Kafka学习笔记_尚硅谷
第1章 Kafka概述
1.1 定义
Kafka是一个分布式的基于开发/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
1.2 消息队列
1.2.1传统消息队列的应用场景
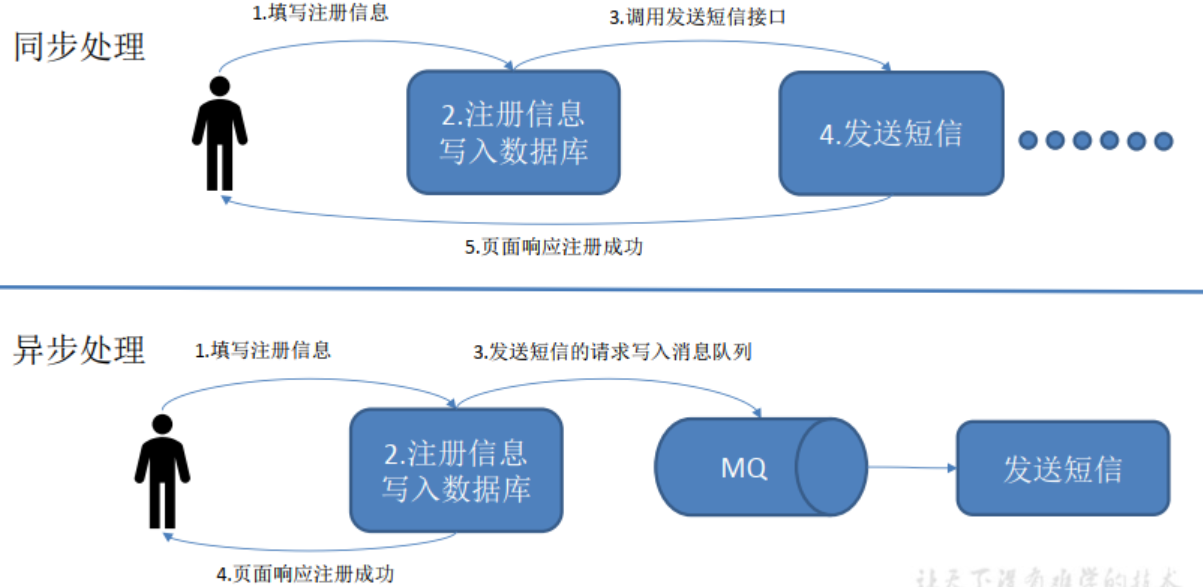
处理异步:解耦
处理高峰:削峰
使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守相同的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程之间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)削峰
灵活性&峰值处理能力,在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能偶是关键组件顶住突发的访问压力,而不会因为突发的超负荷的情况而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.2.2消息队列的两种模式
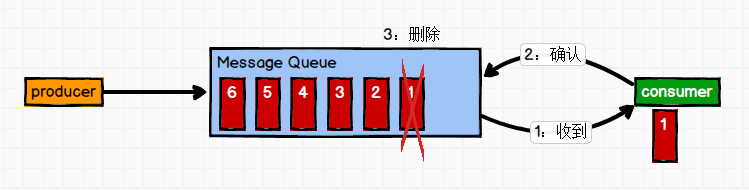
(1)点对点模式
(一对一,消费者主动拉取数据,消息收到后消息清除)缺点:不可复用
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后, queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式
(一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。

2种模式:
费者拉取: 缺点:消费者会一直轮训查费资源、队列要保存不同消息
队列推送: 缺点:消费者速率不一致,某些条件下可能造成消息不是对等
1.3 Kafka入门_基础架构
一个topic的分区,只能被同一个消费者组里的一个消费者消费

- Producer : 消息生产者,就是向 Kafka ;
- Consumer : 消息消费者,向 Kafka broker 取消息的客户端;
- Consumer Group (CG): 消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :经纪人 一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。
- Topic : 话题,可以理解为一个队列, 生产者和消费者面向的都是一个 topic;
- Partition: 为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
- Replica: 副本(Replication),为保证集群中的某个节点发生故障时, 该节点上的 partition 数据不丢失,且 Kafka仍然能够继续工作, Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- Leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- Follower: 每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。 leader 发生故障时,某个 Follower 会成为新的 leader。
apache-flume-1.7.0-bin.tar.gz
apache-hive-1.2.1.bin.tar.gz
hadoop-2.7.2.tar.gz
jdk-8u144-linux-x64.tar.gz
mysql-libs
zookeeper-3.4.10.tar.gz
第2章.Kafka入门
2.1安装部署
2.1.1集群规划
yyq10 yyq20 yyq21
zk zk zk
kafka kafka kafka
2.1.2 安装zk并启动
https://blog.csdn.net/qq_35663625/article/details/98848947
./zkServer.sh status
Error contacting service. It is probably not running 可以关闭防火墙
安装kafka:
hostname
mkdir /opt/module
tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module
cd /opt/module/
mv kafka_2.11-0.11.0.0/ kafka
cd kafka/config/
vi server.properties
broker.id=0 #唯一的,其他机器+n
delete.topic.enable=true
log.dirs=/opt/module/kafka/logs
zookeeper.connect=yyq10:2181,yyq20:2181,yyq21:2181
其他机器做同样配置,并改broker.id
统一启动:
/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
关闭:
/opt/module/kafka/bin/kafka-server-stop.sh

2.1.3 Kafka命令行操作
查看
查看当前服务器中的所有topic (新版本--zookeeper替换成了--bootstrap-server)
bin/kafka-topics.sh --zookeeper yyq10:2181 --list

创建topic
bin/kafka-topics.sh --zookeeper yyq10:2181 --create --replication-factor 2 --partitions 2 --topic first
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数

查看 /opt/module/kafka/logs
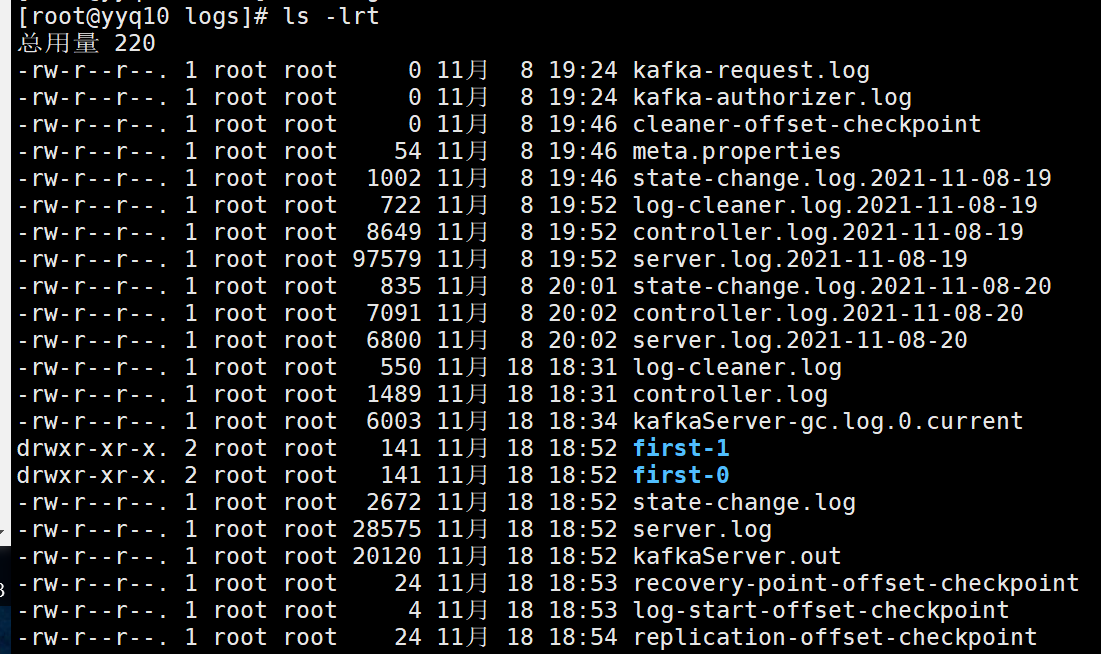
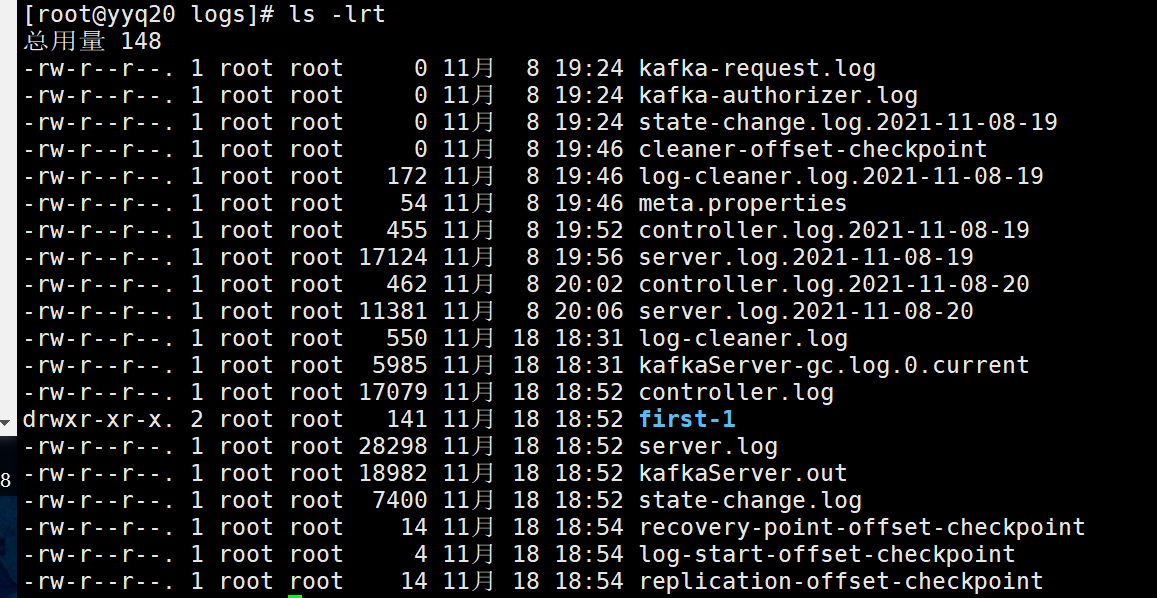
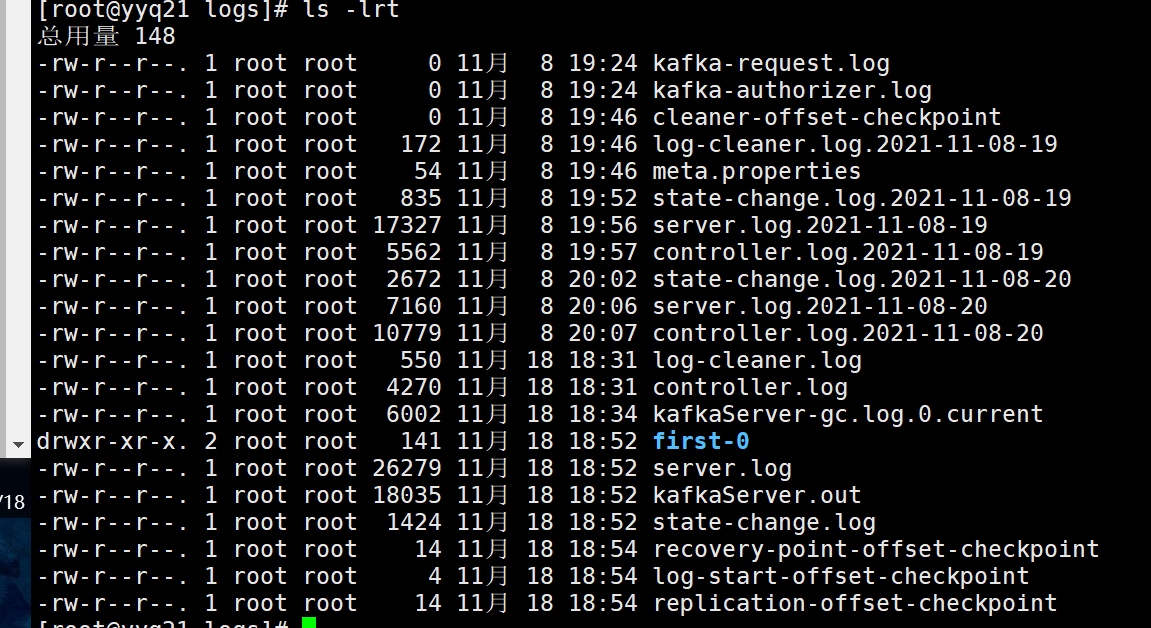
yyq10: first-0 first-1
yyq20: first-1
yyq21: first-0
结果:2个分区(--partitions 0、1后面的数字)、2个副本(--replication-factor)
删除topic
bin/kafka-topics.sh --zookeeper yyq10:2181 --delete --topic first

