

读《这就是搜索引擎:核心技术详解》有感总结
目录:
搜索引擎的使用对于我们来说不陌生,对于一个正常的搜索流程,比如用户输入查询“搜索引擎 技术”,搜索引擎需要分别将存储的磁盘上的两个单词的倒排序索引读入内存,之后进行解压缩,然后求两个单词对应倒排序列表的搅基,找到所有包含两个单词的文档集合,根据排序算法来对每个文档的相关性进行打分,按照相关度输入相关最高的搜索结果。
但是对于这系列步骤中海量文档数据的来源,存储,查找的技术又是如何的呢?下面是我最近看了《这就是搜索引擎:核心技术详解》这书的大致总结:
首先,搜索引擎的文档数据从何而来?
站长们通用的一个常识就是当自己部署了一个网站之后,会向Google、百度、bing等搜索引擎的 提交收录页面进行自己页面的提交,以便于他们的爬虫更快的抓取到提交网站的页面。
啥,不知道爬虫?不了解的点我科普
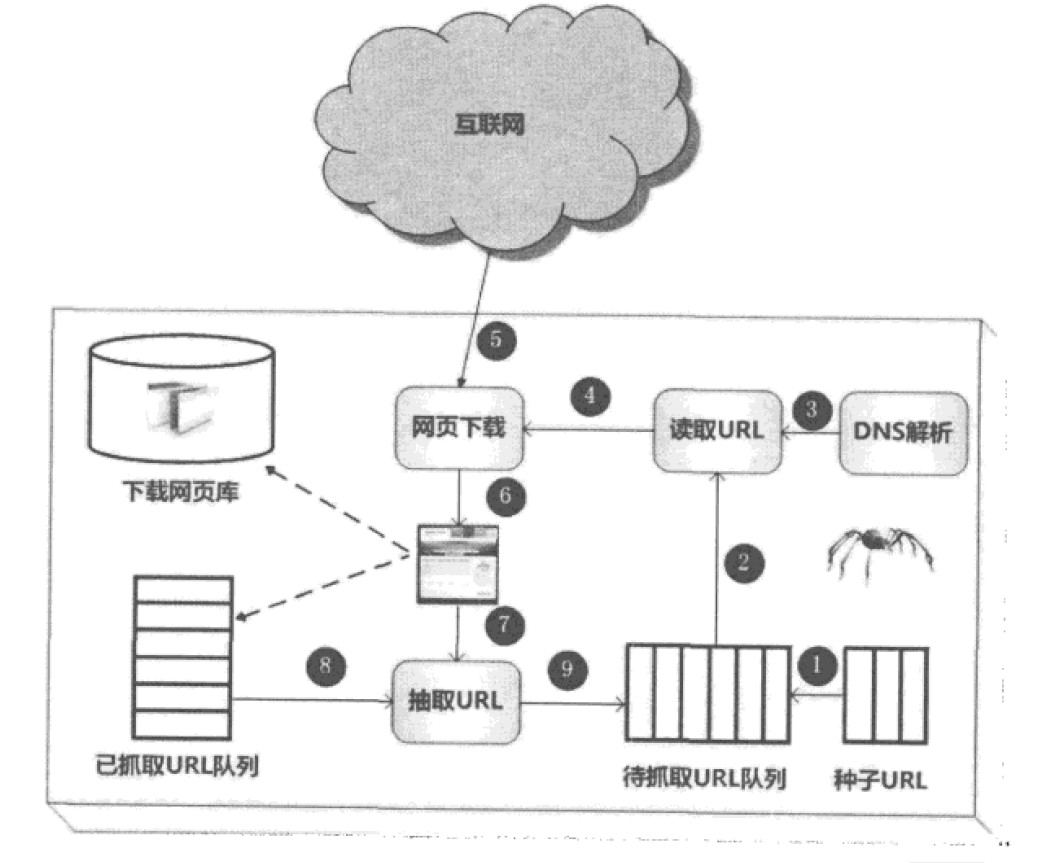
爬虫的通用框架
现在的爬虫大多为分布式爬虫了,在抓取策略中有:
-
- 宽度优先遍历策略(Breath First)
- 非完全PageRank策略
- OCIP策略(Online Page Importance Compution)
- 大站优先策略(Larger Sites First)
但是在垂直领域的网站,比如携程网的机票数据,京东的商品等页面很难有显示的链接去指向,还是需要通过用户去输入关键词搜索而得,这样的话按照爬虫的规则很难抓取到这种页面,所以就出现了暗网抓取,简单的说就是爬虫在搜索页面提交查询的组合,再搜录目标网站提交查询后的页面,基于暗网抓取,百度提出了“阿拉丁计划”,示例,Google的Onebox,示例
不过现在想一下,在互联网上最方便的事情就是拷贝抄袭了,统计结果表明,近似重复网页的数量占网页总数量的比例高达%29,而完全相同相同的页面大约占全部页面的%22,即互联网页面中有相当大比例的内容是完全相同或者大体相近的。比如新闻主题内容是几乎完全相同的,但是两个页面的网页布局有较大的差异,为解决这样的问题需要网页去重,尽量不给用户呈现重复的搜索结果,体现原创性,提供用户搜索体验。
主要的网页去重算法有:Shingling, I-Match, Simhash,SpotSig等。
对于海量的网页文档内容,得用索引才能快速找到查询的网页。
为了应对海量的文档以及各类查询,搜索引擎常用倒排索引作为单词到文档的映射。


最简单的倒排索引
倒排索引主要包含单词词典和对应的倒排列列表,并其相关技术选择:
-
- 存储时常用哈希加列表或树形结构
- 新建索引时使用并归法效率较高
- 在更新索引时采用原地更新和再合并的混合策略最有效
- 在查询时把短语索引、位置索引、双词索引混合起来,发挥各自的长处
- 在分布式方面有按文档和按单词两种划分方法,前者在扩展性、负载均衡性、容错性上均有优势。
- 在压缩方面,用单词连续存储以及相邻词典项指向同一指针的方式来省出指针信息,以达到词典压缩,用PForDelta算法来实现倒排序索引的压缩。
有了海量数据文档以及对其作了相应的排序之后,如何找出搜索的相关文档呢?
