矿池负载运行监测记录
从2019年2月开始开发矿池程序时,从矿池开发的一个陌生人,从不懂到学习,到实践,本文没有办法记录所有细节,只将在实践过程中遇到的重点问题记录一下,供后续人士参考。
由于从事矿业软件开发的人,在全球都很少,从事矿池开发的就更少了,找不到可以参考的完整例子及各种问题的解答,由于遇到的问题又与各币种、算法、各厂家矿机等多因素相关,导致排查问题时,特别难以锁定。
在网上搜索后,被广泛使用的矿池程序有mpos,nomp,unomp,CoiniumServ,以及基于nomp的各种变种矿池。我们在对比了 CoiniumServ以及unomp后,选择基于unomp做基础,改造开发。
性能问题:unomp 对nomp 改造主要是基于nomp使用MySql 后,MySql成为了整个系统的性能瓶颈。
我们在第一个版本开发时,也使用了基于 MySql(也兼容其它关系型数据库)做数据持久化存储,发现在 4000台机器时,MySql 已严重拖累了整个系统的效能,好在MySql虽然性能差,但并未出现过死机等情况,可靠性还是很高的。基于此,如果多矿池,每个矿池几万台矿机的量,MySql是扛不住了。因此,考虑更换持久化存储。能过性能测试,选择了MongoDB,它有超过10-100倍的性能提升,还是在未做性能优化的前提下的测试结果。
经过一周左右的时间,将数据存储更换为MongoDB, 目标选定为3万台矿机,在一台24核,16G的服务器上,可以稳定运行48-72小时,时有宕机,原因未明。
又是莫名的问题,排查陷入无头绪的各种尝试。首先,降低 CPU使用率,通过优化MongoDB,CPU使用率降到了 平均40%左右,最高90%,硬件在这个水平是刚好,满足需求。但宕机的问题,在48-72小时时,仍然发生,因此可以确信,问题没有得到根本解决。
查看分析日志,错误有:
这个异常提示,Redis内存耗尽, 为什么为这样?原因为缓存已达到Redis的内存使用上限,解决办法为:设置当Redis达到内存上限时,设置淘汰策略。这样可以使已分配的内存置换出来。
Redis 持久化存储时,如果数据量很大,比如10G以上,而服务器的内存又只有16G,此时将导致Redis转储失败,停止服务。解决办法:将Redis可以使用的最大内存设置为 系统内存的一半以下。此时Redis 在Fork一个进程转储时可以正常进行。
