神经网络简史(上)——从“极高的期待”到“极度的怀疑”
神经网络简史(上)——从“极高的期待”到“极度的怀疑”
神经网络的发展,迄今经历了三个周期,包括三次高潮和两次低谷。
- 第一个周期(1943—1986),感知器时代。
从1943年McCulloch-Pitts(MP)模型作为开端、1957年感知器的提出为标志性高潮起点,到1969年Minsky的《感知器》一书提出批判进入低谷,酝酿期14年,高潮期12年,之后低谷期17年。
- 第二个周期(1986—2012),BP算法时代。
以1986年误差反向传播(BP)算法为标志性高潮起点,并没有明确进入低谷的标志性事件,一般认为在1995年前后进入低谷。高潮期是9年,之后低谷期也是17年——真是一种历史的巧合。
- 第三个周期(2012年至今),深度学习时代。
以2012年深度学习在ImageNet竞赛大获全胜为标志性高潮起点,到现在还在高潮期中,尚未进入低谷。
(以上的周期年份,主要是对于美国的学术界而言,而在中国,以前会滞后几年,不过在最近一个周期里,中美两国已经基本同步发展了。)
神经网络的发展史上,反复出现“极高的期待”—“极度的怀疑”这种震荡。
在1991年(第二个高潮的巅峰)《终结者2》电影中,施瓦辛格扮演的“终结者”机器人也说:“我的CPU是一个神经网络处理器,一个会学习的计算机。”(My CPU is a neural-net processor...a learning computer.)那时候没人能想到,仅仅4年之后这个领域就凉了,神经网络遇到了自己的“终结者”。

《终结者2:审判日》电影海报
第一代终结者:异或问题
1969年,人工智能之父 Minsky(和Seymour Papert)在《感知器》(Perceptrons)一书里给感知器判了“死刑”。Minsky的逻辑是:
(1)一层感知器只能解决线性问题;
(2)要解决非线性问题(包括分段线性问题),比如异或(XOR)问题,我们需要多层感知器(MLP);
(3)但是,我们没有MLP可用的训练算法。
(4)所以,神经网络是不够实用的。

1969年,Minsky和Papert发表 Perceptrons ,其狭义科学分析通过广义文学语言的描述封杀了神经网络研究十余年,将人工智能研究推入第二个「冬天」。
这是一本非常严谨的专著,影响力很大。一般的读者未必能理解书中的推理及其前提限制,可能就会得到一个简单的结论:神经网络都是骗人的。
这并不意味着Minsky本人看衰人工智能领域,实际上1967年他说:
“一代人内……创建人工智能的问题就会被事实上解决掉。”

