Rolling in the Deep (Learning)
Rolling in the Deep (Learning)
Deep Learning has been getting a lot of press lately, and is one of the hottest the buzz terms in Tech these days. Just check out one of the few recent headlines from Forbes, MIT Tech Review and you will surely see these words pop up at least once.
But what is this strange concept everybody is talking about ?
Is it just a fleeting craze, that everybody will forget in a few years (or maybe months) ?
What is all the hype about ?
We will try to answer these questions, and a few more, in the following post.
Beyond the buzz — What is Deep Learning ?
Let us first give a quick definition of Deep Learning:
- It’s (just) a Machine Learning technique
- It’s about learning features and representations
- It’s based on Artificial Neural Networks
Some of these terms may be unfamiliar to you. The aim is to give an overview of every one of these concepts, so that by the end you will have a pretty clear picture of what it is all about.
Machine Learning — Quick Refresher
Machine Learning (yet another buzz term) boils down to learning a mapping from an input space to an output space in an automated manner, using available data.
In the case of what we call supervised learning, the output space is a response that we are trying to predict by using examples of this mapping as training.
Example: Learning whether a person is likely or not to default on their loan
- Input space: Attributes of a person (age, income, …)
- Output space: Whether they are likely to default or not (1 or 0)
- Data: Historical data of people who took a loan, and whether they defaulted or not
In the case of what we call unsupervised learning, the output space is often a simpler representation of the input space, that is more structured, we are not given explicit examples of this mapping, so we need to learn it by exploiting the internal structure in the input data.
Example: Clustering customers by their purchase habits
- Input space: How much each customer spent in each product category
- Output space: The segment that each customer belongs to
- Data: Customer purchase data
These examples seem simple to understand and reason about, and the representation of the input space is rather natural.
But a lot of other tasks fall in the Machine Learning framework, and some are quite complicated.
- Automatic recognition of objects, by classifying images into one or more predefined categories.
- Converting spoken words and sentences into text.
- Assigning a sentiment to a sentence, or classifying text data
In these examples, finding a suitable representation of the input data is more complicated.
The process of Machine Learning
We can divide the Machine Learning process into, essentially, two steps:
- Engineering/Building/Learning the features and representations of our inputs
- Using these representations to get a useful output (predicting a quantity, finding most similar neighbors …)
The first step is usually the most time consuming, and the most task specific, that’s where Deep Learning comes in.
Before we elaborate on this, let us first introduce the family of models on which most Deep Learning techniques are based: Artificial Neural Network.
Artificial Neural Network
(The images in this section were taken from Christopher Olah’s excellent blog post http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/)
In its most basic form, an artificial neuron is a simple computational unit that outputs a weighted sum of its inputs.
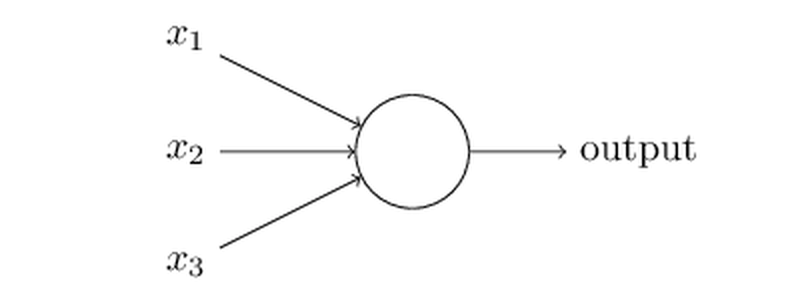
An artificial neuron
It is somewhat inspired by its biological cousin (the “real” neuron), but it doesn’t replicate at all its inner workings.
Data in the form of (input, output) couples is used to adjust the weights of this neuron, to make the output as close as possible to the expected output. Let’s illustrate this on a toy example:
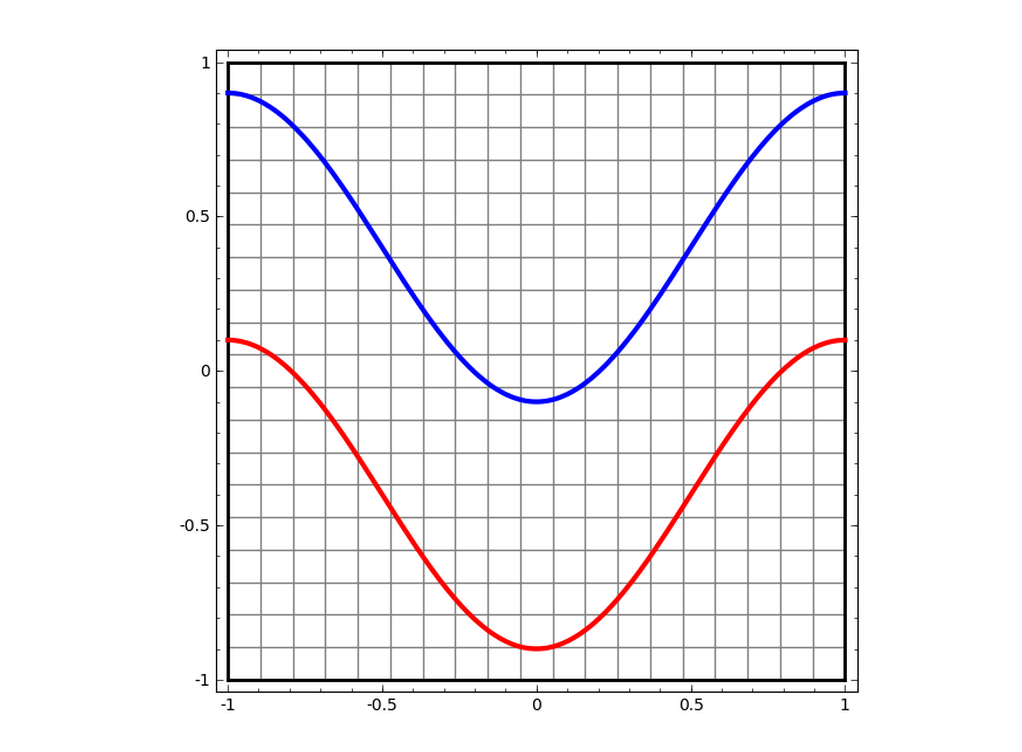
We are trying to separate the blue and red curves
Let’s say we wanted to classify a point in this 2D space, as being part of the red curve, or blue curve. If we use our simple neuron to solve this problem, the task comes down to finding the best separating line between the two curves.
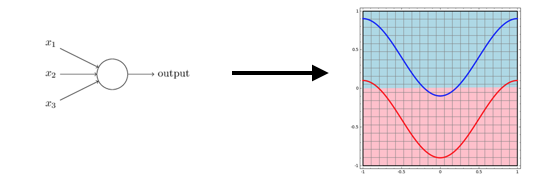
A simple neuron gives us a linear separation
Not bad. The separating line does a pretty good job, but we can clearly see that a line will never separate the two curves perfectly, the problem is just a bit too complex. What if we add an extra layer to our simple network ? i.e.
- We first compute several weighted sums of our inputs
- Then we use these weighted sums as an input to a simple neuron
Let’s try this and see what happens:

A neural network with a hidden layer can separate the curves perfectly
Better ! We can now separate our two curves perfectly. What is happening in the extra layer, that made this possible ?

How neural networks work
No .. Not really … We are just bending and twisting our space, so that we can better separate our two curves. If we sneak a peak into what’s happening, to see how the input space is transformed, we can see that our extra layer computes a new representation, that makes the two curves linearly separable:
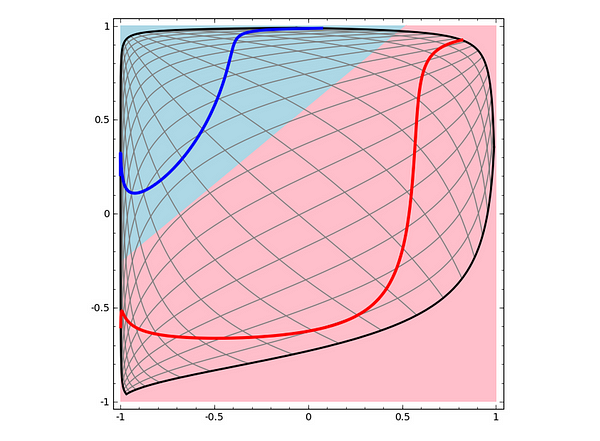
Computed representation of input space
This is one of the things Deep Learning is all about.
To better show how learning multiple levels of new, more useful representations looks like, we will make the (huge) jump to the world of human face detection. If we train a Deep Learning model on a dataset of face images, we can see that we naturally have a hierarchy of representations that is learned (object edges -> parts of faces -> whole faces )
(Image Source: http://www.nature.com/news/computer-science-the-learning-machines-1.14481)

