney这个名称被组合成一个单一的表示)。
此模型依赖于堆栈数据结构以增量方式构造输入块。为了获得这个用于预测后续操作的堆栈的表示,我们使用了Dyer等人(2015)提出的堆栈-LSTM,其中LSTM被一个“堆栈指针”扩充。虽然按顺序的LSTMs从左到右建模序列,但堆栈LSTMs允许嵌入一组对象,这些对象既可以添加(使用push操作),也可以删除(使用pop操作)。这使得stack - lstm可以像一个堆栈一样工作,维护其内容的“摘要嵌入”。为了简单起见,我们将这个模型称为Stack-LSTM或S-LSTM模型。
Chunking Algorithm
我们设计了一个过渡库存,图2受基于转换的解析器的启发,在这个算法中,我们使用了两个堆栈(分别代表已完成的块和暂存空间的指定输出和堆栈)和一个包含尚未处理的单词的缓冲区。如图所示,transition的动作包含3个:SHIFT、REDUCE、OUT。SHIFT transition将单词从buffer搬到stack;OUT transition将词从buffer直接搬到输出stack;REDUCE transition从stack的top层将所有词推出来,组成 “chunking”,并将这个chunking的representation压入到output stack中。当stack和output stack全部为空,这个算法要做的事情就完了。

通过定义每个时间步上操作的概率分布(给定堆栈、缓冲区和输出的当前内容以及所采取的操作的历史),将模型参数化。在Dyer等人(2015)之后,我们使用堆栈LSTMs来计算每个这些的固定维词向量,并将它们串联起来以获得完整的算法状态。此表示形式用于定义在每个时间步骤中可能采取的操作的分布。在给定输入语句的情况下,对模型进行训练以最大化参考动作序列的条件概率(从标记的训练语料库中提取)。为了在测试时标记一个新的输入序列,我们贪婪地选择最大概率动作,直到算法达到终止状态。虽然这不能保证找到全局最优,但在实践中是有效的。由于每个标记要么直接移动到输出(1个操作),要么先移动到堆栈,然后再移动到输出(2个操作),因此长度为n的序列的操作总数最多为2n。
Representing Labeled Chunks