提示被标记删除
需要server.properties中设置delete.topic.enable=true否则只是标记删除
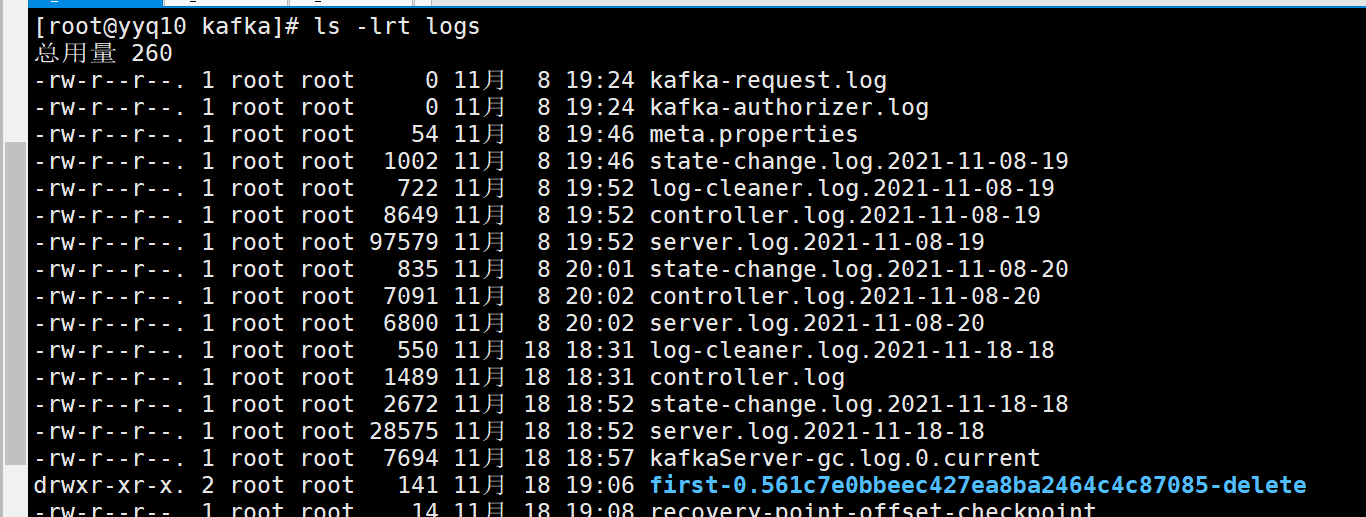
等等再看就没有了,再次创建
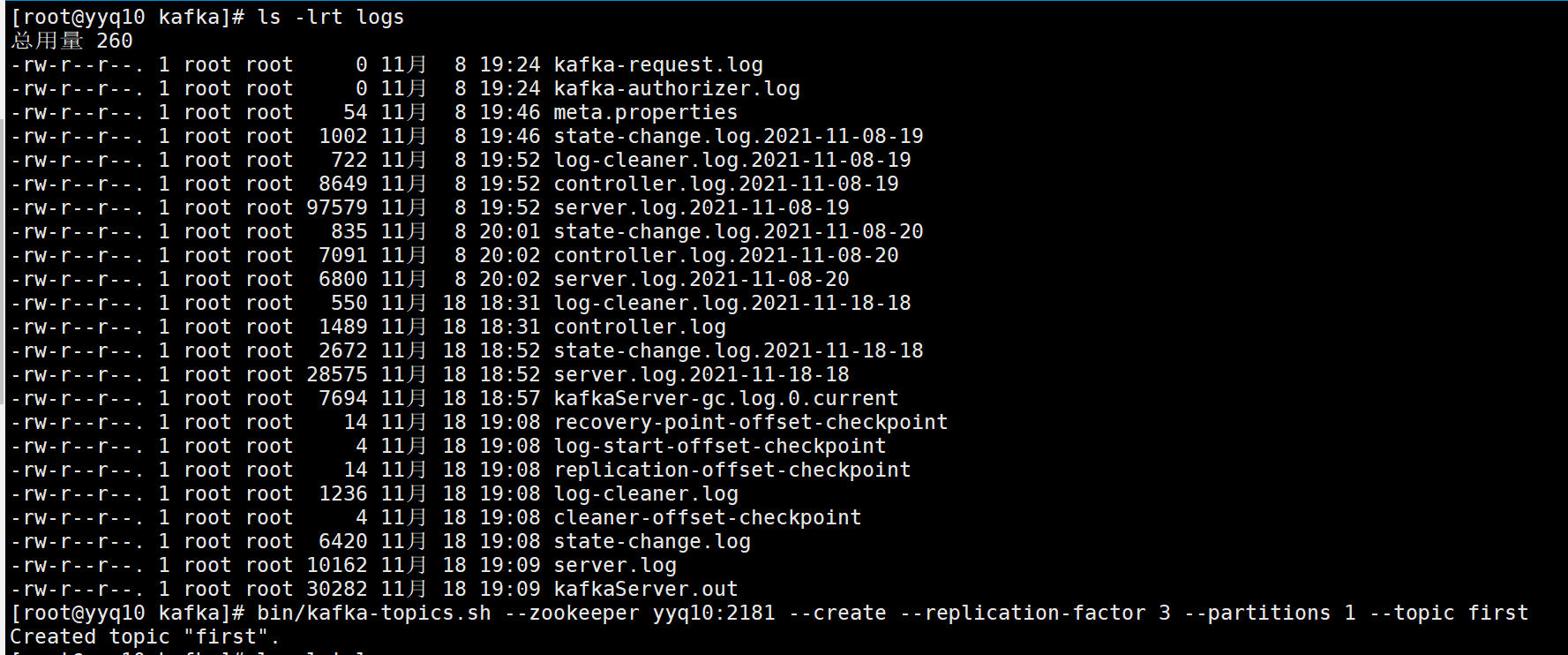
查看某个topic的详情
bin/kafka-topics.sh --zookeeper yyq10:2181 --describe --topic first
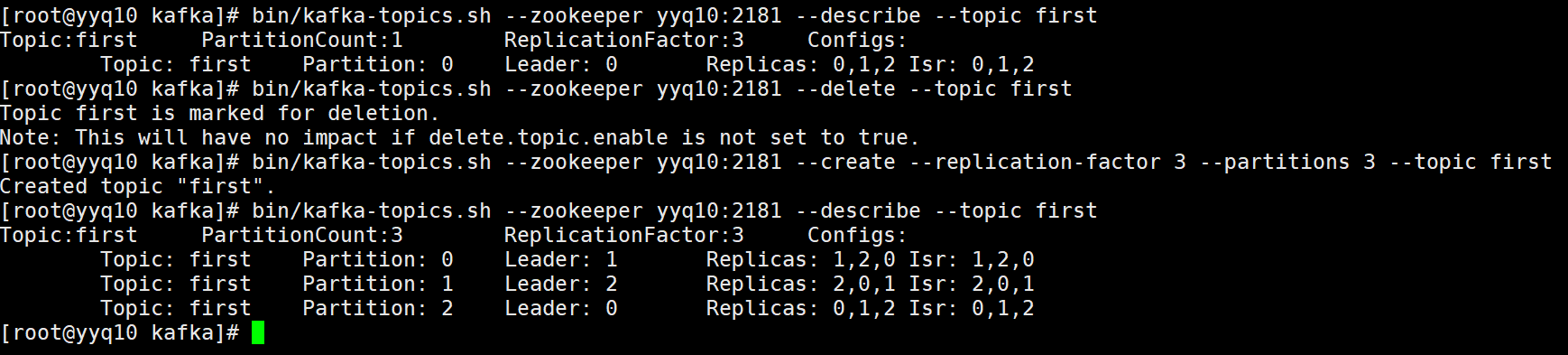
0号分区的leader存在id为1的kafka中,并且副本存在为id为1的kafka中
继续创建topic
bin/kafka-topics.sh --zookeeper yyq10:2181 --create --replication-factor 3 --partitions 4 --topic second

继续创建topic
bin/kafka-topics.sh --zookeeper yyq10:2181 --create --replication-factor 4 --partitions 2 --topic third

报错,因为副本数超出集群brokers数量3
目前已经有了主题,还缺消费者和生产者
生产者命令:/opt/module/kafka/bin/kafka-console-producer.sh
消费者命令:/opt/module/kafka/bin/kafka-console-consumer.sh
进入生产者,发送消息
yyq10进入生产者
bin/kafka-console-producer.sh --topic first --broker-list yyq10:9092

进入生产者准备发消息
进入消费者,消费消息
yyq20进入消费者
bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic first

提示:不推荐将控制台与过时的消费者一起使用,以后可能会删除,考虑使用新的用户通过[bootstrap-server]而不是[zookeeper]。但是目前还能用。
在yyq10生产者生产消息


消费者收到了
如果yyq21消费者并且想要冲头消费,需要添加参数 --from-beginning,否则获取不到之前生产的消息

--from-beginning:会把主题中以往所有的数据读取出来
使用新命令 bootstrap-server替代zookeeper
在yyq20上使用 bootstrap-server
bin/kafka-console-consumer.sh --bootstrap-server yyq10:9092 --topic first

