NIPS 2015 Part 2
NIPS 2015 Part 2
Continuing from Part 1 from Neural Information Processing Systems conference 2015 at Montreal.
Linear Response Methods for Accurate Covariance Estimates from Mean Field Variational Bayes
Ryan J. Giordano, Tamara Broderick, Michael I. Jordan
Variational inference often results in factorized forms of approximate posterior that are tighter than the exact Bayesian posterior. Authors derive a method to recover the lost covariance among parameters by perturbing the posterior. For exponential family variational distribution, a simple closed form transformation involving the Hessian of the expected log posterior. [julia code on github]
Solving Random Quadratic Systems of Equations Is Nearly as Easy as Solving Linear Systems
Yuxin Chen, Emmanuel Candes
R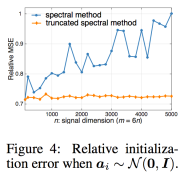 ecovering x given noisy squared measurements, e.g.,
ecovering x given noisy squared measurements, e.g., ")

Closed-form Estimators for High-dimensional Generalized Linear Models
Eunho Yang, Aurelie C. Lozano, Pradeep K. Ravikumar
Authors derive closed-form estimators with theoretical guarantee for GLM with sparse parameter. In the high-dim regime of 


Newton-Stein Method: A Second Order Method for GLMs via Stein’s Lemma
Murat A. Erdogdu
By replacing the sum over the samples in the Hessian for GLM regression with expectation, and applyingStein’s lemma assuming Gaussian stimuli, he derived a computationally cheap 2nd order method (O(np) per iteration). This trick relies on large enough sample size 

Stochastic Expectation Propagation
Yingzhen Li, José Miguel Hernández-Lobato, Richard E. Turner
In EP, each likelihood contribution to the posterior is stored as an independent factor which is not scalable for large datasets. Authors propose to further approximate by using n copies of the same factor thus making the memory requirement of EP independent of n. This is similar to assumed density filtering (ADF) but with much better performance close to EP.
Competitive Distribution Estimation: Why is Good-Turing Good
Alon Orlitsky, Ananda Theertha Suresh
Best paper award (1 of 2). Shows theoretical near optimality of Good-Turing estimator for discrete distributions.
Learning Continuous Control Policies by Stochastic Value Gradients
Nicolas Heess, Gregory Wayne, David Silver, Tim Lillicrap, Tom Erez, Yuval Tassa
Using the reparameterization trick for continuous state space, continuous action reinforcement learning problem. [youtube video]
High-dimensional neural spike train analysis with generalized count linear dynamical systems
Yuanjun Gao, Lars Büsing, Krishna V. Shenoy, John P. Cunningham
A super flexible count distribution with neural application.
Unlocking neural population non-stationarities using hierarchical dynamics models
Mijung Park, Gergo Bohner, Jakob H. Macke
Latent processes with two time scales: one fast linear dynamics, and one slow Gaussian process.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号