在执行REDUCE(y)操作时,算法将移动一系列令牌(连同它们的向量嵌入)从堆栈到输出缓冲区作为一个单独完成的块。为了计算这个序列的词向量,我们在其组成标记的词向量上运行一个双向LSTM,并使用一个表示要标识的块的类型的标记(即 i,e,y)。这个函数表示为\(g(u,...v,r_y)\),其中\(r_y\)是一种学习词向量的标签类型。因此,输出缓冲区包含生成的每个标记块的单个向量表示,而不考虑其长度.
Input Word Embeddings
我们的两个模型的输入层都是单个单词的向量表示。从有限的NER训练数据中学习单词类型的独立表示是一个困难的问题:有太多的参数需要可靠地估计。由于许多语言都有正字法或形态学证据表明某物是名称(或不是名称),所以我们需要对单词拼写敏感的表示。因此,我们使用了一个模型,该模型通过组成单词的字符的表示来构造单词的表示(4.1)。我们的第二直觉是,名字,可能个别地是相当不同的,在大语料库的规则的上下文出现。因此,我们使用从对词序敏感的大型语料库中获得的嵌入。最后,为了防止模型过于依赖于一种表现形式或另一种表现形式,我们使用了dropout训练,并发现这对良好的泛化性能至关重要。
Character-based models of words
我们的工作与以前大多数方法的一个重要区别是,我们在训练中学习字符级特征,而不是手工设计单词的前缀和后缀信息。学习字符级嵌入具有学习特定于当前任务和领域的表示形式的优势。它们已被发现对于形态丰富的语言和处理词性标记和语言建模(Ling等,2015b)或依赖解析(Ballesteros等,2015)等任务非常有用。
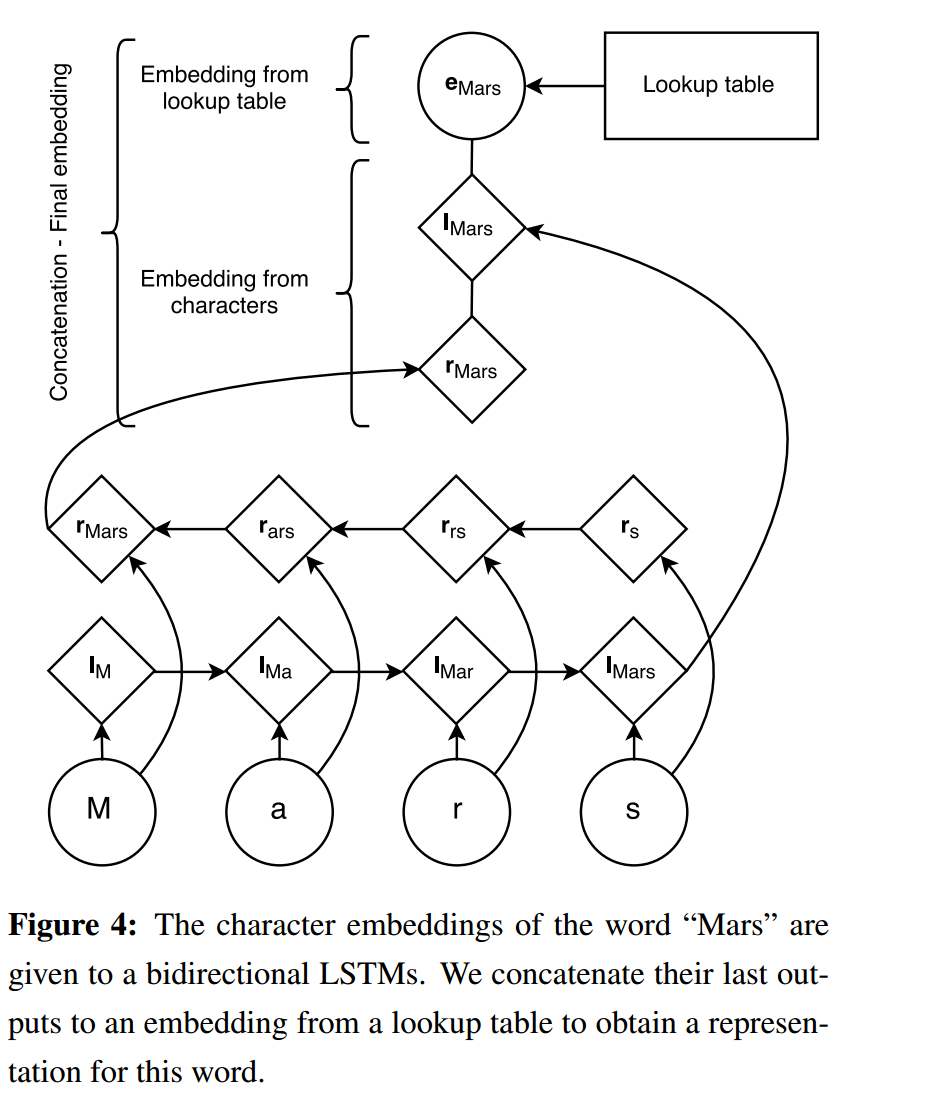
图4描述了我们的体系结构,它根据单词的字符为单词生成嵌入词。一个随机初始化的字符查找表包含每个字符的嵌入。一个单词中每个字符对应的字符嵌入是按照正向和反向LSTM的顺序给出的。从其字符派生的单词的嵌入是其来自双向LSTM的前向和后向表示的连接。然后,将这个字符级表示与单词查询表中的单词级表示连接起来。在测试期间,在查找表中没有嵌入的单词被映射到UNK嵌入。为了训练UNK嵌入,我们用概率为0:5的UNK嵌入替换单例。在我们所有的实验中,前向和后向字符LSTMs的隐藏维数各为25,这使得我们的基于字符的单词表示具有50维。