Marvin Lee Minsky(1927年8月9日-2016年1月24日),美国科学家,专长于认知科学与人工智能领域,1969年,因为在人工智能领域的贡献获得图灵奖。图片来源:维基百科,拍摄者:Sethwoodworth
这里可能还有另外一个因素:在那个时候,他是很看好与神经网络竞争的“符号主义”和“行为主义”的方法的,比如框架方法、微世界方法等,他后面也转向心智与主体理论的研究,所以《感知器》这本书观点的形成可能也有路线之间竞争的因素。
但很不幸的是,无论是1967年他对AI过于乐观的展望,还是1969年他(事后看)对连接主义方法过于悲观的判断,都对1973年AI进入全面的冬天起到了推波助澜的作用。这是“极高的期待导致极度的怀疑”的第一次案例——当然并不是最后一次。
说1969年《感知器》的观点事后看过于悲观,是因为在Minsky写这本书的时候,问题的答案——误差反向传播(BP)算法——其实已经出现了,虽然直到1974年Paul Werbos在博士论文中才把它引入了神经网络。只是要再等十几年,这个算法才被几个小组再次独立发现并广为人知。
无独有偶,1995年前后神经网络再次进入低谷的时候,后来深度学习的那些雏形在20世纪80年代末其实已经出现了,也同样需要再花二十年才能被主流认知。
不管是不是合理,神经网络与它的其他AI难兄难弟一起,进入了一个漫长的冬天。当时研究经费的主要来源是政府,但这之后十几年几乎没有政府资助再投入神经网络。20世纪70年代到80年代初,AI退守的阵地主要是“符号主义”的专家系统。
第二周期的复兴:BP算法
1986年,David Rumelhart、Geoffrey Hinton和Ronald Williams发表了著名的文章 Learning representations by back-propagating errors (《通过误差反向传播进行表示学习》),回应了Minsky在1969年发出的挑战。尽管不是唯一得到这个发现的小组(其他人包括Parker,1985;LeCun,1985),但是这篇文章本身得益于其清晰的描述,开启了神经网络新一轮的高潮。
BP算法是基于一种“简单”的思路:不是(如感知器那样)用误差本身去调整权重,而是用误差的导数(梯度)。
如果我们有多层神经元(如非线性划分问题要求的),那只要逐层地做误差的“反向传播”,一层层求导,就可以把误差按权重“分配”到不同的连接上,这也即链式求导。为了能链式求导,神经元的输出要采用可微分的函数,如s形函数(sigmoid)。
在20世纪80年代的时候,一批新的生力军——物理学家也加入了神经网络的研究阵地,如John Hopfield、Hermann Haken等。在计算机科学家已经不怎么搞神经网络的20世纪80年代早期,这些物理学家反而更有热情。
与第一周期中常见的生物学背景的科学家不同,物理学家给这些数学方法带来了新的物理学风格的解释,如“能量”“势函数”“吸引子”“吸引域”等。对于上述链式求导的梯度下降算法,物理学的解释是在一个误差构成的“能量函数”地形图上,我们沿着山坡最陡峭的路线下行,直到达到一个稳定的极小值,也即“收敛”点。
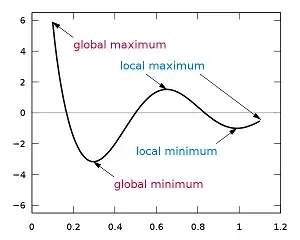
梯度下降法可以找到局部最小值
图片来源:https://commons.wikimedia.org/w/index.php?curid=2276449 ,作者:KSmrq
1989年,George Cybenko证明了“万能近似定理”(universal approximation theorem),从表达力的角度证明了,多层前馈网络可以近似任意函数(此处表述忽略了一些严谨的前提细节)。进一步的理论工作证明了,多层感知器是图灵完备的,即表达力和图灵机等价。这就从根本上消除了Minsky对神经网络表达力的质疑。后续的工作甚至表明,假如允许网络的权重是所谓“不可计算实数”的话,多层前馈网络还可以成为“超图灵机”——虽然这没有现实工程意义,不过足以说明神经网络强大的表达力。
BP算法大获成功,引起了人们对“连接主义”方法的极大兴趣。数以百计的新模型被提出来,比如Hopfield网络、自组织特征映射(SOM)网络、双向联想记忆(BAM)、卷积神经网络、循环神经网络、玻尔兹曼机等。物理学家也带来了很多新方法和新概念,如协同学、模拟退火、随机场、平均场和各种从统计物理学中借鉴过来的概念。其实后来深度学习复兴时代的很多算法,都是在那时候就已经被提出来了。
回看20世纪80年代,你也许会发现今天探索过的很多想法当时都探索过,诸如自动控制、股市预测、癌症诊断、支票识别、蛋白质分类、飞机识别,以及非常多的军事应用等,都有成功的案例——这是20世纪60年代那一波未曾见的。因为有了这些可商业落地的应用,大量风险投资也加入进来,从而摆脱了单纯依靠政府资助发展的模式。
可以说,在那个时代,神经网络已经是“大数据”驱动的了。相比美好的承诺,新一代神经网络速度慢的缺点(这来自于大量的求导计算)也就不算什么了。而且出现了大量用硬件加速的神经网络——正如今天专用于深度学习的“AI芯片”。