判断网页内容是否与用户查询有关,这依赖于搜索引擎所采用的检索模型:
布尔模型:使用简单的“与/或/非”这些逻辑关系来判断文档与查询词是否相关,根据此模型得出的搜索结果过于粗糙,无法满足用户需求。
向量空间模型:将查询词和文档中关键词转为特性向量,然后使用余弦公式
![]()
来计算文档与查询的相关度并排序输出结果。关于其中的特征向量权值计算,也称TF*IDF框架,词频TF表示一个单词在文档中出现的次数,IDF表示查询词在所以文档中出现频率的反值:
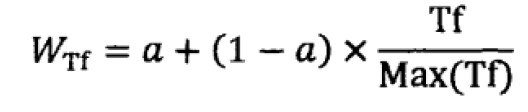
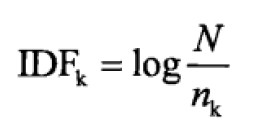
特征权重值即他们的乘积,用具体的中文解释描述为:
- 如果文档中某个查询词的词频很高,而且这个单词在其他的文档集合中很少出现,那么这个单词的权重值很高。
- 如何文档中某个查询词的词频也很高,但是这个单词在文档集合中的其他文档中经常出现,或者是词频不高,但是在其他的文档中经常出现,那么这个单词的权值一般。
- 如何文档中某个查询词的词频很低,同时这个单词在其他的文档中经常出现,那么这个单词的权值很低
概率检索模型:对于某个文档D来说,如果其属于相关文档子集的概率大于不属于不相关子集的概率,那么这个文档就是与用户查询相关的,即 ![]()
其具体算法就是使用MB25模型来计算:
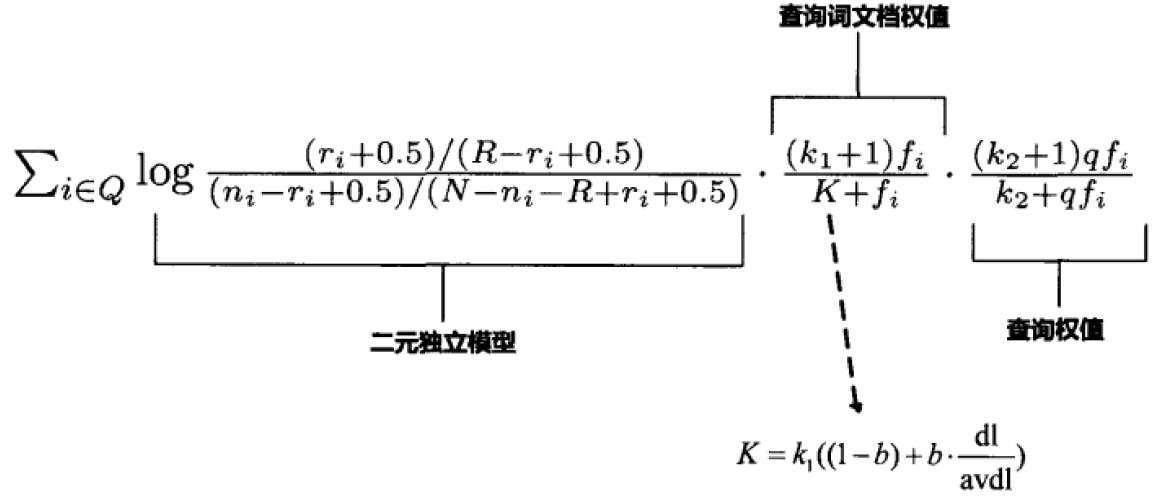
该模型已经是一个非常成功的概率模型方法,当然后人也有对其的其他改进。
搜索引擎的最终搜索结果不仅仅根据文档相关性,同时还得考虑网页的重要性。
搜索引擎在查找能够满足用户请求的网页时,主要考虑两方面的因素:一方面使用户发出的查询与网页内容的相似性得分,另一方面 就是通过链接分析方法计算获得的得分,即网页的重要性,搜索引擎融合两者,共同拟合出相似性评分函数,来对搜索进行排序。

基本链接分析算法关系图
搜索引擎中常常使用链接分析算法来进行网页间的重要性排名,比较基础又著名的为PageRank和Hits算法,前者主要以随机游走模型来计算法,后者则以子集传播模型为理论基础,当然后来为弥补其算法的缺点又产生了很多类型的改进,比如“主题敏感的PageRank”算法来改善原始Pagerank的主题偏离,Hilltop结合Hits和pagerank等。
但是出于商业利益驱使,很多网站站长会针对搜索引擎排名进行分析,并采取一些手段来提高网站排名,但是也存在恶意优化的行为,严重影响搜索搜索引擎用户的体验,所以也提出了一些算法来应对各种恶意作弊:TrustRank,BadRank,SpamRank等。并且这些反作弊算法的结果权重占搜索占了很大的比重。
