Machine Learning Trick of the Day (2): Gaussian Integral Trick
Machine Learning Trick of the Day (2): Gaussian Integral Trick
Today's trick, the Gaussian integral trick, is one that allows us to re-express a (potentially troublesome) function in an alternative form, in particular, as an integral of a Gaussian against another function — integrals against a Gaussian turn out not to be too troublesome and can provide many statistical and computational benefits. One popular setting where we can exploit such an alternative representation is for inference in discrete undirected graphical models (think Boltzmann machines or discrete Markov random fields). In such cases, this trick lets us transform our discrete problem into one that has an underlying continuous (Gaussian) representation, which we can then solve using our other machine learning tricks. But this is part of a more general strategy that is used throughout machine learning, whether in Bayesian posterior analysis, deep learning or kernel machines. This trick has many facets, and this post explores the Gaussian integral trick and its more general form, auxiliary variable augmentation.
Gaussian integral trick state expansion.
Gaussian Integral Trick
The Gaussian integral trick is one of the statistical flavour and allows us to turn a function that is an exponential in x2 into an exponential that is linear in x. We do this by augmenting a linear function with auxiliary variables and then integrating over these auxiliary variables, hence a form of auxiliary variable augmentation. The simplest form of this trick is to apply the following identity:
We can prove this to ourselves by exploiting our knowledge of Gaussian distributions (which this looks strikingly similar to) and our ability to complete the square when we see such quadratic forms. Separating out the scaling factor a we get:
Which by completing the square becomes:
where the last integral is solved by matching it to a Gaussian with mean μ=x2a and variance σ2=12a, which we know has a normalisation of 2πσ2−−−−√ — this last step shows how this trick got its name.
The 'Gaussian integral trick' was coined and initially described by Hertz et al. [Ch10, pg 253] [1], and is closely related to the Hubbard-Stratonovich transform (which provides the augmentation for exp(−x2)).
Transforming Binary MRFs
This trick is also valid in the multivariate case, which is what we will most often be interested in. One good place to see this trick in action is when applied to binary MRFs or Boltzmann machines. Binary MRFs have a joint probability, for binary random variables x:
where Z, is the normalising constant. The (multivariate) Gaussian integral trick can be applied to the quadratic term in this energy function allowing for an insightful analysis andinteresting reparameterisation that allows for alternative inference methods to be used. For example:
- We can conduct an analysis of Boltzmann machines that when combined with our earlier trick, (trick 1) the replica trick, allows for theoretical predictions about the performance of this model. See:
- Formal statistical Mechanics of neural networks, section 10.1 (eq 10.5), Hertz et al. [1]
- We can use the trick to create a Gaussian augmented space for discrete MRFs to which Hamiltonian Monte Carlo, previously restricted to continuous and differentiable models, can be applied [2][3]. See:
- Continuous Relaxations for Discrete Hamiltonian Monte Carlo, Zhang et al.
- Auxiliary-variable Exact Hamiltonian Monte Carlo Samplers for Binary Distributions. Pakman and Paninski.
Variable Augmentation
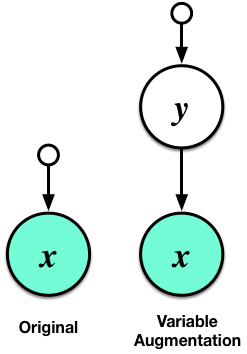
Graphical model for a general augmentation.
This trick is a special case of a more general strategy called variable (or data) augmentation — I prefervariable augmentation to data augmentation [4], since it will not be confused with observed data preprocessing and manipulation. In this setting, the introduction of auxiliary variables has been most often used to develop better mixing Markov chain Monte Carlo samplers. This is because after augmentation, the conditional distributions of the model often have highly convenient and easy-to-sample-from forms.
One recent example of variable augmentation (and that parallels our initial trick) is the Polya-Gamma variable augmentation. In this case, we can express the sigmoid function that appears when computing the mean of the Bernoulli distribution, as:
where p(y) has a Polya-Gamma distribution [5]. This nicely transforms the sigmoid into a Gaussian convolution (integrated against a Polya-Gamma random variable) — and gives us a different type of Gaussian integral trick. In fact, similar Gaussian integral tricks are abound, and are typically described under the heading of Gaussian scale-mixture distributions.
There are many examples of variable augmentation to be found, especially for binary and categorical distributions. Much guidance is available, and some papers that demonstrate this are:
- Albert and Chib's paper is one of the first where the concept of data augmentation is most clearly established, and to whom data augmentation is most often attributed. It shows augmentation for binary and categorical variables — a classic paper that everyone should read.
- Polson and Scott introduced the Polya-Gamma augmentation I described above, and is amongst the more recent of augmentation strategies. This augmentation can be used for more effective Monte Carlo or variational inference, e.g.,
- Ultimately, finding a good augmentation relies on exploiting known and tractable integrals. As such there can be a bit of an art to creating such augmentations and is what Van Dyk and Meng discuss.
Summary
The Gaussian integral trick is just one from a large class of variable augmentation strategies that are widely used in statistics and machine learning. They work by introducing auxiliary variables into our problems that induce an alternative representation, and that then give us additional statistical and computational benefits. Such methods lie at the heart of efficient inference algorithms, whether these be Monte Carlo or deterministic approximate inference schemes, making variable augmentation a favourite in our box of machine learning tricks.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号