Google专为深度学习框架TensorFlow设计的AI芯片专用集成电路(TPU 3.0),拍摄者:Zinskauf
大量的公司去设计并行计算的神经网络,IBM、TI都推出了并行神经计算机,还有ANZA、Odyssey、Delta等神经计算协处理器,基于光计算的光学神经网络,等等。甚至Minsky本人都创办了一家并行计算人工智能公司“Thinking Machines”,产品名也充满暗示地叫“连接机”(蹭“连接主义”的名气)。和今天一样,也几乎每天都有头条,每一天都看起来更加激动人心,眼前的困难都可以被克服。
短短几年之内,极度的怀疑反转为(又一次的)极高的期待,以至于在之前引用的《科学家》1988年文章“神经网络初创企业在美国激增”中也表达了对这种期待的担心:
神经网络在金融领域如此之热,以至于有些科学家担心人们会上当。斯坦福大学教授、有三十年神经网络经验的Bernard Widrow说:“一些商业神经网络公司的信誓旦旦可能会把这个行业带入另一个黑暗时代。”
Widrow也是在Minsky的影响下进入AI领域的,后来加入斯坦福大学任教。他在1960年提出了自适应线性单元(Adaline),一种和感知器类似的单层神经网络,用求导数方法来调整权重,所以说有“三十年神经网络经验”并不为过。不过,当时他认为神经网络乃至整个人工智能领域风险有点高,于是他转向了更稳妥的自适应滤波和自适应模式识别研究。
顺便说一句,自适应滤波的很多方法在数学上和神经网络方法是相通的,甚至只是换了个名字,比如Widrow著名的“最小均方误差”(LMS)方法在后来的神经网络研究中也广为应用。我们在神经网络的起起伏伏中经常看到这样的现象(后面还会举更多的例子):
● 当领域进入低谷,研究人员换了个名字继续进行研究。甚至1986年神经网络复兴的时候,Rumelhart编的那本论文集并没有叫“神经网络”,而是“并行分布式处理”(Parallel Distributed Processing)这个低调的名字。
● 当领域进入高潮,那些潜伏的研究再次回归本宗——当然,很多原本不在其中的方法也会来“搭便车”。例如,支持向量机(SVM)方法虽然在20世纪60年代就有了,在20世纪90年代复兴的时候,采用的名字却是“Support Vector Network”,以神经网络的面貌出现,直到神经网络进入低谷才把“Network”去掉。
回到1986—1995年这段时间,什么都要和神经网络沾边才好发表。比如,那时候CNN不是指卷积神经网络(Convolutional Neural Network),而是细胞神经网络(Cellular Neural Network)——一种并行硬件实现的细胞自动机,尽管这种算法本来和神经网络没有太大关系。顺便提一句,它的发明人是“虎妈”(蔡美儿)的父亲蔡少棠。
第二代终结者:收敛速度与泛化问题
神经网络从“飞龙在天”到“亢龙有悔”,也只花了几年时间,就又遇到了“第二代终结者”。有趣的是,第二代终结者的出现本身又是为了解决第一代终结者问题而导致的。
异或问题本质上是线性不可分问题。为了解决这个问题,在网络里引入非线性,以及将这些非线性函数组合的参数化学习方法(BP算法等)。但是这样复杂的高维非线性模型,在计算上遇到了很多挑战,基本上都是和链式求导的梯度算法相关的。
首先就是“慢”。训练一个规模不算很大的神经网络花上几天时间是很正常的,在中国就更艰苦了。1998年在读研究生时我得到的第一台计算机是一台“486”,在那上面运行MATLAB的神经网络程序,隐藏层节点都不敢超过20个。
为什么这么慢呢?全连接的前馈网络,参数空间维数大幅增加,导致了维度灾难(The Curse of Dimensionality),参数组合的数量呈指数增长,而预测的精度与空间维数的增加反向相关,在20世纪90年代有限的算力支持下,规模稍大的问题就解决不了了。
“万能近似定理”虽然说明了我们可以逼近任意函数,但是并不保证有一个训练算法能够学习到这个函数。虽然后来我们知道,同样的神经元数量,多隐层会比单隐层收敛得更快(虽然单隐层和多隐层在表达力上对于连续函数没区别),但是那时候由于不能解决“梯度消失”的问题(后面还会讲到),很少人会用多隐层。所以,神经网络内在的结构性是不好的。那时候也有很多“打补丁”的方法,比如,通过进化神经网络来寻找最优节点结构,或者自适应步长迭代,等等,但事后看,都是些治标不治本的方法。
维度灾难的另一个后果是泛化问题。比如训练一个手写数字识别器,稍微变化一下图像可能就识别不了了。这个问题的原因是误差求导是在一个高维空间里,目标函数是一个多“峰值”和“谷底”的非线性函数,这就导致了梯度下降迭代终点(“吸引子”)往往不一定是希望找到的结果(全局最优解)。甚至,有些迭代终点根本不是任何目标模式,称为“伪模式”或者“伪状态”。
Hinton在2015年的一个教程里也总结了基于BP的前馈网络的问题。
(1)数据:带标签的数据集很小,只有现在(2015)的千分之一。
(2)算力:计算性能很低,只有现在(2015)的百万分之一。
(3)算法:权重的初始化方式和非线性模型错误。
后来,数据问题和算力问题被时间解决了,而算法问题早在2006年前后就被解决了(即深度学习革命)。
回到1995年,那时大家并没有Hinton在20年后的这些洞见,但是也能意识到神经网络的这些问题很难解决。再一次,“极高的期待导致极度的怀疑”,未能兑现的承诺导致了资金的快速撤离和学术热情的大幅下降。几乎所有的神经网络公司都关门了——至少有300家AI公司,包括Minsky的Thinking Machines(1994)也关门了。