另外,当Redis达到最大内存时,设置其不能停止服务。
以下错误至今无法解决:
2019-03-25 05:33:24,485 [79] ERROR IBeam.Cache.Redis.RedisProvider [(null)] - GetRedis Host=127.0.0.1,Port=6379,Error=System.InvalidOperationException: No servers are connected or configured. 在 CacheManager.Core.BaseCacheManager`1..ctor(String name, ICacheManagerConfiguration configuration) 在 CacheManager.Core.BaseCacheManager`1..ctor(ICacheManagerConfiguration configuration) 在 CacheManager.Core.CacheFactory.Build[TCacheValue](String cacheName, Action`1 settings) 在 IBeam.Cache.Redis.RedisProvider.GetRedis(String host, Int32 port, Int32 database, String password)
2019-03-25 05:33:24,485 [79] ERROR System.RuntimeType [(null)] - TryTimesDo TryTimes=2, ActionHandler=System.Object CGet(System.String),Val1=CPpI4tlMoULGbhXAx+FAg7nXox4=,Error=StackExchange.Redis.RedisConnectionException: No connection is available to service this operation: EVAL; SocketFailure on 127.0.0.1:6379/Interactive, origin: CheckForStaleConnection, input-buffer: 0, outstanding: 62, last-read: 1s ago, last-write: 1s ago, unanswered-write: 1s ago, keep-alive: 60s, pending: 0, state: ConnectedEstablished, in: 0, ar: 0, last-heartbeat: 1s ago, last-mbeat: 0s ago, global: 0s ago, mgr: RecordConnectionFailed_ReportFailure, err: never; IOCP: (Busy=0,Free=1000,Min=16,Max=1000), WORKER: (Busy=98,Free=925,Min=16,Max=1023), Local-CPU: n/a ---> StackExchange.Redis.RedisConnectionException: SocketFailure on 127.0.0.1:6379/Interactive, origin: CheckForStaleConnection, input-buffer: 0, outstanding: 62, last-read: 1s ago, last-write: 1s ago, unanswered-write: 1s ago, keep-alive: 60s, pending: 0, state: ConnectedEstablished, in: 0, ar: 0, last-heartbeat: 1s ago, last-mbeat: 0s ago, global: 0s ago, mgr: RecordConnectionFailed_ReportFailure, err: never --- 内部异常堆栈跟踪的结尾 --- 在 IBeam.Cache.Redis.RedisProvider.InternalGet(String cacheKey) 在 IBeam.Cache.Redis.RedisProvider.CGet(String cacheKey) 在 IBeam.MDAA.ActionHelper.TryTimesDo[T1,TResult](MAction`2 actionHandler, T1 val1, Int32 tryTimes)
表现出的现象为:Redis没有可用连接,重启Redis服务,故障排除,但问题是不知道Redis什么时候出故障,运维难度高。目前为了排除这个故障,将Redis部署为集群节点,由Redis节点保证服务的高可用。可能存在Socket端口耗尽的问题,由于没有时间去排查,直接将Redis服务移到Linux平台上,由专门的机器运行,或直接使用云平台的 集群节点。
另外,MongoDB在运行的近一个月时间中,前期运行一直都正常,但后面几天,伴随Redis宕机时,MongoDB也宕机,为了保证高可用及可靠性,建议还是单独移出来单独部署或使用分片+复本集。
根据以上经验分开部署后的单机节点运行情况如下:
Redis服务器(8核16G):
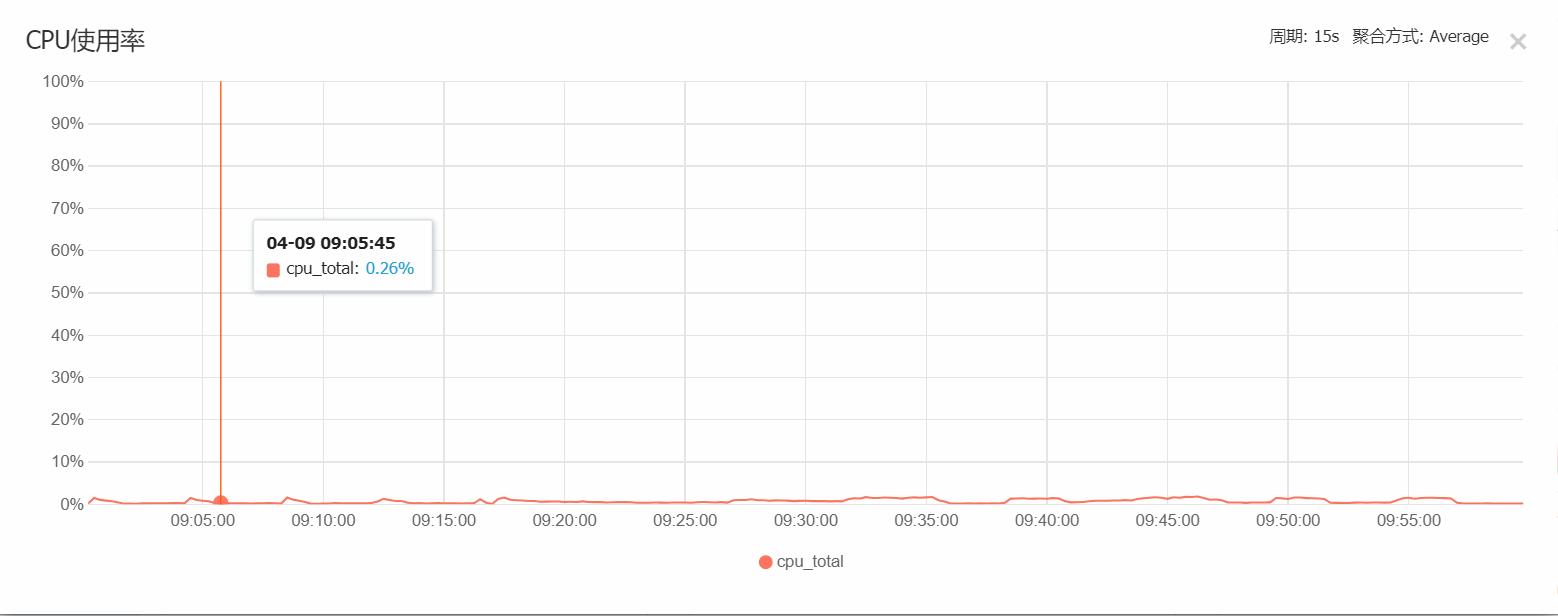