在生产者生产后,可以消费,加--from-beginning同样也可以从头消费(注意最大保存时间设置的是7天,7天后加--from-beginning也获取不到了)
再查看 logs
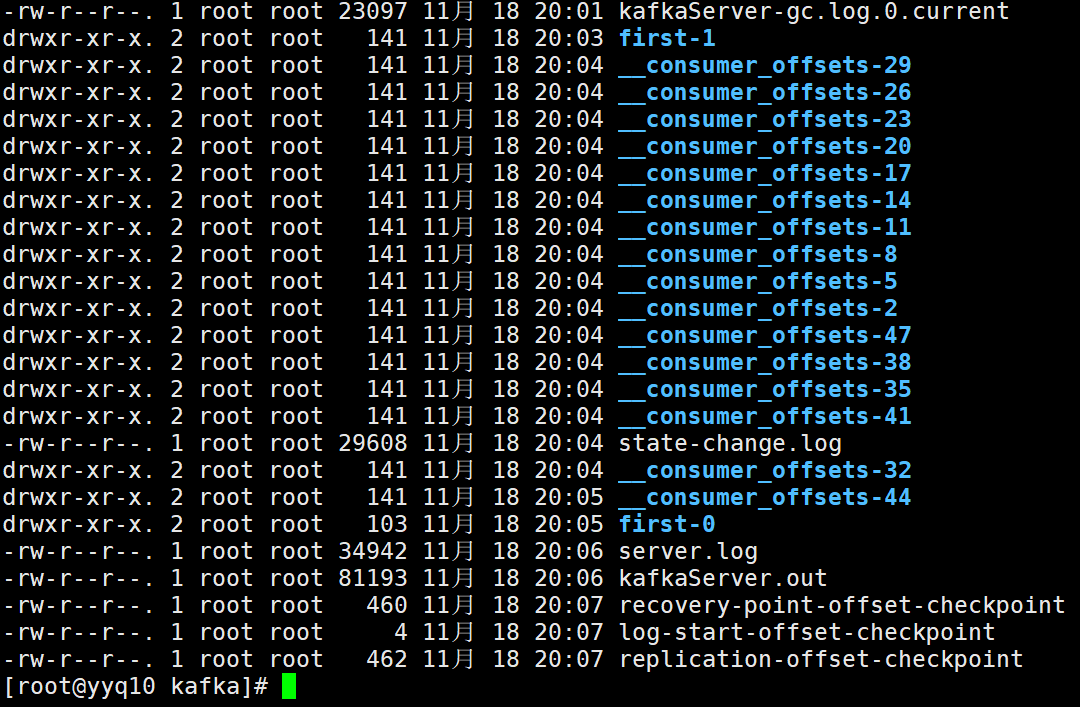
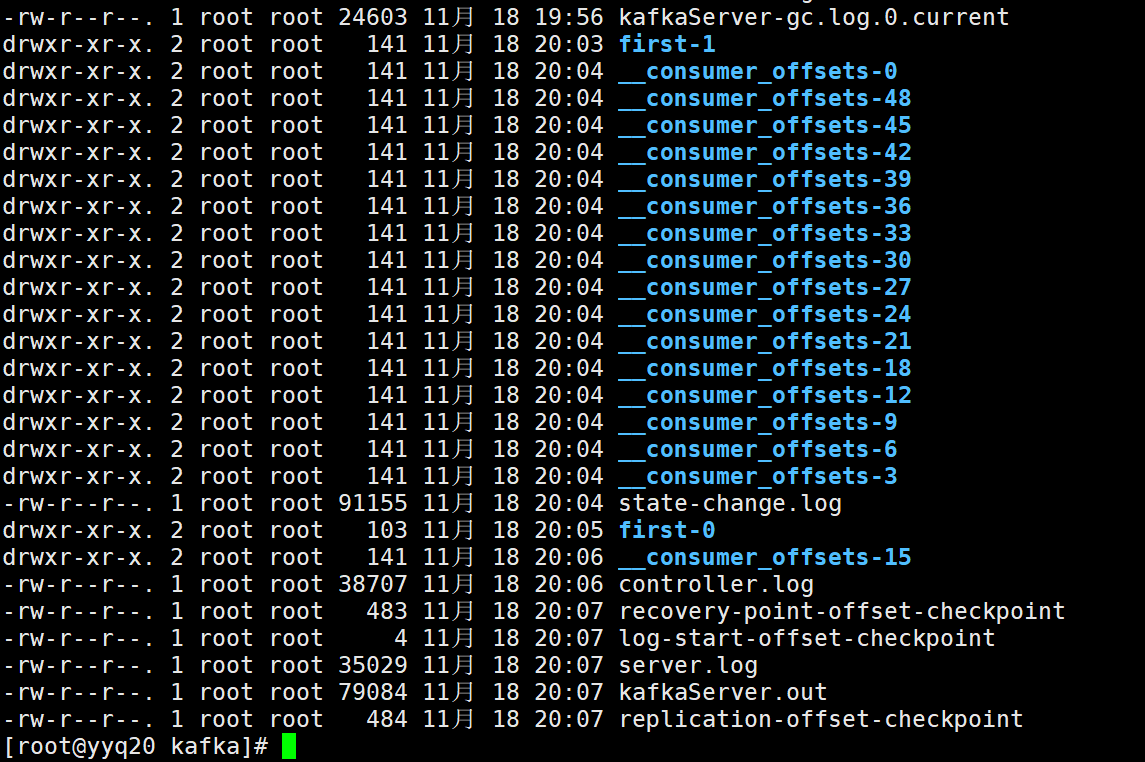
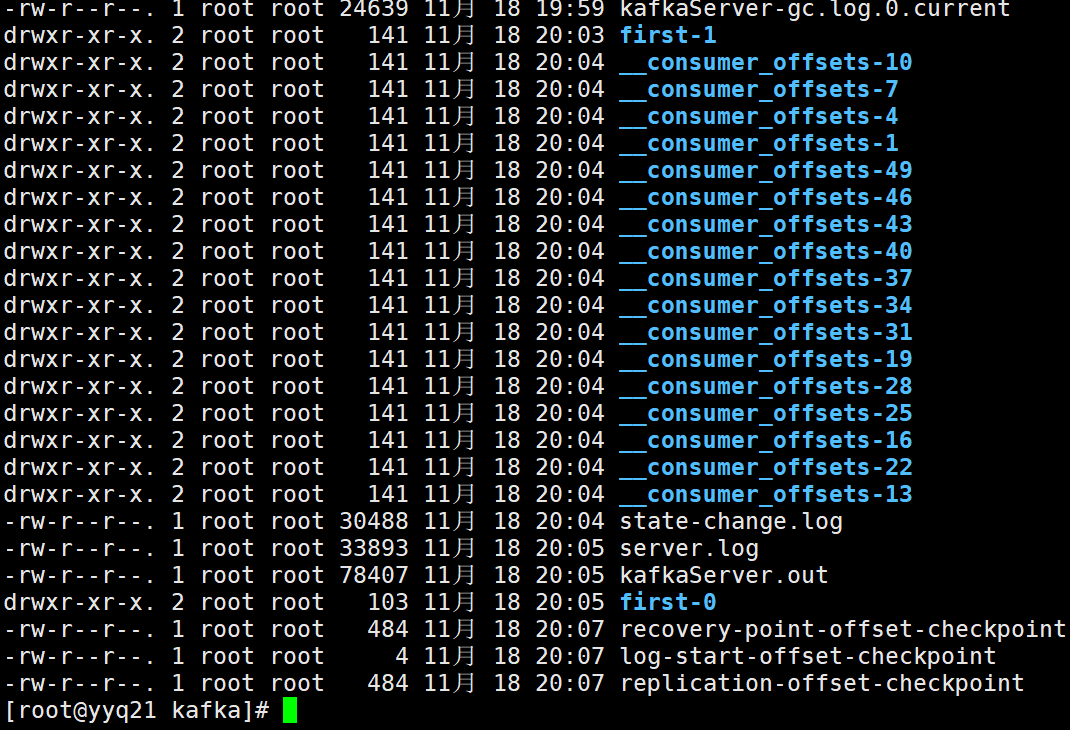
使用 bootstrap-server 消费者数据存储在kafka本地的机制变了,为了做负载,消费者数据的偏移量默认50个分区,轮询分配在集群中。
修改分区数
bin/kafka-topics.sh --zookeeper yyq10:2181 --alter --topic first --partitions 6
server.properties
#broker 的全局唯一编号,不能重复
broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
2.2 Kafka 数据日志分离

这里除了zookeeper其他都是kafka的信息(用id区分集群中各注册信息等)
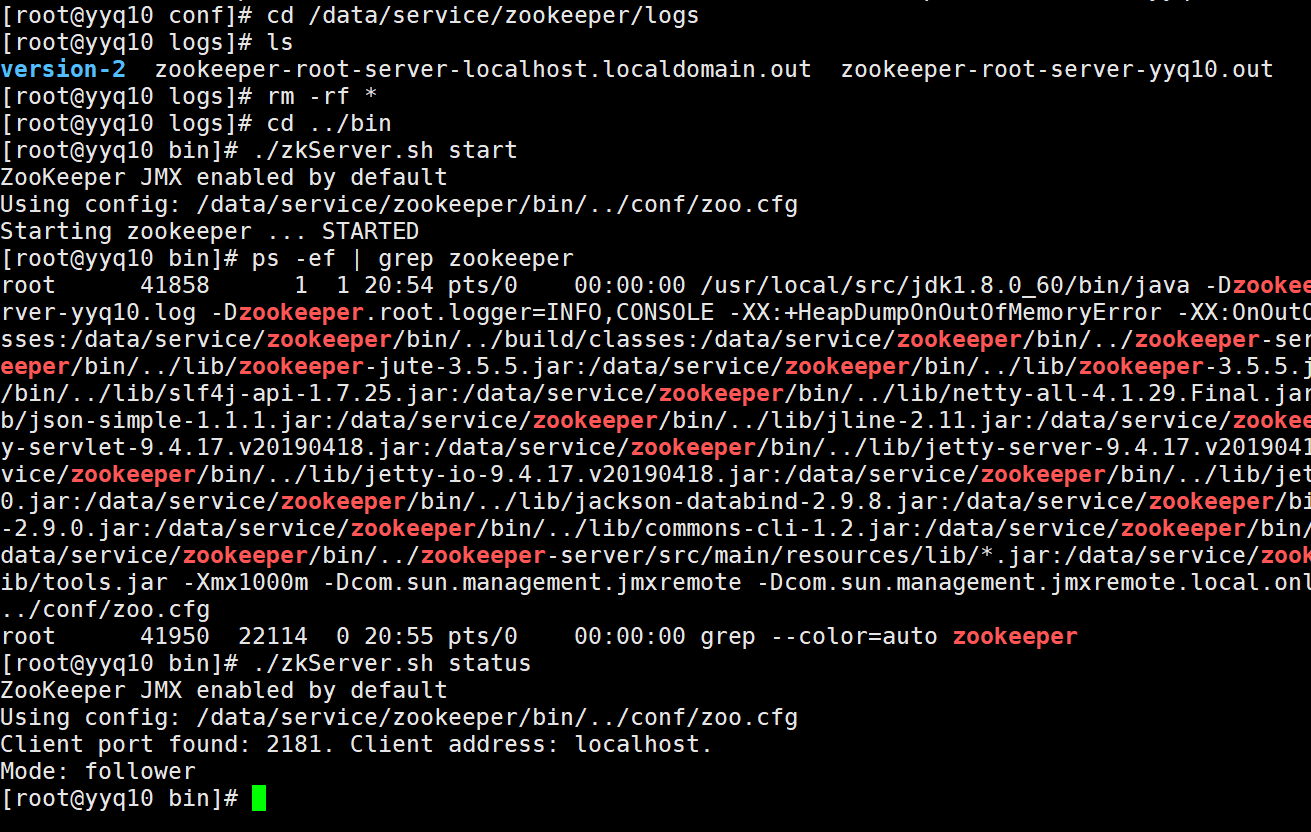

