deepwalk学习笔记
DeepWalk
简介
-
将节点表示为向量,保留网络结构信息
-
DeepWalk将随机游走得到的节点序列当做句子,从截断的随机游走序列中得到网络的局部信息,再通过局部信息来学习节点的潜在表示。
-
可扩展、可并行、可处理稀疏网络
-
可对网络进行全局观察
DeepWalk将一个图作为输入,并产生一个潜在表示(将图中的每个节点表示为一个向量)作为输出。

算法要求
-
适应性:社交网络是不断变化的,当网络发生变化时,可对对整个网络新进行计算。
-
社区意识:节点在潜在表示的维度空间中的距离,应该表示网络中对应的成员的相似度,以此保证网络的同质性。
-
低维:当被标记的成员很少时,低维的模型一般表现的更好,并且收敛和推理速度更快。
-
连续性:需要通过图的潜在表示来对连续空间中的部分社区成员进行建模。除了提供对社区成员资格的细微视图之外,连续表示还可以使社区之间的决策界限平滑,从而实现更强大的分类。
算法大致思路
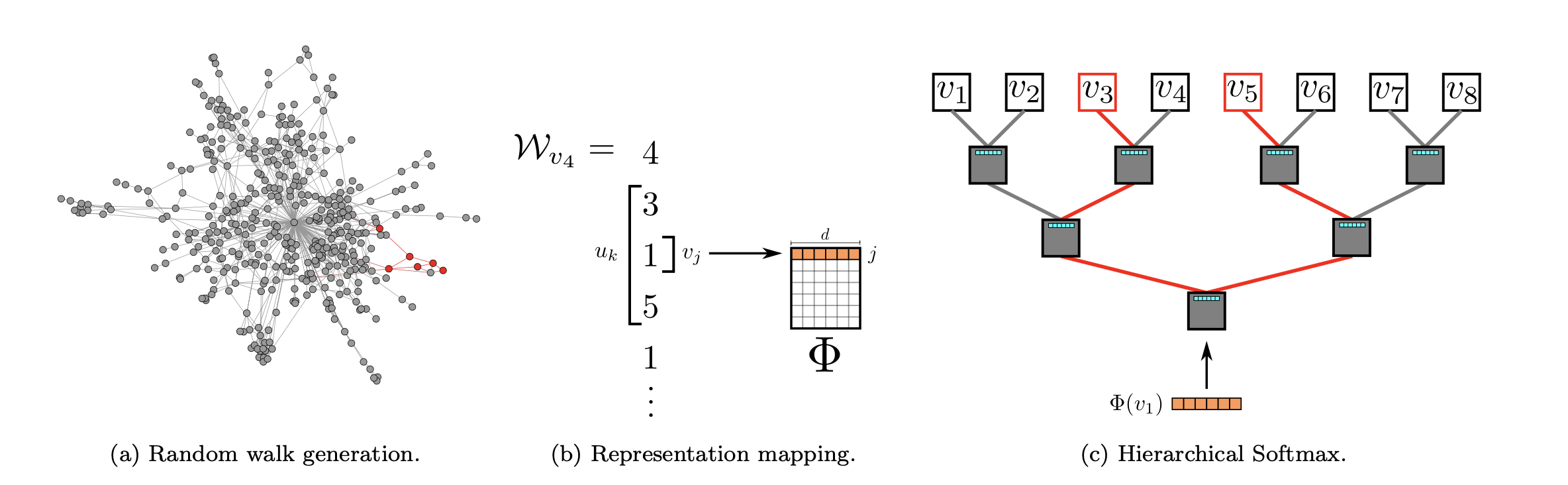
1、随机游走
将从顶点Vi开始的随机游走序列表示为Wvi。Wvij表示序列Wvi中的第j个点。其中,Wvi1为Vi,Wvik+1是从Wvik的邻居中随机选择的节点。随机游走得到的序列中包含了网络的局部结构信息。

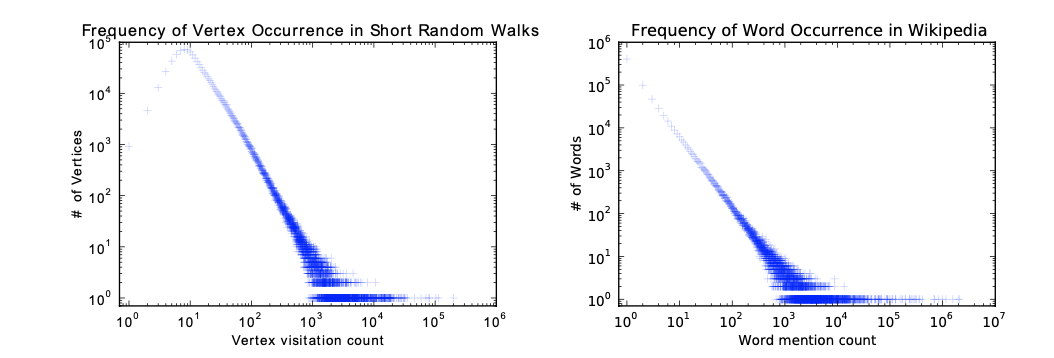
当图中节点的度遵循幂律分布(y=cx-r,y是度数为r的节点的出现的频率;直观上说,就是度数大的节点比较少,度数小的节点比较多)时,短随机游走中顶点出现的频率也将遵循幂律分布。
因为自然语言中单词出现的频率遵循类似的分布,所以用于建模自然语言分布的技术,可以用于对随机游走得到的序列进行建模。
-
语言建模的目标是估计出现在语料库中的特定序列的可能性。即给定$W_n=(W_0,W_1,...,W_n)$的序列,其中$W_i \in V$,($V$是词汇表),我们想最大化$P_r(W_n|W_0,W_1,...,W_n-1)$,随机游走得到的序列可以被认为是一种特殊语言的短句,类比语言建模可以得到:在随机游走中给定迄今为止访问的所有先前顶点的情况下,下一个顶点是的可能性可以表示为:
$$P_r(V_i|V_0,V_1,...,V_i-1)$$ -
为了得到节点的潜在表示,引入映射函数$\Phi:v \in V \rightarrow R^{|V|*d}$,$|V|*d$矩阵$\Phi$表示图中每个顶点的在d维空间中的潜在表示。这样公式(1)可以表示为:
$$P_r(V_i|V_0,V_1,...,V_i-1)$$
3.对语言建模进行relaxation
-
不是通过上下文预测单词,而是使用单词来预测上下文,上下文由单词左右两边的单词组成。(SkipGram)
-
不考虑句子中上下文出现的顺序,最大化出现在上下文中的所有单词的概率。对于顶点表示建模,就产生了下面的优化问题:
$$P_r(V_i|V_0,V_1,...,V_i-1)$$
SkipGram使用独立性假设,条件概率(3)近似为:
该算法由两个主要组件组成:一个随机游走生成器和一个语言模型更新程序。