Multiple layers of features for face detection
How Deep is your learning ?
Ok, so that’s how a neural network works (basically).
We can argue that if we make our neural networks deeper, by adding more layers (that’s where the Deep is Deep Learning comes from), we can learn more and more complex representations of our input, and we can potentially capture more complicated structures (as in images or text data).
Wait … That’s what took everybody several decades to figure out ?
Well not exactly. These ideas were here a while ago, but (until 2006) people just couldn’t properly train these Deep Networks.
(If you want to know more about the history of Deep Learninghttp://www.wired.com/2014/01/geoffrey-hinton-deep-learning)
This Deep Learning renaissance is due to a mix of three things:
- New techniques for training these complex models (new optimization methods, better initializations …)
- More computational power (GPUs are now used to dramatically speed up the training)
- More data ! (The internet)
The reason everyone (or almost everyone) is so excited about Deep Learning, is that it achieved really promising results on a variety of tasks and in a relatively short period of time.
Deep Learning — Cool stuff
Computer Vision — Recognizing Objects:
Deep Learning models are now the state-of-the-art methods on this task.
If we take for instance the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which is a annual competition where the task is classifying several tens of thousands of images into one of 1000 different object categories, this competition was dominated by Deep Learning Models in the last few years.
Check out http://www.image-net.org/challenges/LSVRC/ for more info.

Some examples of predicted image labels
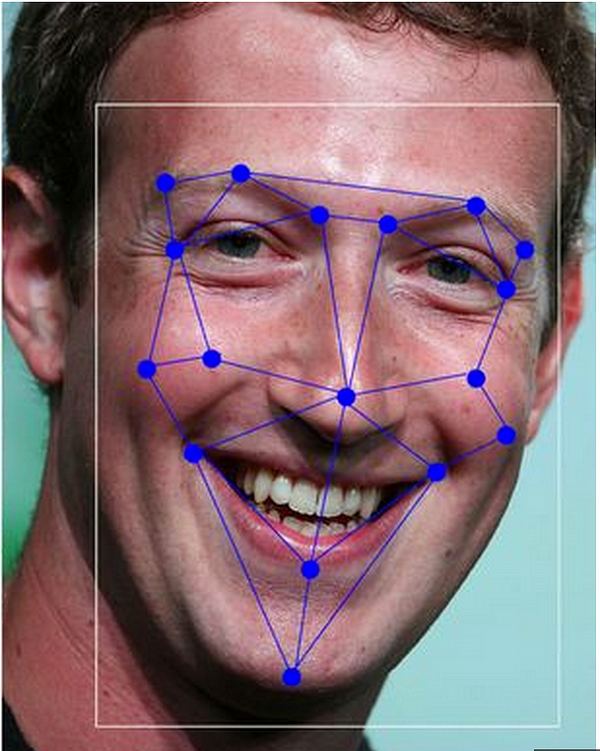
Computer Vision — Facebook’s DeepFace
Facebook’s DeepFace model is closely approaching human level performance on the task of recognizing faces (the dataset used ishttp://vis-www.cs.umass.edu/lfw/ ), achieving an accuracy 97.25%.
News article http://www.mirror.co.uk/news/technology-science/technology/facebooks-deepface-ai-system-scarily-5137505)
Computer Vision + Natural Language Processing — Generating image captions
Another really cool application. This model generates image captions automatically by learning correspondences between language and visual data.
Check out the results here:http://cs.stanford.edu/people/karpathy/deepimagesent/

Some examples of generated caption
Speech Recognition — Google Voice
Today, each time you speak to your android phone, so you can send a text message, call someone, or do a google a search, there is a large Deep Learning model that is processing your voice and translating it into text.
The use of Deep Learning models helped reduce the error rate of this system dramatically.
Natural Language Processing — Neural Machine Translation
Something that’s been showing some promise in recent years, is the use of Deep Learning to better understand the human language.
Neural Machine Translation is an interesting application of such models, where using just an aligned corpus on the sentence level (like the Euro Parliament corpus (http://www.statmt.org/europarl/ ), we can learn to translate new sentences, and even align words and groups of words across languages.
Here’s a link to the demo: http://104.131.78.120/
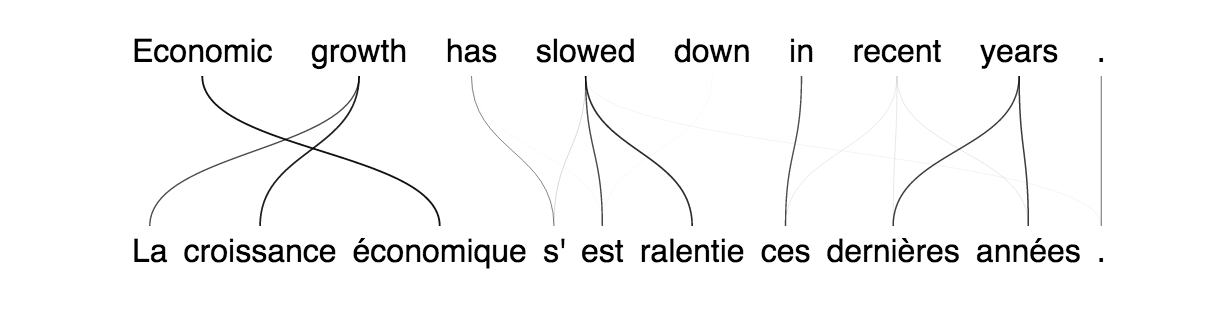
An example of generated translation with alignement
And more:
There’s a lot more applications, and it’s hard to give an exhaustive view of every one of them.
- Reinforcement Learning or how a machine can learn to play a gamehttp://www.wired.co.uk/news/archive/2015-02/25/google-deepmind-atari
- Deep Learning of artistic stylehttp://www.boredpanda.com/computer-deep-learning-algorithm-painting-masters/
- Medicine http://blog.kaggle.com/2012/10/31/merck-competition-results-deep-nn-and-gpus-come-out-to-play/
- …