数据已清空
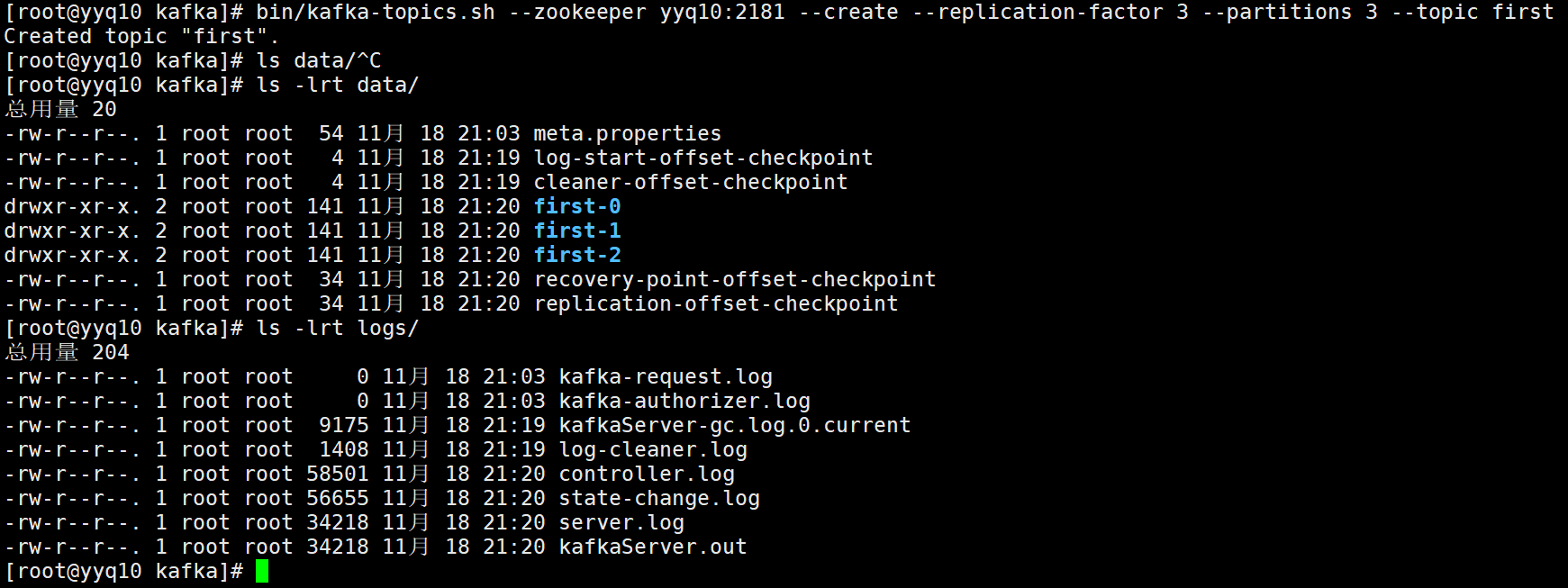
数据和日志已分离(多此一举,第一次配置可以直接把log.dirs配置改成data..)
ll data/first-1/00000000000000000000.log
实际数据存放地
写测试

查看数据
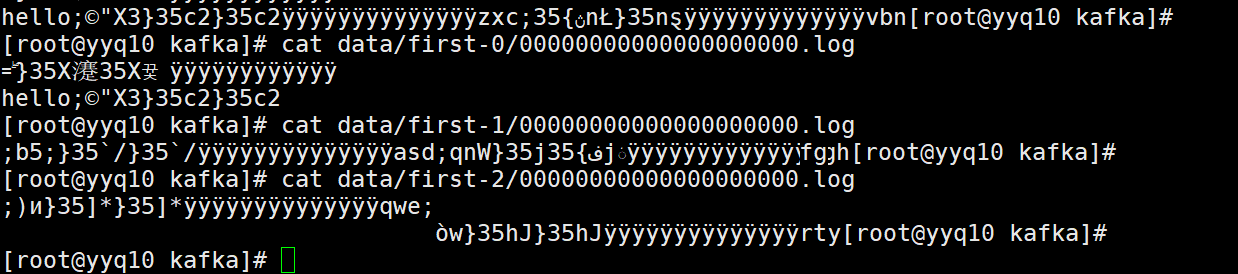
轮询存放
第三章 Kafka架构深入
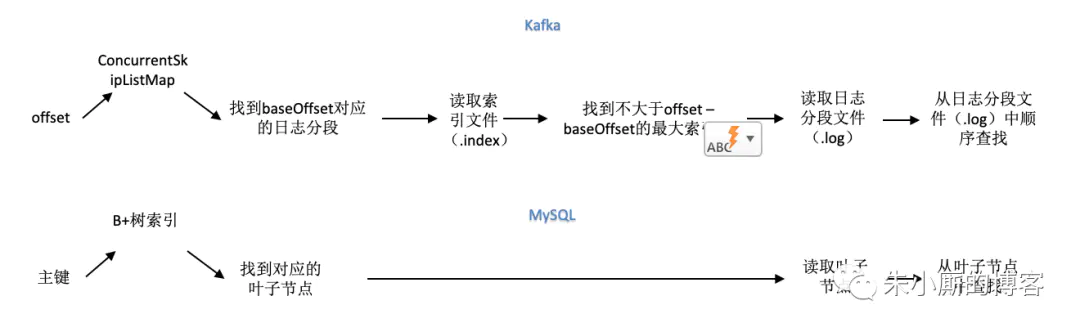
3.1 Kafka 工作流程及文件存储机制
3.1.1 kafka工作流程

topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。(topic = N partition,partition = log)Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。 consumer组中的每个consumer, 都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。(producer -> log with offset -> consumer(s))
3.1.2 kafka文件存储机制