陈列在美国国家密码博物馆的 Thinking Machines Corporation 宣传海报
这时候恰好出现了基于统计机器学习的其他竞争方法,导致大家逐渐抛弃了神经网络而转向统计机器学习,如支持向量机(SVM)、条件随机场(CRF)、逻辑回归(LR回归)等。其实这些方法也都和神经网络有千丝万缕的联系,可以证明与某些特定的网络等价,但是相对简单、快速,加上出现了一些成熟的工具,到20世纪90年代后期在美国就成为主流了。
这里只对SVM做一下分析。1963年SVM刚出现的时候,和单层感知器一样,都只能处理线性分类问题。两者后来能处理非线性问题,本质都是对原始的数据进行了一个空间变换,使其可以被线性分类,这样就又可以用线性分类器了,只是两者对如何做空间变换途径不同:
- 对于神经网络,是用隐藏层的矩阵运算,使得数据的原始坐标空间从线性不可分转换成了线性可分;
- 对于SVM,是利用“核函数”来完成这个转换的。
1995年,由Vladimir Vapnik(LeCun在贝尔实验室的同事)等人以Support Vector Network的名义发布了改进后的SVM,很快就在多方面体现出了相较于神经网络的优势:无需调参,速度快,全局最优解,比较好地解决了上述BP算法的问题,很快就在算法竞争中胜出。因此,虽然第二次神经网络进入低谷没有一个标志性事件,但是一般认为Vapnik发表“Support Vector Network”这篇文章的1995年可以算转折点。
SVM到底算不算神经网络的一种呢?其实线性的SVM和线性的感知器是等价的。两者都是从线性模型到深度学习之间过渡,即:
- 线性模型;
- 线性SVM ⇔ 单层感知器;
- 非线性核SVM ⇔ 多层感知器;
- 深度学习。
只是,SVM以牺牲了一点表达力灵活性(通常核函数不是任意的)为代价,换来了实践上的诸多方便。而神经网络在之后的17年里,逐渐从“主流”学术界消失了,直到跌到了“鄙视链”的最下面。据说Hinton从20世纪90年代到2006年大部分投稿都被会议拒掉,因为数学(相比统计机器学习)看起来不够“fancy”(新潮)。
20世纪90年代中期到2010年左右在整体上被认为是第二个AI冬天,神经网络无疑是其中最冷的一个分支。值得一提的是,这段时间内互联网兴起,连带导致机器学习方法和语义网方法的兴起,算是这个寒冬里两个小的局部春天。不过在这个神经网络“潜龙勿用”的第二个蛰伏期,有些学者依然顽强坚持着,转机又在慢慢酝酿。
第三周期的复兴:深度学习
Geoffrey Hinton、Yoshua Bengio和Yann LeCun获得2018年图灵奖是众望所归。

Geoffrey Hinton, Yoshua Bengio, Yann LeCun(从左至右),拍摄者:Eviatar Bach, Jérémy Barande
在那漫长的神经网络的第二个冬天里,正是他们的坚持才迎来了第三周期的复兴,而且势头远远大于前面两次。其中,Hinton是1986年和2006年两次里程碑式论文的作者,也是BP算法和玻尔兹曼机的提出者;Bengio在词嵌入与注意力机制、生成式对抗网络、序列概率模型上有贡献;LeCun独立发现并改进了BP算法,发明了卷积神经网络。
——
下篇
本文为文因互联CEO鲍捷为《深度学习导论》一书作序

作者:[美]尤金·查尔尼克(Eugene Charniak)
- 人工智能经典入门书
- 美国常青藤名校经典教材
- 理论与实战结合的良好典范
- 附带习题和答案
本书讲述了前馈神经网络、Tensorflow、卷积神经网络、词嵌入与循环神经网络、序列到序列学习、深度强化学习、无监督神经网络模型等深度学习领域的基本概念和技术,通过一系列的编程任务,向读者介绍了热门的人工智能应用,包括计算机视觉和自然语言处理等。
本书编写简明扼要,理论联系实践,每一章都包含习题以及补充阅读的参考文献。
本书既可作为高校人工智能课程的教学用书,也可供从业者入门参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号