Deep Leaning is impressive
Ok, so all of this seems great, the results are promising, the models are powerful. But there must be some flaw in these models ? They are certainly not perfect in every way ? Are they ?
Well, the answer is no, they are not perfect, and they do have some flaws, which brings us to our next section.
Deep Learning — The Good, the bad and the ugly

The good:
We argued earlier, that Deep Learning models have a lot of advantages:
- They work quite well for a variety of tasks
- Less time is spent on engineering features and representations
- Some variants make good use of the mass of unlabelled data
Which make them the tool of choice for a lot of modern problems.
The bad:
But there are some downsides to using these models
- They are far from being a silver bullet: they are not well suited for every task, and they will not replace other Machine Learning models anytime soon.
- Relatively hard to tune (a lot of fiddling around): There’s a lot of engineering involved in tuning every parameter of the network (depth, architecture, …), and it is more of an art than a science.
- They require a lot of data to work properly, which in certain tasks is not a problem, but for other tasks where data is scarce, it is kind of hard to get them to work.
Resolving all of these problems is still an active area of research, and people are trying to make implementing and tuning these models easier. Some people will even argue that these flaws are inherent to a lot of Machine Learning methods and not only Deep Learning.
There are also some flaws which are even more severe, and have more profound consequences.
The ugly:
Your model is as good as your data
Deep Learning models learn representations that capture the structure of the data. So if we want to learn useful features, we need to make sure our data is large and diverse enough to represent the real world.
One particular example comes to mind. (http://googleresearch.blogspot.fr/2015/06/inceptionism-going-deeper-into-neural.html)
If we ask a Deep Learning model trained on a computer vision task to generate what it thinks most resembles a dumbbell, here’s what we obtain:

This is what a Dumbbell is for a Deep NN
The network thinks a dumbbell always has an arm attached to it, because it was the case in most of the training examples it saw. The model is still far from being “intelligent”, it failed to completely distill the essence of a dumbbell.
Deep networks can be (easily ?) fooled
Some researchers found that Deep Learning models are quite easily fooled by noise in the input data.
They took an image of an object that was recognizable by the network and added just a little bit of noise, so little that it was basically identical to the human eye. The network completely mislabelled these examples.

Perturbed panda is a gibbon
The reverse was also done, taking images that were, to the human eye, just random pixels on a canvas, yet the network labelled them as objects with near certainty.
Some examples of this:

I can’t see the resemblance
It makes us question whether these networks are really robust, and understand the essence of what an object is.
More details and examples of this can be found here
http://www.kdnuggets.com/2014/06/deep-learning-deep-flaws.htmland here http://www.kdnuggets.com/2015/01/deep-learning-can-be-easily-fooled.html
What’s in the box ?

Brad Pitt on the inner workings of Deep Learning models
You probably noticed that most of these examples are related to Computer Vision, not because it’s the only application domain or the most important (which is not), but because we can “see” what is happening under the hood, and that’s not the case with every task.
This is a problem with these kinds of model, they are more like black boxes, and it’s kind of hard to see what’s exactly happening inside. Sure, it’s ok if all we care about is accuracy and performance, but that’s rarely the case, sometimes we do need to open the box.
The point is …
We tried to give a brief overview of Deep Learning, so you can see and understand what is happening beyond the hype.
Three key points to remember are:
- Deep Learning is about learning features and representations
- It is overhyped, but it works well for a lot of stuff
- Vision, Speech, and a bit of NLP are the main applications right now (but there is some promise in other areas)
Amine — @amine_benh
You should follow us on Twitter: @mfg_labs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号