00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log

补充:
*index*文件存储大量的索引信息
.log文件存储大量的数据
通过增加索引,缩短了查阅的时间。空间和时间上的互换。
首先Kafka的索引是稀疏索引,避免索引文件占用过多的内存。对应的就是Broker 端参数log.index.interval.bytes 值,默认4KB,即4KB的消息建一条索引。
Kafka中有三大类索引:位移索引、时间戳索引和已中止事务索引。分别对应了.index、.timeindex、.txnindex文件。
1、AbstractIndex.scala:抽象类,封装了所有索引的公共操作
2、OffsetIndex.scala:位移索引,保存了位移值和对应磁盘物理位置的关系
3、TimeIndex.scala:时间戳索引,保存了时间戳和对应位移值的关系
4、TransactionIndex.scala:事务索引,启用Kafka事务之后才会出现这个索引(本文暂不涉及事务相关内容)
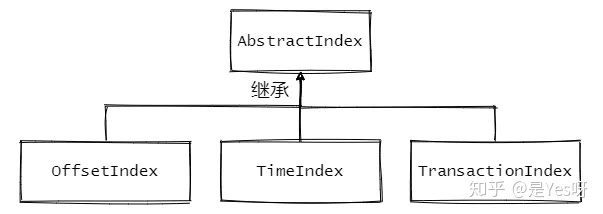
先来看看AbstractIndex的定义
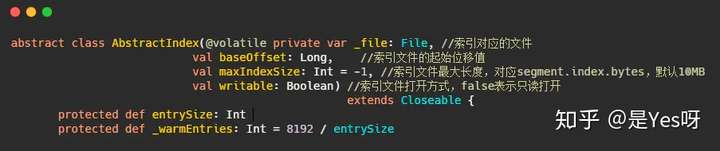
AbstractIndex的定义在代码里已经注释了,成员变量里面还有个entrySize。这个变量其实是每个索引项的大小,每个索引项的大小是固定的。
entrySize
在OffsetIndex中是override def entrySize = 8,8个字节。
在TimeIndex中是override def entrySize = 12,12个字节。
为何是8 和12?
在OffsetIndex中,每个索引项存储了位移值和对应的磁盘物理位置,因此4+4=8,但是不对啊,磁盘物理位置是整型没问题,但是AbstractIndex的定义baseOffset来看,位移值是长整型,不是因为8个字节么?
因此存储的位移值实际上是相对位移值,即真实位移值-baseOffset的值。
相对位移用整型存储够么?够,因为一个日志段文件大小的参数log.segment.bytes是整型,因此同一个日志段对应的index文件上的位移值-baseOffset的值的差值肯定在整型的范围内。
为什么要这么麻烦,还要存个差值?
1、一个索引项节省了4字节,省空间资源。
2、同样的内存资源,索引项越短,能够存储的就越多,直接命中的概率就越高了。
互相转化的源码如下,就这么个简单的操作:
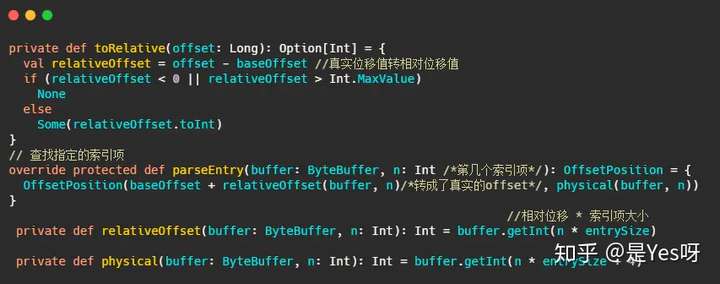
上述解释了位移值是4字节,因此TimeIndex中时间戳8个字节 + 位移值4字节 = 12字节。
_warmEntries
这个是干什么用的?
首先思考下我们能通过索引项快速找到日志段中的消息,但是我们如何快速找到我们想要的索引项呢?一个索引文件默认10MB,一个索引项8Byte,因此一个文件可能包含100多W条索引项。
不论是消息还是索引,其实都是单调递增,并且都是追加写入的,因此数据都是有序的。在有序的集合中快速查询,脑海中突现的就是二分查找了!
那就来个二分!
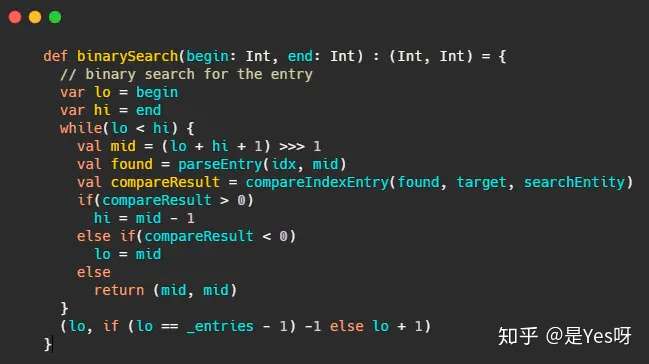
这和_warmEntries有什么关系?首先想想二分有什么问题?
就Kafka而言,索引是在文件末尾追加的写入的,并且一般写入的数据立马就会被读取。所以数据的热点集中在尾部。并且操作系统基本上都是用页为单位缓存和管理内存的,内存又是有限的,因此会通过类LRU机制淘汰内存。
看起来LRU非常适合Kafka的场景,但是使用标准的二分查找会有缺页中断的情况,毕竟二分是跳着访问的。
这里要说一下kafka的注释写的是真的清晰,咱们来看看注释怎么说的
when looking up index, the standard binary search algorithm is not cache friendly, and can cause unnecessary
page faults (the thread is blocked to wait for reading some index entries from hard disk, as those entries are not
cached in the page cache)
翻译下:当我们查找索引的时候,标准的二分查找对缓存不友好,可能会造成不必要的缺页中断(线程被阻塞等待从磁盘加载没有被缓存到page cache 的数据)
注释还友好的给出了例子
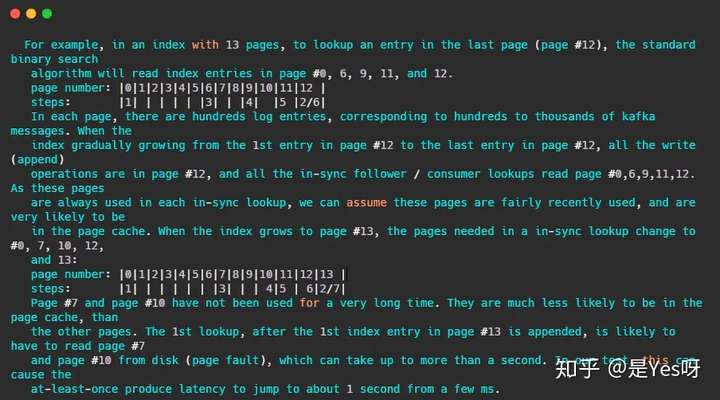
简单的来讲,假设某索引占page cache 13页,此时数据已经写到了12页。按照kafka访问的特性,此时访问的数据都在第12页,因此二分查找的特性,此时缓存页的访问顺序依次是0,6,9,11,12。因为频繁被访问,所以这几页一定存在page cache中。
当第12页不断被填充,满了之后会申请新页第13页保存索引项,而按照二分查找的特性,此时缓存页的访问顺序依次是:0,7,10,12。这7和10很久没被访问到了,很可能已经不在缓存中了,然后需要从磁盘上读取数据。注释说:在他们的测试中,这会导致至少会产生从几毫秒跳到1秒的延迟。
基于以上问题,Kafka使用了改进版的二分查找,改的不是二分查找的内部,而且把所有索引项分为热区和冷区
这个改进可以让查询热数据部分时,遍历的Page永远是固定的,这样能避免缺页中断。
看到这里其实我想到了一致性hash,一致性hash相对于普通的hash不就是在node新增的时候缓存的访问固定,或者只需要迁移少部分数据。
好了,让我们先看看源码是如何做的
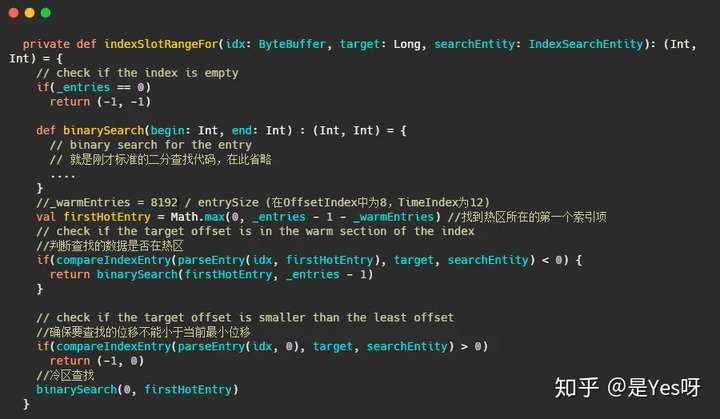
实现并不难,但是为何是把尾部的8192作为热区?
这里就要再提一下源码了,讲的很详细。
This number is small enough to guarantee all the pages of the "warm" section is touched in every warm-section lookup. So that, the entire warm section is really "warm".
When doing warm-section lookup, following 3 entries are always touched:
indexEntry(end),
indexEntry(end-N), and
indexEntry((end*2 -N)/2).
If page size >= 4096, all the warm-section pages (3 or fewer) are touched, when wetouch those 3 entries.
As of 2018, 4096 is the smallest page size for all the processors (x86-32, x86-64, MIPS, SPARC, Power, ARM etc.).
大致内容就是现在处理器一般缓存页大小是4096,那么8192可以保证页数小于等3,用于二分查找的页面都能命中 ()
This number is large enough to guarantee most of the in-sync lookups are in the warm-section. With default Kafka settings, 8KB index corresponds to about 4MB (offset index) or 2.7MB (time index) log messages.
8KB的索引可以覆盖 4MB (offset index) or 2.7MB (time index)的消息数据,足够让大部分在in-sync内的节点在热区查询
以上就解释了什么是_warmEntries,并且为什么需要_warmEntries。
可以看到朴素的算法在真正工程上的应用还是需要看具体的业务场景的,不可生搬硬套。并且彻底的理解算法也是很重要的,例如死记硬背二分,怕是看不出来以上的问题。还有底层知识的重要性。不然也是看不出来对缓存不友好的。
从Kafka的索引冷热分区到MySQL InnoDB的缓冲池管理
从上面这波冷热分区我又想到了MySQL的buffer pool管理。MySQL的将缓冲池分为了新生代和老年代。默认是37分,即老年代占3,新生代占7。即看作一个链表的尾部30%为老年代,前面的70%为新生代。替换了标准的LRU淘汰机制。

MySQL的缓冲池分区是为了解决预读失效和缓存污染问题。
1、预读失效:因为会预读页,假设预读的页不会用到,那么就白白预读了,因此让预读的页插入的是老年代头部,淘汰也是从老年代尾部淘汰。不会影响新生代数据。
2、缓存污染:在类似like全表扫描的时候,会读取很多冷数据。并且有些查询频率其实很少,因此让这些数据仅仅存在老年代,然后快速淘汰才是正确的选择,MySQL为了解决这种问题,仅仅分代是不够的,还设置了一个时间窗口,默认是1s,即在老年代被再次访问并且存在超过1s,才会晋升到新生代,这样就不会污染新生代的热数据。
Kafka中的offset类比成InnoDB中的主键
参考资料:https://zhuanlan.zhihu.com/p/154577113
https://www.jianshu.com/p/abe1af87a889
https://www.cnblogs.com/kyoner/p/11080078.html
https://blog.csdn.net/zhuwentaolove/article/details/103417050
segment 英 [ˈseɡmənt , seɡˈment] 美 [ˈseɡmənt , seɡˈment]
n.部分;份;片;段;(柑橘、柠檬等的)瓣;弓形;圆缺 v.分割;划分
3.2 Kafka 生产者
3.2.1 生产者的分区策略
1)分区的原因
- 方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic又可以有多个 Partition 组成,因此整个集群就可以适应适合的数据了;
- 可以提高并发,因为可以以 Partition 为单位读写了。(联想到ConcurrentHashMap在高并发环境下读写效率比HashTable的高效)
2)分区的原则
我们需要将 producer 发送的数据封装成一个ProducerRecord 对象。
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(之后在基础上轮训),将这个值与 topic 可用的 partition 总数取余得到 partition值,也就是常说的 round-robin 算法(轮询调度)。
3.2.2数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic, topic 的每个 partition 收到producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果producer 收到 ack, 就会进行下一轮的发送,否则重发数据。
acknowledgement 英 [əkˈnɒlɪdʒmənt] 美 [əkˈnɑːlɪdʒmənt]
n.(对事实、现实、存在的)承认;感谢;谢礼;收件复函
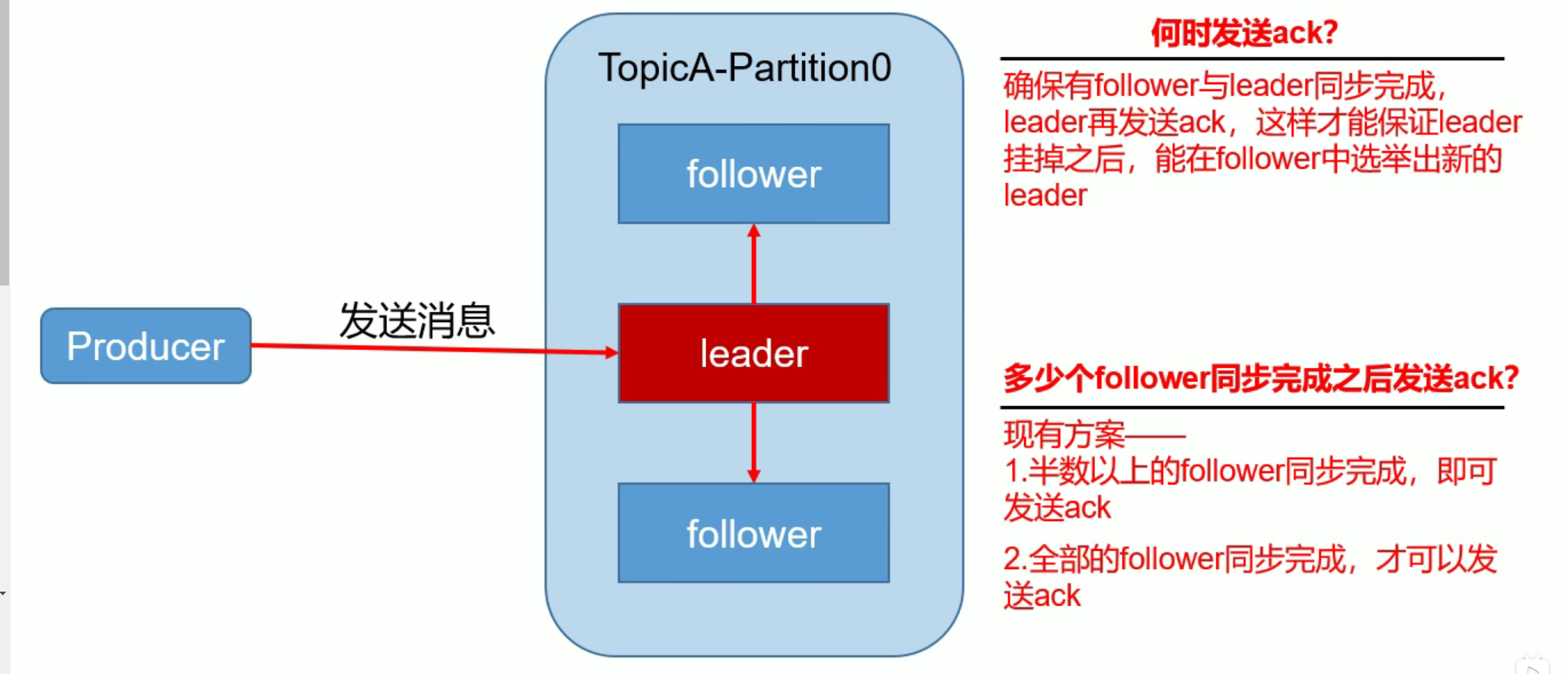
1)副本数据同步策略
| 序号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 半数以上完成同步, 就发送 ack | 延迟低 | 选举新的 leader 时,容忍 n 台节点的故障,需要 2n+1 个副本。(如果集群有2n+1台机器,选举leader的时候至少需要半数以上即n+1台机器投票,那么能容忍的故障,最多就是n台机器发生故障)容错率:1/2 |
| 2 |
全部完成同步,才发送ack |
选举新的 leader 时, 容忍 n 台节点的故障,需要 n+1 个副本(如果集群有n+1台机器,选举leader的时候只要有一个副本就可以了)容错率:1 | 延迟高 |
- 同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1 个副本,而 Kafka 的每个分区都有大量的数据, 第一种方案会造成大量数据的冗余。
- 虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
2)生产者ISR
采用第二种方案之后,设想以下情景: leader 收到数据,所有 follower 都开始同步数据,但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去,直到它完成同步,才能发送 ack。这个问题怎么解决呢?replica.lag.time.max.ms参数设定。 Leader 发生故障之后,就会从 ISR 中选举新的 leader。replica.lag.time.max.msDESCRIPTION: If a follower hasn't sent any fetch requests or hasn't consumed up to the leaders log end offset for at least this time, the leader will remove the follower from isrTYPE: longDEFAULT: 10000Source
3)生产者ACk应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。- 0: producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟, broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
- 1: producer 等待 broker 的 ack, partition 的 leader 落盘成功后返回 ack,如果在 follower同步成功之前 leader 故障,那么将会丢失数据;