像RNNs和LSTMs这样的递归模型能够对很长的序列进行编码,但是它们的表现形式偏向于它们最近的输入。因此,我们期望前向LSTM的最终表示是单词后缀的准确表示,后向LSTM的最终状态是其前缀的更好表示。替代方法——最显著的是卷积网络——已经被提出用来从字符中学习单词的表示(Zhang et al., 2015;金正日et al ., 2015)。然而,convnets旨在发现其输入的位置不变特性。虽然这是适合很多问题,例如,图像识别(一只猫可以出现在任何图片),我们认为是位置相关的重要信息(例如,前缀和后缀编码的信息与词干不同),使LSTMs成为一个先验的更好的函数类,用于建模单词及其字符之间的关系。
Pretrained embeddings
如Collobert等人(2011)所述,我们使用预先训练好的词嵌入来初始化查找表。我们观察到,与随机初始化的词相比,使用预先训练的词嵌入有显著的改进。嵌入件使用skip-n-gram (Ling等,2015a)进行预训练,这是word2vec (Mikolov等,2013a)的一个变体,用于解释词序。这些嵌入在培训期间进行了微调。
Dropout training
最初的实验表明,字符级嵌入与预先训练的单词表示一起使用时,并不能提高我们的整体性能。为了鼓励模型依赖于这两种表示,我们使用了dropout训练(Hinton et al., 2012),在图1中双向LSTM的输入之前,将dropout掩码应用到最后的嵌入层。使用dropout后,我们发现我们的模型性能有了显著的改善(见表5)。
Experiments
Training
训练通过BP算法更新参数。用SGD以0.01的学习率优化参数,以5.0作为梯度的阈值。
LSTM-CRF模型用前向和后向LSTM各一个独立层,维度为100,并加入了0.5的dropout。
Stack-LSTM每一个stack用了2个100维的网络层,用16维的向量表示actoion,输出向量为20维。这个模型也加入了dropout,dropout rate通过调试,采用最好的那一个(不固定),采用贪婪模型,获取局部最优。
Data Sets
