
CVPR2021-ACON(Activate Or Not)
CVPR2021-ACON(Activate Or Not)
论文题目:Activate or Not: Learning Customized Activation
作者:Ningning Ma , Xiangyu Zhang , and Jian Sun
单位:Hong Kong University of Science and Technology,MEGVII Technology
文章简介:这是一篇来自于CVPR2021的一篇顶会论文,主要工作是对Relu函数(以及变体Leaky-ReLU, PReLU)的改进,并提出一个meta-ACON激活函数和其设计空间,它可以自适应的选择是否激活神经元。实验表明,利用本文中的激活函数替换原网络的激活函数可以提高1-2点的网络精度,效果较好。
论文地址:Activate or Not: Learning Customized Activation
meta-ACON开源代码:https://github.com/nmaac/acon/blob/main/acon.py
Smooth Maximum
Relu是一个在深度学习中经常使用的激活函数,其本质上是一个Max函数,考虑一个输入的公式如下:
而MAX函数的平滑,可微分变体我们称为Smooth Maximum,其公式如下:
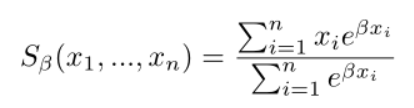
其中,β是一个平滑因子,当β趋近于无穷大时,Smooth Maximum就变为标准的MAX函数,而当β为0时,Smooth Maximum就是一个算术平均的操作。
这里我们只考虑Smooth Maximum只有两个输入量的情况,于是有以下公式:

其中, 和
是线性函数,
是sigmoid函数。上面最后一步推导可能有人看不太明白,其实就是sigmoid函数有这样一个关系:
再令 ,
,得到第一个改进激活函数ACON-A:
图像如下:
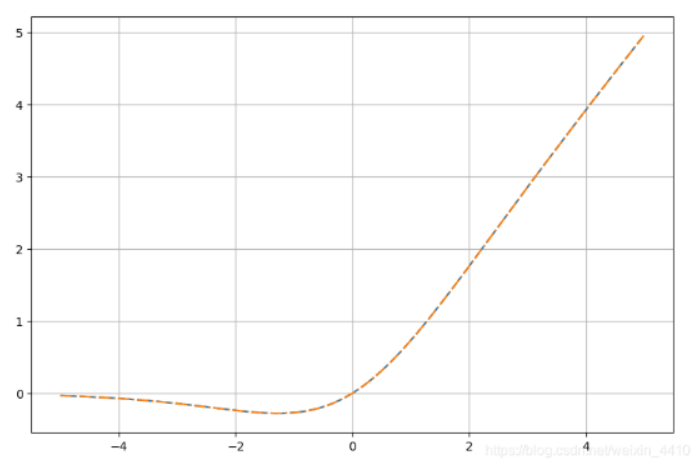 ACON-A
ACON-A
原论文中说这个函数其实就是Swish函数,是一种这几年广泛采用的新的激活函数,但是目前尚未给出合理解释改函数为什么表现能力能提高。从上述解释可以看出Swish其实是Relu的光滑近似。
与上述类似,当考虑Relu的变体PReLU,即:
其中,p<1。
令 ,
,得到第二个改进激活函数ACON-B:
对上述PRelu再灵活一些,考虑另一种Relu的变体:
其中, 。
令 ,
,得到第三个改进激活函数ACON-C:
ACON-C能涵盖之前的,甚至是更复杂的形式,在代码实现中,p1和p2使用的是两个可学习参数来自适应调整。
我们简单看下ACON-C的函数性质 对其求一阶导,可以得到
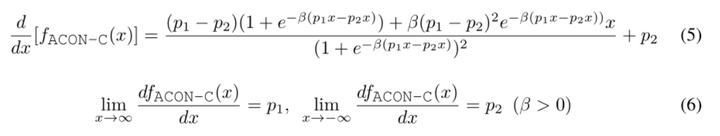
当 x 趋近于正无穷时,其梯度为 p1,当x趋近于负无穷时,其梯度为 p2。
对其求二阶导,有:
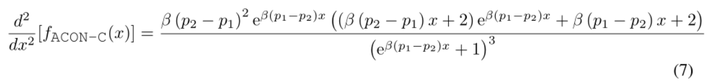
为了得到一阶导的上下界,我们令其二阶导为0,求得一阶导上下界分别为:
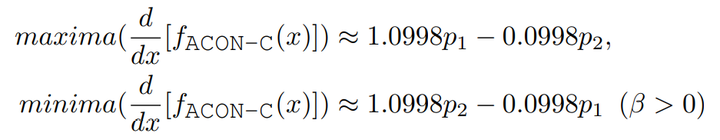
可以看到ACON-C下,一阶导的上下界也是通过p1和p2两个参数来共同决定的。
最后总结下各个形态的公式:

Meta-ACON
前面我们有提到,ACON系列的激活函数通过β的值来控制是否激活神经元(β为0,即不激活)。因此我们需要为ACON设计一个计算β的自适应函数。
而自适应函数的设计空间包含了layer-wise,channel-wise,pixel-wise这三种空间,分别对应的是层,通道,像素。
这里我们选择了channel-wise,首先分别对H, W维度求均值,然后通过两个卷积层,使得每一个通道所有像素共享一个权重。公式如下:
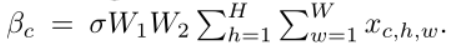
We use,
to save parameters (r=16 by default).
这个公式个人认为写的不是很清楚,通过看作者公开的源码可知,后面个人认为应该是对H和W维度分别求均值(但是写成了求和),W1和W2分别是两次卷积操作,上面这种写法很容易让人误解。W1第一个C是输入的维度,C/r是输出的维度;W2第一个C/r是输入的维度,C是输出的维度。为了节省参数量,我们在W1和W2之间加了个缩放参数r,默认设置为16。
源码如下:
import torch
from torch import nn
class MetaAconC(nn.Module):
'''
ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x
'''
def __init__(self, width):
super().__init__()
self.fc1 = nn.Conv2d(width, width//16, kernel_size=1, stride=1, bias=False)
self.fc2 = nn.Conv2d(width//16, width, kernel_size=1, stride=1, bias=False)
self.p1 = nn.Parameter(torch.randn(1, width, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, width, 1, 1))
self.sigmoid = nn.Sigmoid()
def forward(self, x, **kwargs):
beta = self.sigmoid(self.fc2(self.fc1(x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True))))
return (self.p1 * x - self.p2 * x) * self.sigmoid( beta * (self.p1 * x - self.p2 * x)) + self.p2 * x首先作者设置了p1和p2这两个可学习参数,并且设置了fc1和fc2两个1x1卷积。在前向过程中,首先计算beta,x首先在H和W维度上求均值,然后经过两层1x1卷积,最后由sigmoid激活函数得到一个(0, 1)的值,用于控制是否激活。
Experimental Verification
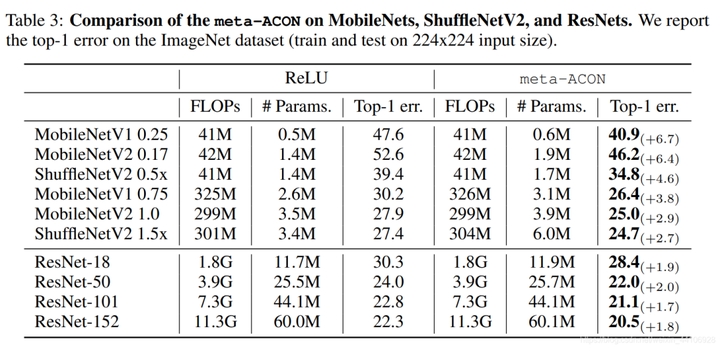
作者针对不同大小的网络做出了调整,针对小网络它替换了所有ReLU激活层,针对大网络(如ResNet50/101)只替换了每一个Block中3x3卷积后面的ReLU激活层,作者怎么设置的理由是避免过拟合,但我个人认为如果全都换成Meta-ACON,额外增加的参数量是很大的。
Meta-ACON虽然带来了一定的参数量,但是对大网络和小网络上都是有一定的提升。
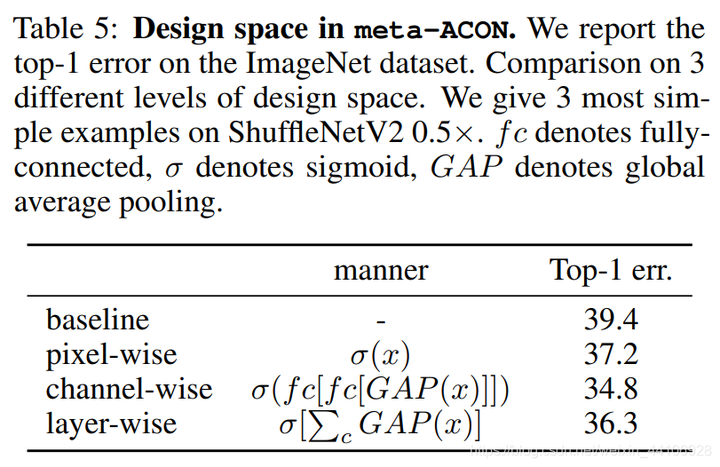
作者还针对设计空间做了一系列消融实验,其中channel-wise的效果是最好的。
Conclusion
该工作是之前旷视FReLU激活函数,ShuffleNet的作者MaNingNing提出的,构思十分巧妙,将ReLU和NAS搜索出来的Swish激活函数联系起来,并推广到一般的形式,为了让网络自适应的调整是否激活,设置了两层1x1卷积来控制。从实验上也从各个角度论证其有效性,期待后续对激活函数的进一步探索。
本文参考:激活还是不激活?CVPR2021-Activate Or Not

 浙公网安备 33010602011771号
浙公网安备 33010602011771号