- -1(all) : producer 等待 broker 的 ack, partition 的 leader 和 ISR 的follower 全部落盘成功后才返回 ack。但是如果在 follower 同步完成后, broker 发送 ack 之前, leader 发生故障,那么会造成数据重复。本质上还是kafka不支持acid,kafka引入事物即可解决,Kafka从0.11版本开始支持幂等性与事务性:
- https://www.cnblogs.com/smartloli/p/11922639.html
- https://blog.csdn.net/nazeniwaresakini/article/details/104220063
 助记:返ACK前,0无落盘,1一落盘,-1全落盘,(落盘:消息存到本地)
助记:返ACK前,0无落盘,1一落盘,-1全落盘,(落盘:消息存到本地)acksDESCRIPTION:The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:TYPE:stringDEFAULT:1VALID VALUES:[all, -1, 0, 1]Source
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
4)故障处理细节
LOG文件中的HW和LEO

- LEO:(Log End Offset)每个副本的最后一个offset (最大的)
- HW:(High Watermark)高水位,指的是消费者能见到的最大的 offset, ISR 队列中最小的 LEO
follower 故障和 leader 故障
- follower 故障:follower 发生故障后会被临时踢出 ISR,待该 follower 恢复后, follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
- leader 故障:leader 发生故障之后,会从 ISR 中选出一个新的 leader,之后,为保证多个副本之间的数据一致性, 其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader同步数据。
3.2.3 ExactlyOnce语义
将服务器的 ACK 级别设置为-1(all),可以保证 Producer 到 Server 之间不会丢失数据,即 At Least Once 语义。相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。在 0.11 版本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。Source
- At least once—Messages are never lost but may be redelivered.
- At most once—Messages may be lost but are never redelivered.
- Exactly once—this is what people actually want, each message is delivered once and only once.
要启用幂等性,只需要将 Producer 的参数中
enable.idempotence 设置为 true 即可。 Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时, Broker 只会持久化一条。但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。enable.idempotenceDESCRIPTION:When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. This is set to 'false' by default. Note that enabling idempotence requiresmax.in.flight.requests.per.connectionto be set to 1 andretriescannot be zero. Additionally acks must be set to 'all'. If these values are left at their defaults, we will override the default to be suitable. If the values are set to something incompatible with the idempotent producer, a ConfigException will be thrown.TYPE:booleanDEFAULT:falseSource
生产者总结
略3.3 Kafka消费者
3.3.1 消费方式
consumer 采用 pull(拉) 模式从 broker 中读取数据。
3.3.2 分区分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。、- round-robin循环
- range
partition.assignment.strategySelect between the "range" or "roundrobin" strategy for assigning分配 partitions to consumer streams.The round-robin partition assignor lays out规划 all the available partitions and all the available consumer threads. It then proceeds to do接着做 a round-robin assignment from partition to consumer thread. If the subscriptions订阅 of all consumer instances are identical完全同样的, then the partitions will be uniformly 均匀地distributed. (i.e.也就是说, the partition ownership counts will be within a delta of exactly one across all consumer threads.) Round-robin assignment is permitted only if:Range partitioning works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumer threads in lexicographic词典式的 order. We then divide the number of partitions by the total number of consumer streams (threads) to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.DEFAULT:rangeSource
- Every topic has the same number of streams within a consumer instance
- The set of subscribed topics is identical for every consumer instance within the group.
Kafka再平衡机制详解
1)Round Robin
关于Roudn Robin重分配策略,其主要采用的是一种轮询的方式分配所有的分区,该策略主要实现的步骤如下。这里我们首先假设有三个topic:t0、t1和t2,这三个topic拥有的分区数分别为1、2和3,那么总共有六个分区,这六个分区分别为:t0-0、t1-0、t1-1、t2-0、t2-1和t2-2。这里假设我们有三个consumer:C0、C1和C2,它们订阅情况为:C0订阅t0,C1订阅t0和t1,C2订阅t0、t1和t2。那么这些分区的分配步骤如下:- 首先将所有的partition和consumer按照字典序进行排序,所谓的字典序,就是按照其名称的字符串顺序,那么上面的六个分区和三个consumer排序之后分别为:

- 然后依次以按顺序轮询的方式将这六个分区分配给三个consumer,如果当前consumer没有订阅当前分区所在的topic,则轮询的判断下一个consumer:
- 尝试将t0-0分配给C0,由于C0订阅了t0,因而可以分配成功;
- 尝试将t1-0分配给C1,由于C1订阅了t1,因而可以分配成功;
- 尝试将t1-1分配给C2,由于C2订阅了t1,因而可以分配成功;
- 尝试将t2-0分配给C0,由于C0没有订阅t2,因而会轮询下一个consumer;
- 尝试将t2-0分配给C1,由于C1没有订阅t2,因而会轮询下一个consumer;
- 尝试将t2-0分配给C2,由于C2订阅了t2,因而可以分配成功;
- 同理由于t2-1和t2-2所在的topic都没有被C0和C1所订阅,因而都不会分配成功,最终都会分配给C2。
- 按照上述的步骤将所有的分区都分配完毕之后,最终分区的订阅情况如下:
 从上面的步骤分析可以看出,轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将partition分配给各个consumer,如果当前的consumer没有订阅当前的partition,那么就会轮询下一个consumer,直至最终将所有的分区都分配完毕。但是从上面的分配结果可以看出,轮询的方式会导致每个consumer所承载的分区数量不一致,从而导致各个consumer压力不均一。
从上面的步骤分析可以看出,轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将partition分配给各个consumer,如果当前的consumer没有订阅当前的partition,那么就会轮询下一个consumer,直至最终将所有的分区都分配完毕。但是从上面的分配结果可以看出,轮询的方式会导致每个consumer所承载的分区数量不一致,从而导致各个consumer压力不均一。
2)Range
所谓的Range重分配策略,就是首先会计算各个consumer将会承载的分区数量,然后将指定数量的分区分配给该consumer。这里我们假设有两个consumer:C0和C1,两个topic:t0和t1,这两个topic分别都有三个分区,那么总共的分区有六个:t0-0、t0-1、t0-2、t1-0、t1-1和t1-2。那么Range分配策略将会按照如下步骤进行分区的分配:- 需要注意的是,Range策略是按照topic依次进行分配的,比如我们以t0进行讲解,其首先会获取t0的所有分区:t0-0、t0-1和t0-2,以及所有订阅了该topic的consumer:C0和C1,并且会将这些分区和consumer按照字典序进行排序;
- 然后按照平均分配的方式计算每个consumer会得到多少个分区,如果没有除尽,则会将多出来的分区依次计算到前面几个consumer。比如这里是三个分区和两个consumer,那么每个consumer至少会得到1个分区,而3除以2后还余1,那么就会将多余的部分依次算到前面几个consumer,也就是这里的1会分配给第一个consumer,总结来说,那么C0将会从第0个分区开始,分配2个分区,而C1将会从第2个分区开始,分配1个分区;
- 同理,按照上面的步骤依次进行后面的topic的分配。
- 最终上面六个分区的分配情况如下:
 可以看到,如果按照
可以看到,如果按照Range分区方式进行分配,其本质上是依次遍历每个topic,然后将这些topic的分区按照其所订阅的consumer数量进行平均的范围分配。这种方式从计算原理上就会导致排序在前面的consumer分配到更多的分区,从而导致各个consumer的压力不均衡。TODO:我的问题:topic分多个partition,有些custom根据上述策略,分到topic的部分partition,难道不是要全部partition吗?是不是还要按照相同策略多分配多一次?3.3.3 消费者offset的存储
由于 consumer 在消费过程中可能会出现断电宕机等故障, consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
主题+主题分区+消费者组决定offset的量
3.3.3.1 在zookeeper里:
创建top,进入生产者和消费者



消费一条数据,应该有一个分区有变化,验证:


当前有一个消费者组(ID没有指定就分配一个号)
进入第二个消费者,再验证

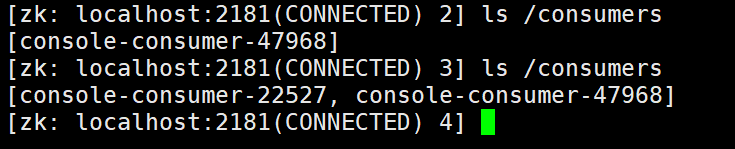
多了一个消费者组
查看消费者offset

由于当前消费了一个(hello)
所以在0分区上 是1 , 1分区是0 (因为hello在0分区上,1分区还没有数据)
再消费一次,再验证
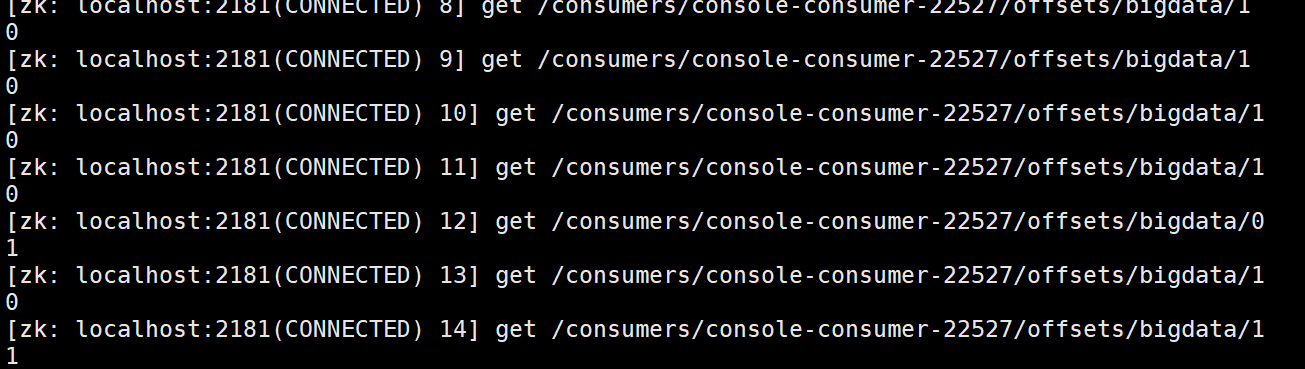
客户端重试几遍,按照轮询到了1分区,已经发生变化
继续测试消费

验证成功轮询到了0分区
3.3.3.2 在本地里:
但是系统topic默认不允许控制台消费者查看,为了测试,需要修改配置
1)修改配置文件
consumer.properties,exclude.internal.topics=false
vi consumer.properties

2)读取 offset
0.11.0.0 之前版本 - bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
0.11.0.0 及之后版本 - bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning



可以正常消费到
进入系统topic 并从头消费
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper yyq10:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning

[消费者组][topic 分区(GTP)][offset]
当前有消费者一直在提交
进行消费,然后查看offset值

消费了一条数据分区0 offset +1
消费3条数据

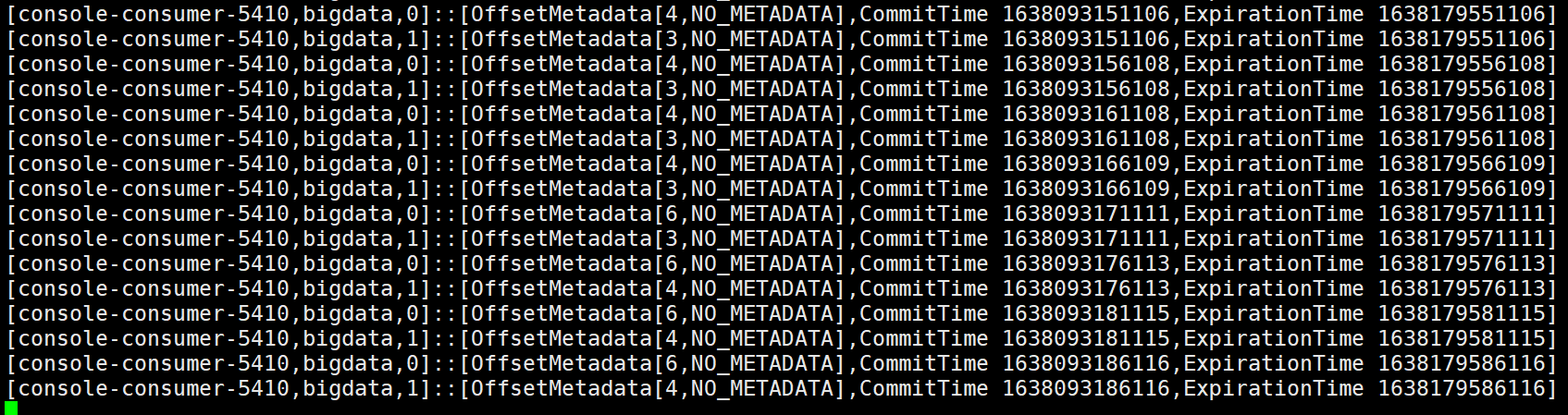
之前的0分区4, 1分区3变成了0分区6,1分区4
消费3条

6、4变7、6
消费多次
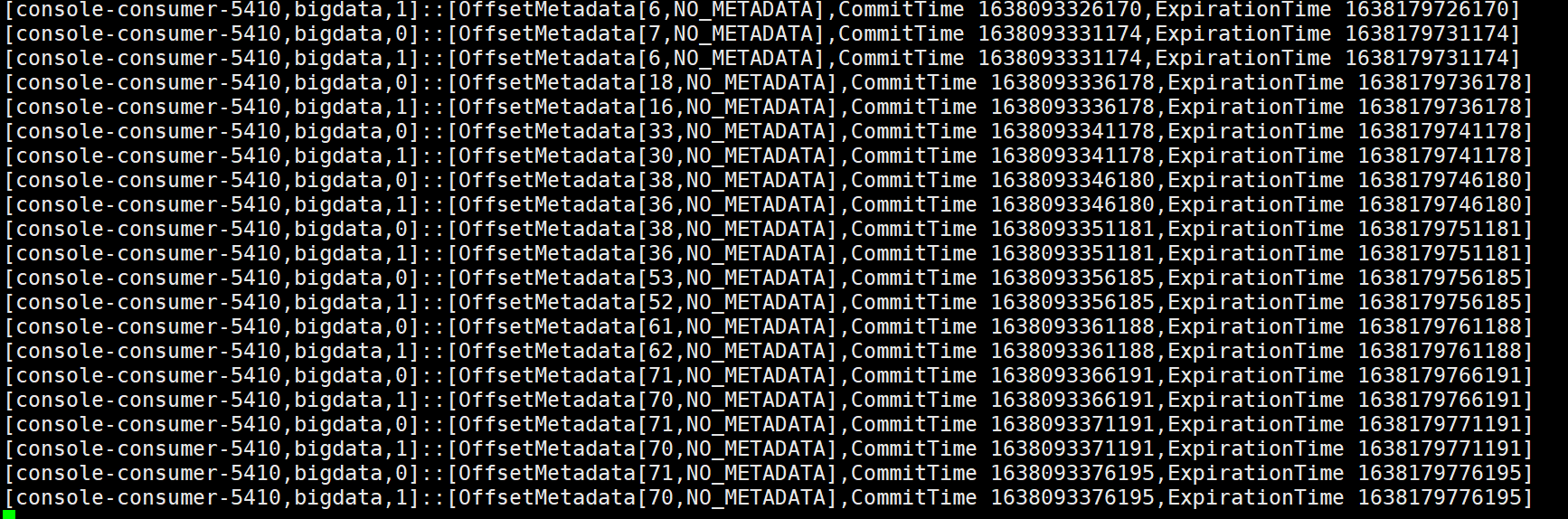
71、70
验证完成,KV(key value)模式,消费者组、主题、分区都不变,保留的offset也不会变,保留在哪个分区根据hash计算。
然后退出消费者,消费者就不会再往里面写东西,也就不会刷新了。
总结:生产者>消费者>写入offset
生产者(产生数据并且放入到对应的topic、partition)>消费者(产生了ID)>往系统写入offset(产生了offset),消费者组ID(以消费者组产生offset,所以不影响其他消费者组和他产生的offset) ,此时对于topic、partition,原本的消费者(本次的消费者组)变成了生产者(生产了消费者组ID和offset)。
如果退出消费者,无法再次进入(group组名已经消费过了,请使用命令删除 --delete-consumer-offsets to delete previous offsets metadata,这里使用的办法是修改组名)

修改消费者配置文件组名
vi config/consumer.properties


3.3.4 消费者组案例
1)需求
测试同一个消费者组中的消费者, 同一时刻只能有一个消费者消费。2)案例操作 (生产者保持2分区)
1.修改config\consumer.properties文件中的group.id属性。vi config/consumer.properties
group.id=yyq
2.打开两个cmd,分别启动两个消费者。(以%KAFKA_HOME\config\consumer.properties%作配置参数)
bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic bigdata --consumer.config config/consumer.properties
3.打开zookeeper

不再是分配的ID了,而是配置文件中制定的消费者组

第一个消费者收到

打开第二个消费者

生产者多次消费
第一个消费者和第二个消费者轮训获取到
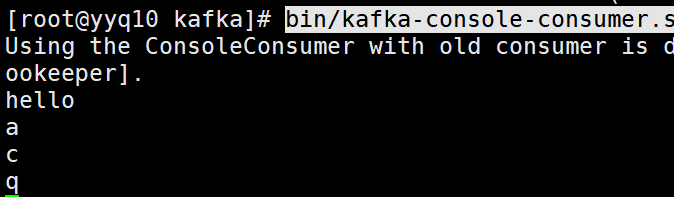
开启第三个消费者

3个消费者窗口提示
bigdata主题(kafka.consumer.RangeAssignor)的使用者线程yyq_yyq10-1638096617113-89de0278-0未使用任何代理分区
当前的消费者:

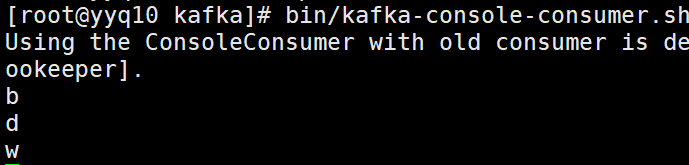
进行多次消费
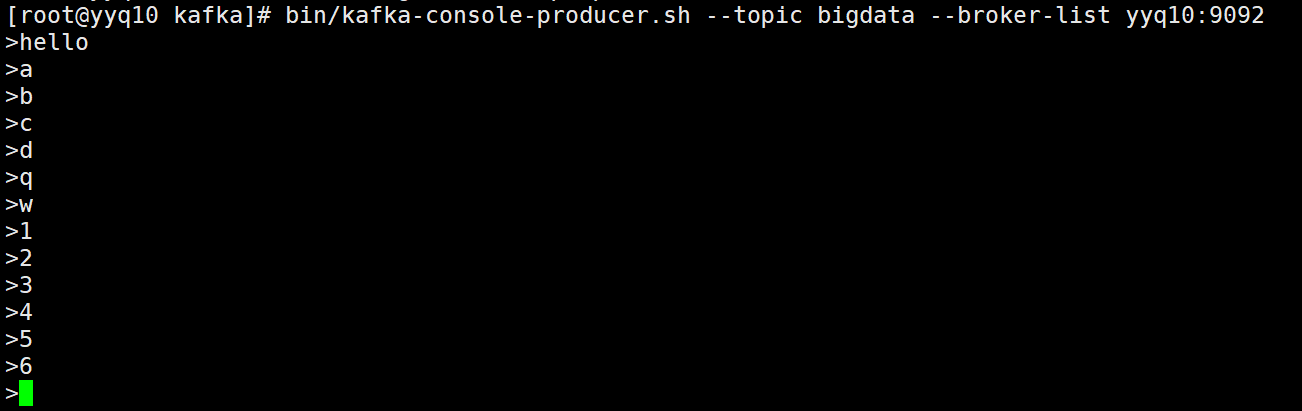
发现还是只有消费者1、2可以收到
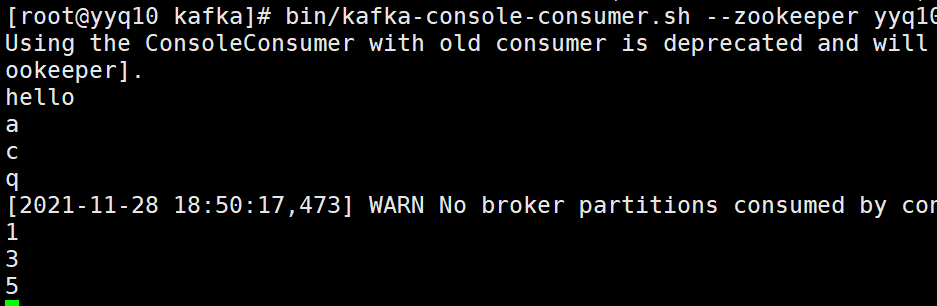
退出第三个消费者,再次进入