搜索引擎需要存储和计算的数据 数以亿记,而且觉得部分都是无结构或者半结构化的数据,如何构建存储平台和计算平台,使得存储和管理简单化成为了重要问题。以Google为代表的提出了他的三驾马车:GFS/BingTable/MapReduce,Google曾发布了这三驾马车的相关技术详解论文,成就了现在云计算新宠“Hadoop”的诞生。
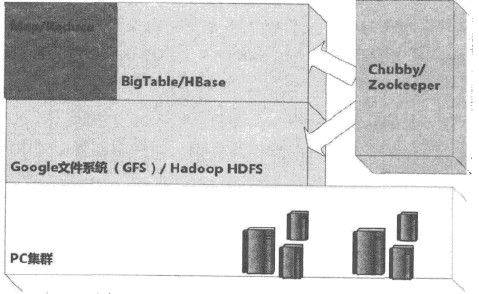
hadoop与三驾马车的关系
GFS:Google的分布式文件系统,由大量PC构成,机器出现故障时常态,并且支持水平增量扩展,可以存储百亿计的海量网页信息。(HDFS被认为GFS的开源实现)
BigTable:是一种针对海量结构化或者半结构化存储的存储模型,以GFS为基础,其存储模型介于关系型数据和NoSql存储系统之间,特别适合一次写入,多次读取,很少修改的业务需求。(HBase被认为是BigTable的开源实现)
Map/Reduce:它是一种分布式云计算模型,本质上是通过分而治之的思想实现,往往是多个MapRduce子任务的先后串联,前面的Map阶段往往作为后续的Reduce阶段的输入进行一些列复杂任务的计算。(使用该模型最著名的开源代表就是Hadoop)
Pregel:基于BSP的同步计算模型,用来解决大规模分布式图计算问题,弥补Map/Reduce在图计算上的不足,一次迭代计算被陈伟一个超步,系统从一个超级不迈向另一个超级不,直达达到算法的终止条件,Google前期的PageRank算法主要使用Pregel平台进行计算.( Giraph则被认为Pregel的开源实现,后来卡耐基梅隆大学发明了另一种分布式图处理模型:GraphLab)
由于开源Hadoop的出现,驾驭Google这三架马车也变得越来越简单,当前Hadoop也已经成功的投入的商业,并且有Facebook,阿里,腾讯这些巨头的支持。
现在大家应该都意识到搜索引擎已经成为了进入各大网站的主要入口,点击“百度一下”,经常上面复杂的计算搜索结果将会很快呈现的浏览器上,这么快的速度还主要是靠缓存的功劳。
搜索引擎的缓存设计主要以缓存搜索结果和缓存搜索单词的倒排序索引为主,前者响应速度快,但是命中率不高,后者取得缓存之后还得重计算得分,响应速度相对慢,但是命中率比较高。所以现在常用的缓存将两者结合起来,先使用结果缓存,再使用单词的到排列列表缓存,并且该缓存还分为倒排列单词的组合计算得分缓存和独立倒排列两级缓存,集合用户响应速度和命中率高两个优点。
写在后面:
上述总结主要是针对搜索引擎的大致流程,仅为个人大致读完该书之后的看法,现在技术的发展比我们看的东西要快的多,所以文中有不当之处请各位指点,共同学习,共同进步。
文中的插图主要来源于该书本。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· SQL Server 2025 AI相关能力初探
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库