我们在不同的数据集上测试我们的模型,以进行命名实体识别。为了证明我们的模型泛化到不同语言的能力,我们展示了CoNLL-2002和CoNLL- 2003数据集的结果(Tjong Kim Sang, 2002;Tjong Kim Sang和De Meulder, 2003),其中包含英语、西班牙语、德语和荷兰语的独立命名实体标签。所有数据集包含四种不同类型的命名实体:位置、人员、组织和其他不属于前三种类型的实体。虽然POS标签对所有数据集都是可用的,但是我们没有在我们的模型中包含它们。我们没有执行任何数据预处理,除了用英文中的0替换每个数字尼珥的数据集。
Results
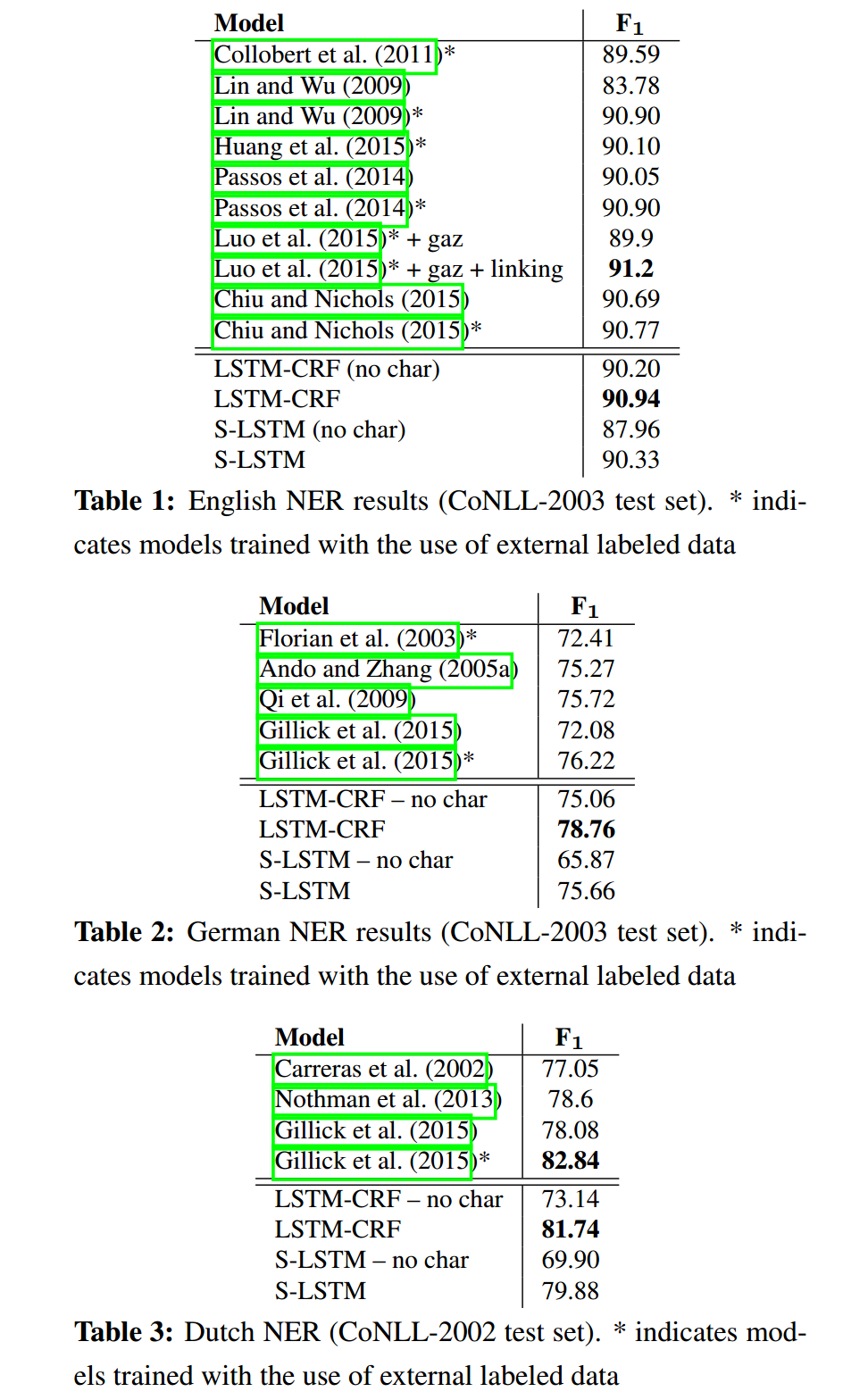
表1展示了我们与其他英语命名实体识别模型的比较。为了使我们的模型和其他模型之间的比较公平,我们报告了其他模型的得分,这些模型使用和不使用外部标记数据,如地名表和知识库。我们的模型不使用地名表或任何外部标记的资源。在这项任务中,罗等人(2015)的得分最高。他们通过联合建模NER和实体连接任务获得了91.2的F1 (Hoffart et al., 2011)。他们的模型使用了很多手工设计的功能,包括拼写功能、WordNet集群、Brown集群、POS标签、chunk标签,以及词干提取和外部知识库(如Freebase和Wikipedia)。我们的LSTM-CRF模型优于所有其他系统,包括使用外部标记数据(如地名表)的系统。除了Chiu和Nichols(2015)提出的模型外,我们的StackLSTM模型也优于所有不包含外部特征的先前模型。
表2、3和4分别展示了我们对德语、荷兰语和西班牙语的NER与其他模型的比较结果。在这三种语言中,LSTM-CRF模型的性能显著优于所有以前的方法,包括使用外部标记数据的方法。唯一的例外是荷兰,Gillick等人(2015)的模型可以更好地利用来自其他NER数据集的信息。与不使用外部数据的系统相比,Stack-LSTM还始终呈现最新的(或接近的)结果。
从表中可以看出,Stack-LSTM模型更依赖于基于字符的表示来实现竞争性能;我们假设LSTM-CRF模型需要较少的正投影信息,因为它能从双向lstm中获得更多的上下文信息;但是,堆栈LSTM模型一个接一个地消耗单词,并且在分解单词时仅依赖单词表示