新产生的消费者分组还是没有分配到分区,多次尝试还无法分配
经验证:
多台机器连接yyq10,优先满足yyq10本机自己的消费者连接,T出非yyq10主机的消费者
进入生产者和消费者:
[root@yyq10 kafka]# bin/kafka-console-producer.sh --topic bigdata --broker-list yyq10:9092

[root@yyq10 kafka]# bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic bigdata --consumer.config config/consumer.properties

[root@yyq20 kafka]# bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic bigdata --consumer.config config/consumer.properties

查看zookeeper消费者组ids

消费、查看



加入第三个消费者
[root@yyq10 kafka]# bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic bigdata --consumer.config config/consumer.properties

提示已经存在的yyq_yyq20-1638109080439-7a41f3c0-0 被T出去了

消费


验证成功
3.4 高效读写数据
1)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。 官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。2)零复制技术

- NIC network interface controller 网络接口控制器
3.5 Zookeeper 在 Kafka 中的作用
Kafka 集群中有一个 broker 会被选举为 Controller,负责管理集群 broker 的上下线,所有 topic 的分区副本分配和 leader 选举等工作。ReferenceController 的管理工作都是依赖于 Zookeeper 的。以下为 partition 的 leader 选举过程:

Kafka高级_Ranger分区再分析
略3.6 Kafka事务
3.6.1 Producer 事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer 获得的PID 和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的 TransactionID 获得原来的 PID。为了管理 Transaction, Kafka 引入了一个新的组件 Transaction Coordinator。 Producer 就是通过和 Transaction Coordinator 交互获得 Transaction ID 对应的任务状态。 Transaction Coordinator 还负责将事务所有写入 Kafka 的一个内部 Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。3.6.2 Consumer 事务
上述事务机制主要是从 Producer 方面考虑,对于 Consumer 而言,事务的保证就会相对较弱,尤其时无法保证 Commit 的信息被精确消费。这是由于 Consumer 可以通过 offset 访问任意信息,而且不同的 Segment File 生命周期不同,同一事务的消息可能会出现重启后被删除的情况。第四章 Kafka API
略
第五章 Kafka监控
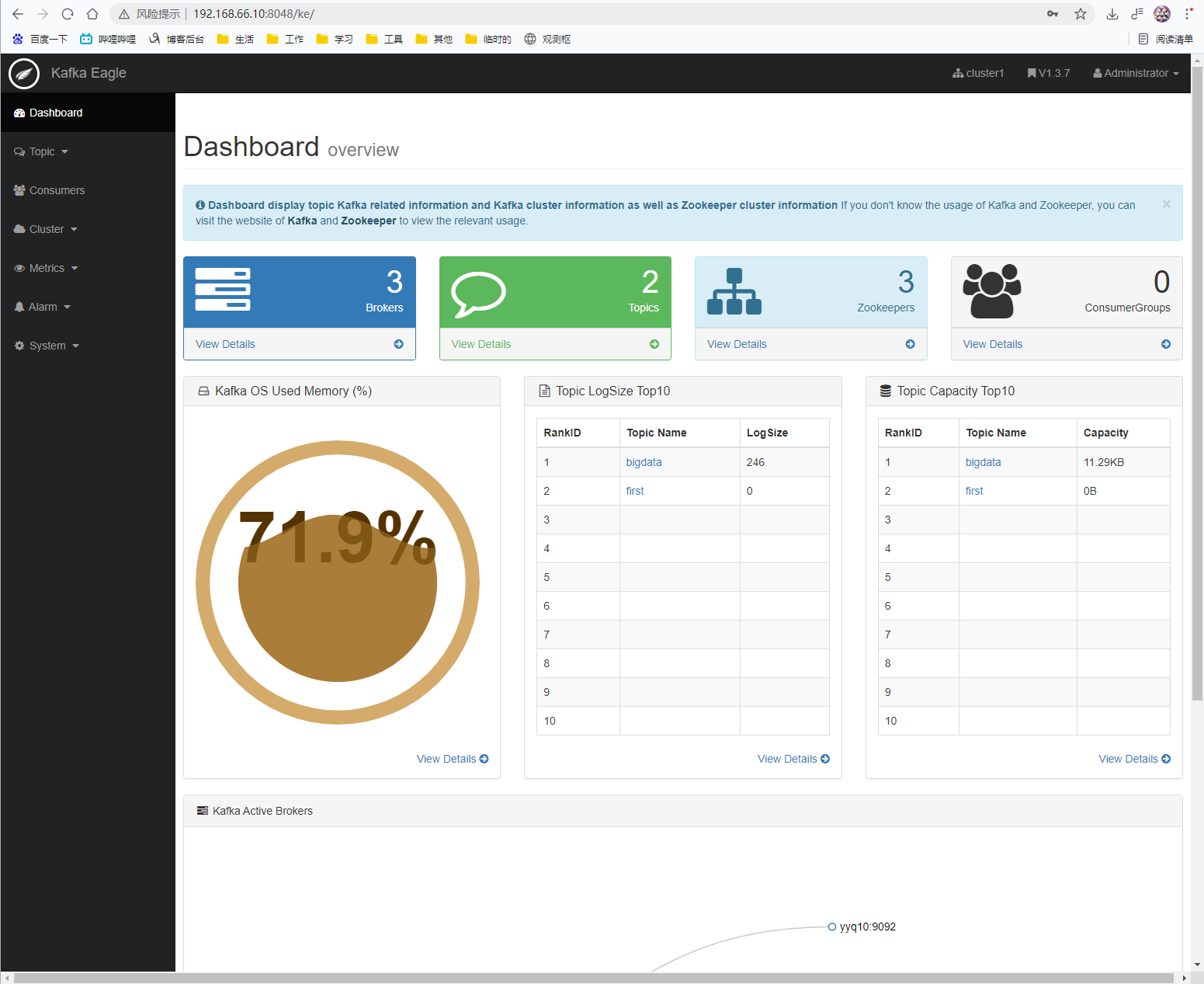
5.1.Kafka Eagle
Kafka Eagle是开源可视化和管理软件。它允许您查询、可视化、提醒和探索您的指标,无论它们存储在哪里。简单地说,它为您提供了将kafka集群数据转换为漂亮的图形和可视化的工具。
修改 kafka 启动命令
kafka启动命令的配置需要在所有节点修改,并且重启kafka
修改 kafka-server-start.sh 命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
改为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -
XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
vi bin/kafka-server-start.sh


改为 
集群所有节点都调整后重启kafka
后续安装无需在所有节点上操作,根据需求来。
添加变量
vi /etc/profile
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
source /etc/profile
解包并授权
把包kafka-eagle-bin-1.3.7.tar.gz 放到 yyq10:/
tar zxvf /kafka-eagle-bin-1.3.7.tar.gz
tar zxvf /kafka-eagle-bin-1.3.7/kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
mv /opt/module/kafka-eagle-web-1.3.7 /opt/module/eagle
chmod /opt/module/eagle/bin//eagle/bin/777 ke.sh
修改配置文件
[root@yyq10 eagle]# cat /opt/module/eagle/conf/system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=yyq10:2181,yyq20:2181,yyq21:2181
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=25
######################################
# kafka eagle webui port
######################################
kafka.eagle.webui.port=8048
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka sql topic records max
######################################
kafka.eagle.sql.topic.records.max=5000
######################################
# alarm email configure
######################################
kafka.eagle.mail.enable=false
kafka.eagle.mail.sa=alert_sa@163.com
kafka.eagle.mail.username=alert_sa@163.com
kafka.eagle.mail.password=mqslimczkdqabbbh
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25
######################################
# alarm im configure
######################################
#kafka.eagle.im.dingding.enable=true
#kafka.eagle.im.dingding.url=https://oapi.dingtalk.com/robot/send?access_token=
#kafka.eagle.im.wechat.enable=true
#kafka.eagle.im.wechat.token=https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=xxx&corpsecret=xxx
#kafka.eagle.im.wechat.url=https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=
#kafka.eagle.im.wechat.touser=
#kafka.eagle.im.wechat.toparty=
#kafka.eagle.im.wechat.totag=
#kafka.eagle.im.wechat.agentid=
######################################
# delete kafka topic token
######################################
kafka.eagle.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
cluster1.kafka.eagle.sasl.enable=false
cluster1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster1.kafka.eagle.sasl.mechanism=PLAIN
cluster1.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="kafka-eagle";
cluster2.kafka.eagle.sasl.enable=false
cluster2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster2.kafka.eagle.sasl.mechanism=PLAIN
cluster2.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="kafka-eagle";
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://yyq10:3306/ke?useUnicode=true&ch
aracterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=password
安装mysql
yum install mariadb-server
service mysql start
mysql_secure_installation
设置密码
mysql -u root -p
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'youpassword' WITH GRANT OPTION
LUSH PRIVILEGES;
安装eagle
cd chmod /opt/module/eagle/
bin/ke.sh start
登录页面查看监控数据
http://192.168.66.10:8048/ke/
第 6 章 Flume 对接 Kafka
下载 flume
wget https://downloads.apache.org/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz /opt/module
tar zxvf /opt/module/apache-flume-1.7.0-bin.tar.gz
mv /opt/module/apache-flume-1.7.0-bin /opt/module/flume
配置 flume
mkdir /opt/module/flume/job
[root@yyq10 job]# cat kafka.conf
# Name
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.command = tail -F -c +0 /opt/module/data/flume.log
a1.sources.r1.shell = /bin/bash -c
# Sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = yyq10:9092,yyq20:9092,yyq21:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 flume
bin/flume-ng agent -c conf/ -f job/kafka.conf -n a1

进入消费者
bin/kafka-console-consumer.sh --zookeeper yyq10:2181 --topic first

连接端口生产

消费消息

视频地址:
https://www.bilibili.com/video/BV1a4411B7V9?p=1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号