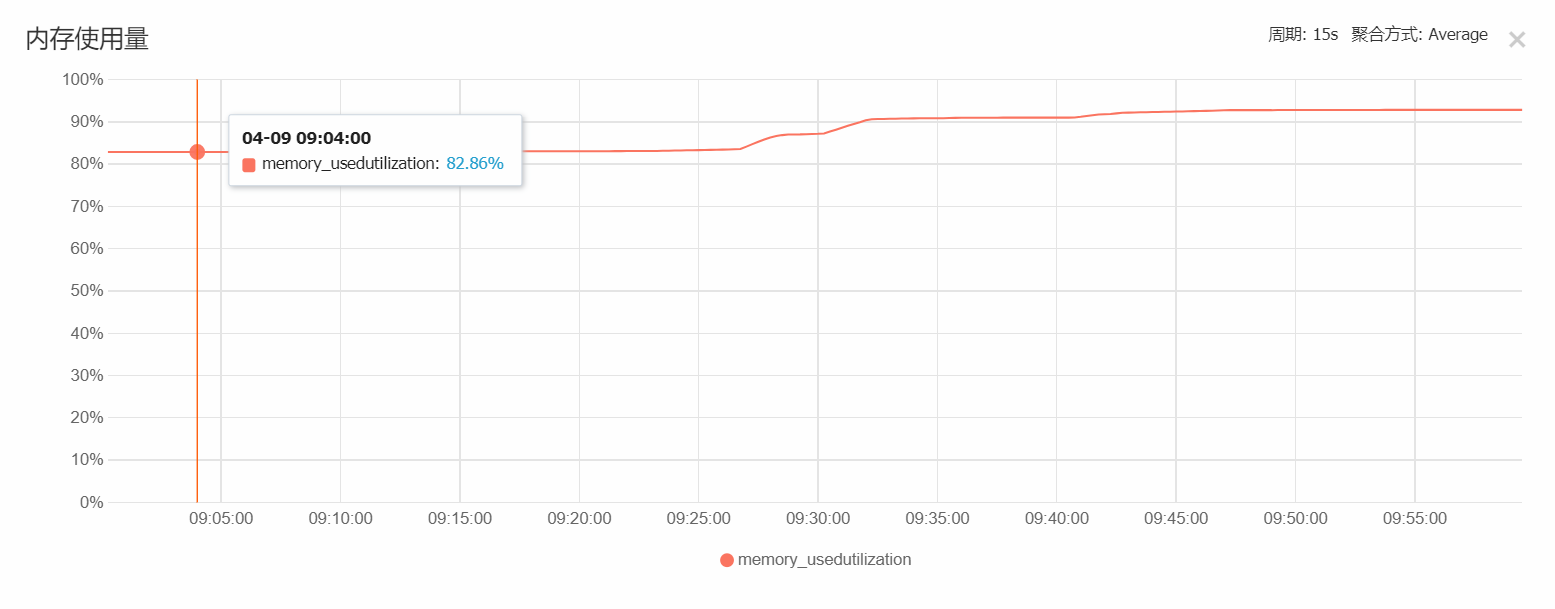
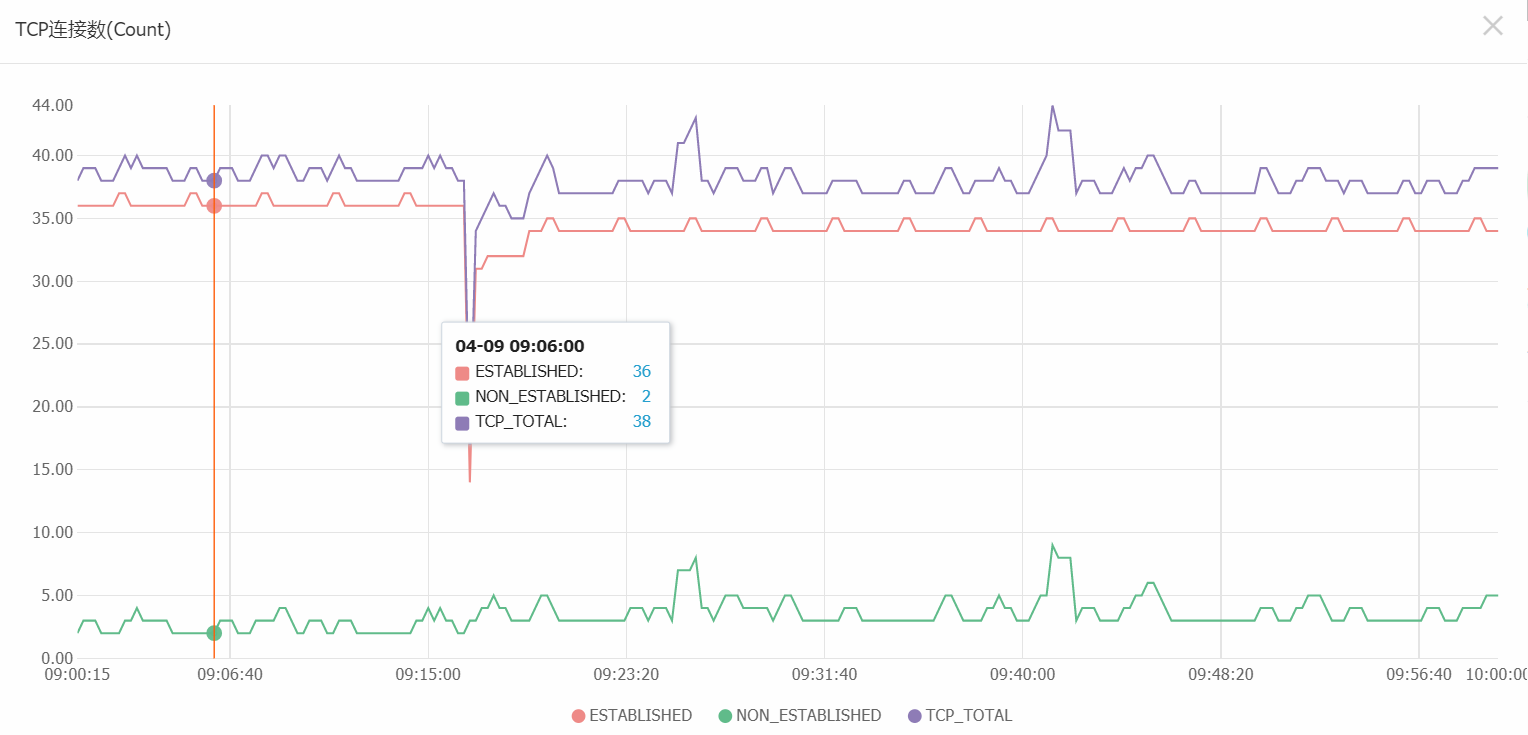
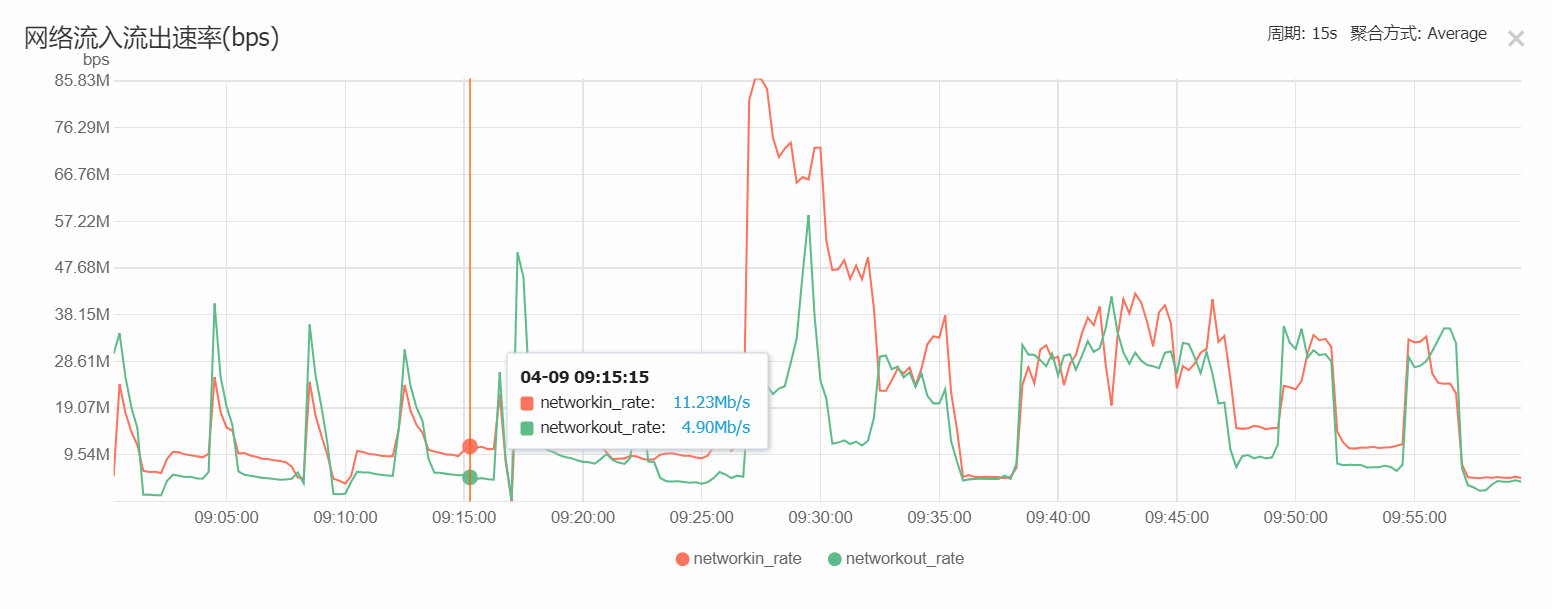
可以看出,在3000台负载中,整个8核的使用率很低,可以将此节点降为 1核16G即可,我们在实际使用中,Redis只是作为缓存使用,不开启持久化存储
Web及适配器服务器(4核4G):
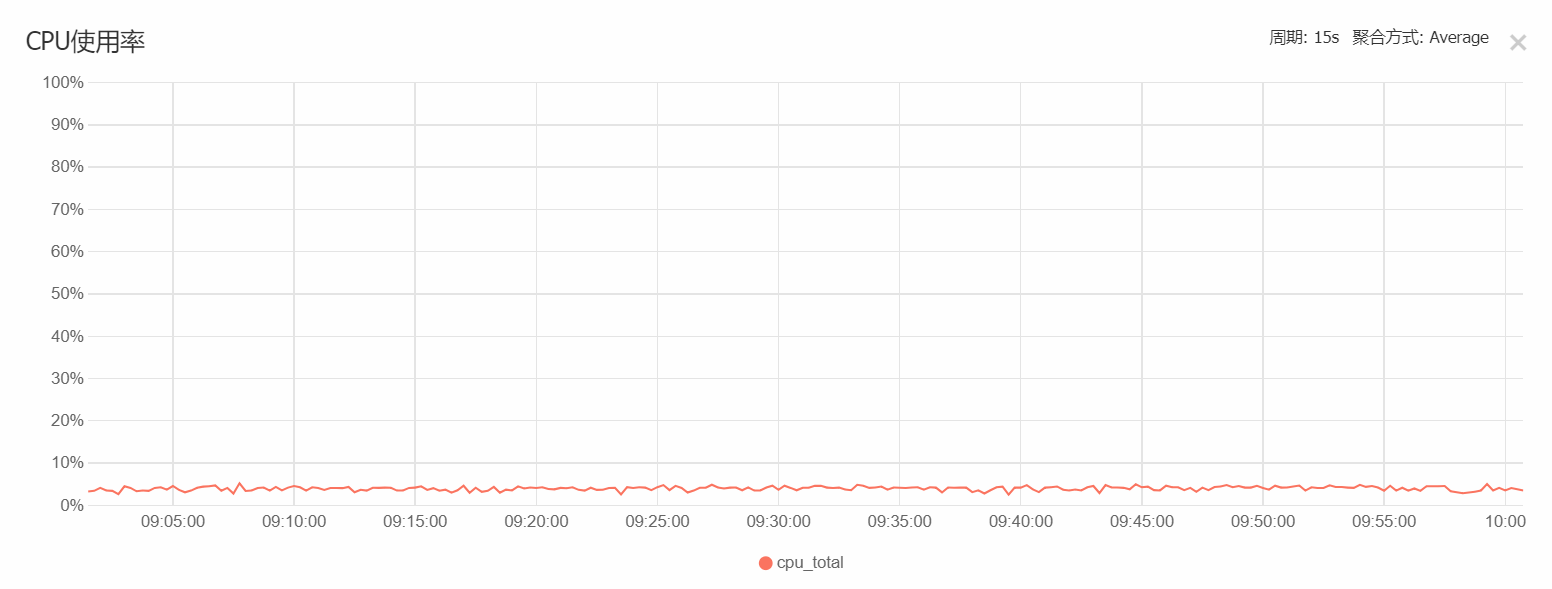
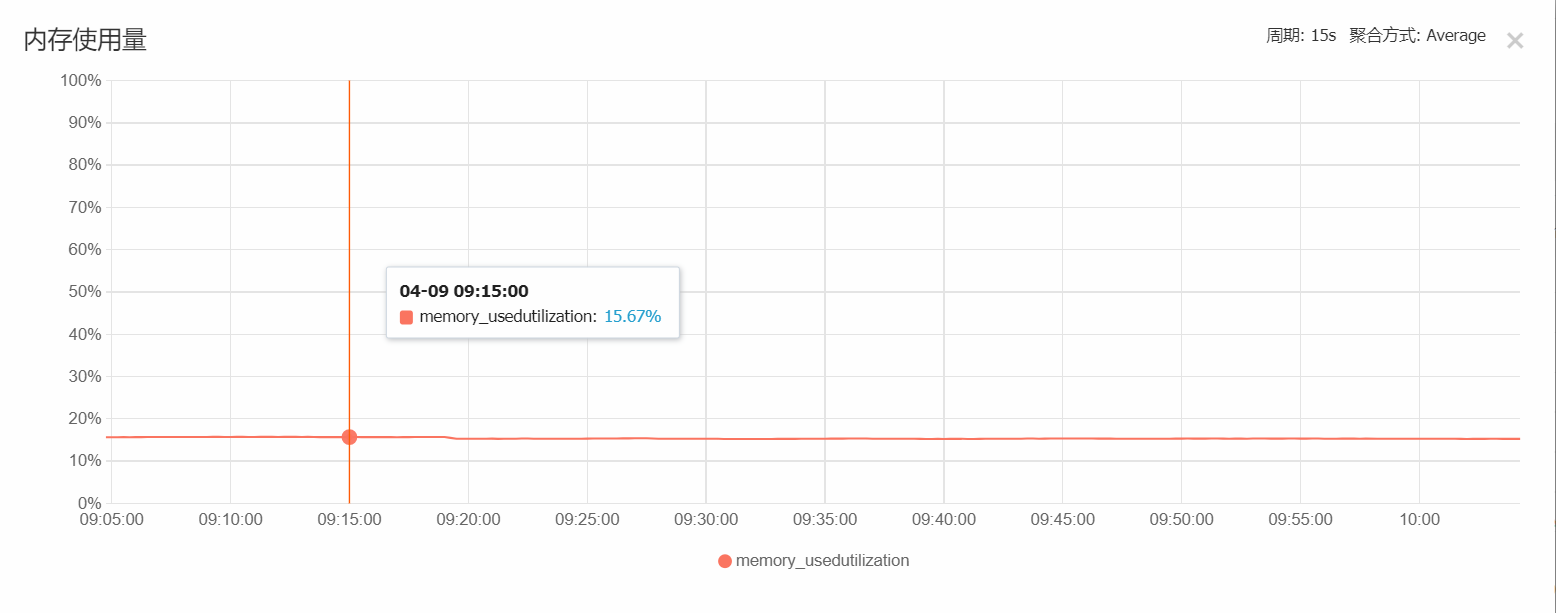
在实际cpu负载监测下,CPU在计算期间的峰值达到了 40%,满足使用。
MongoDB服务器(4核8G):
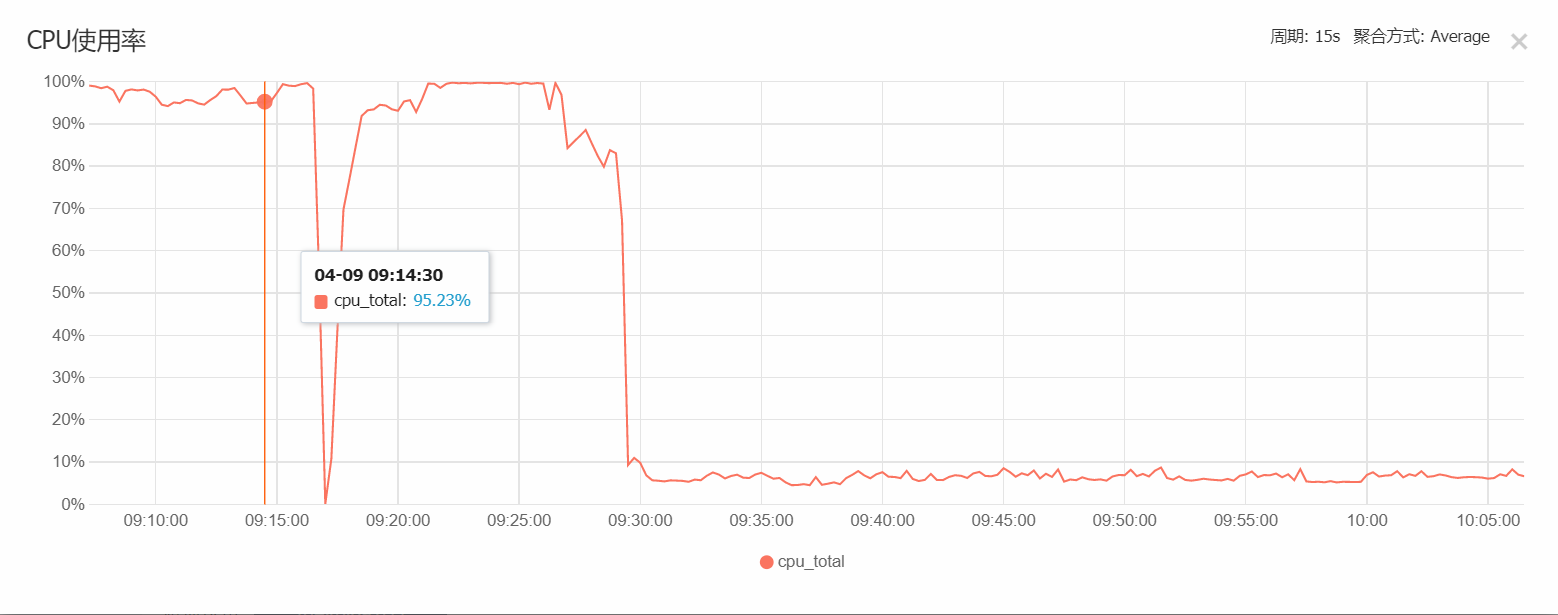
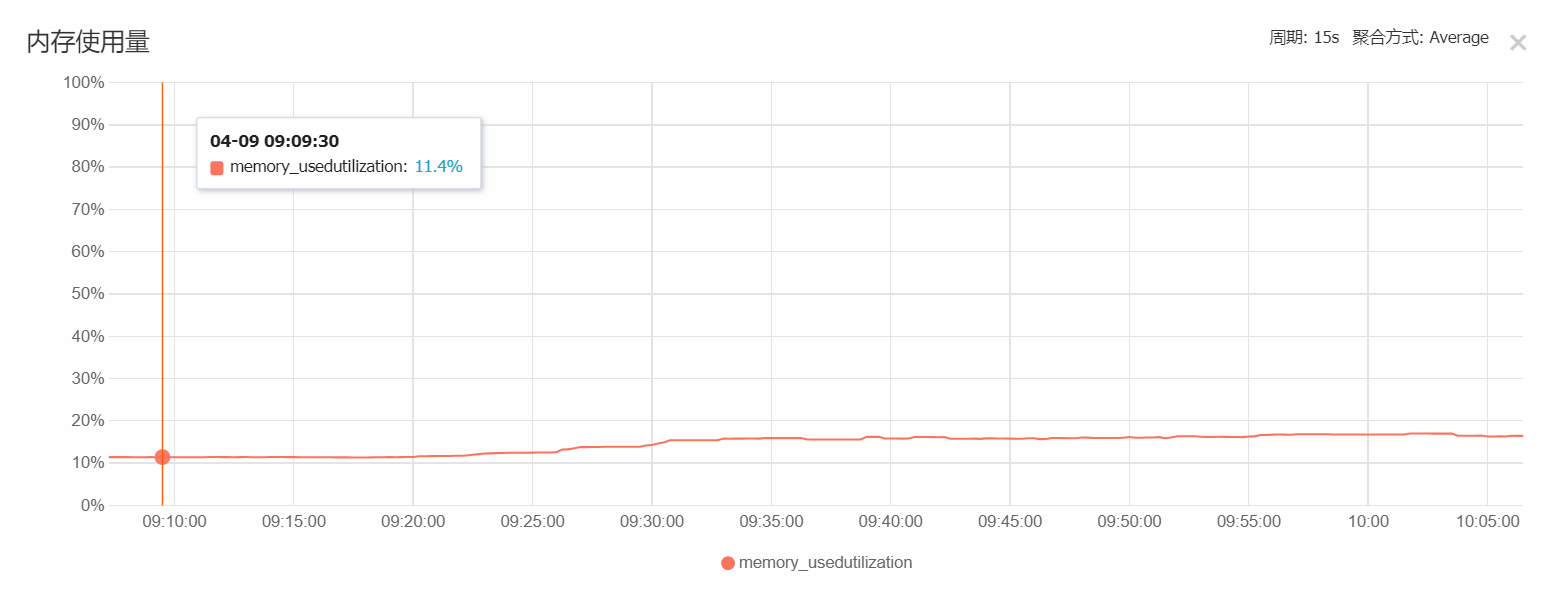
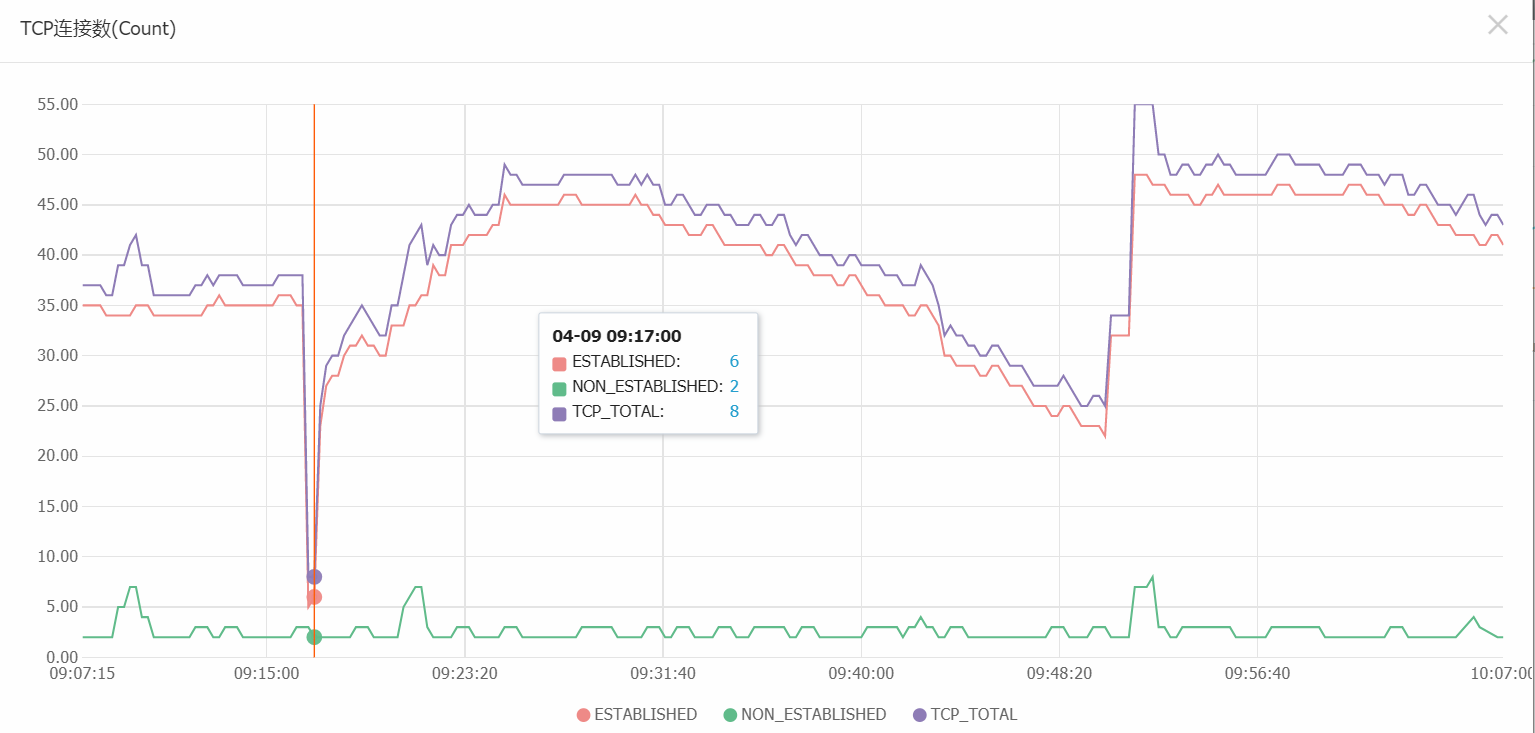
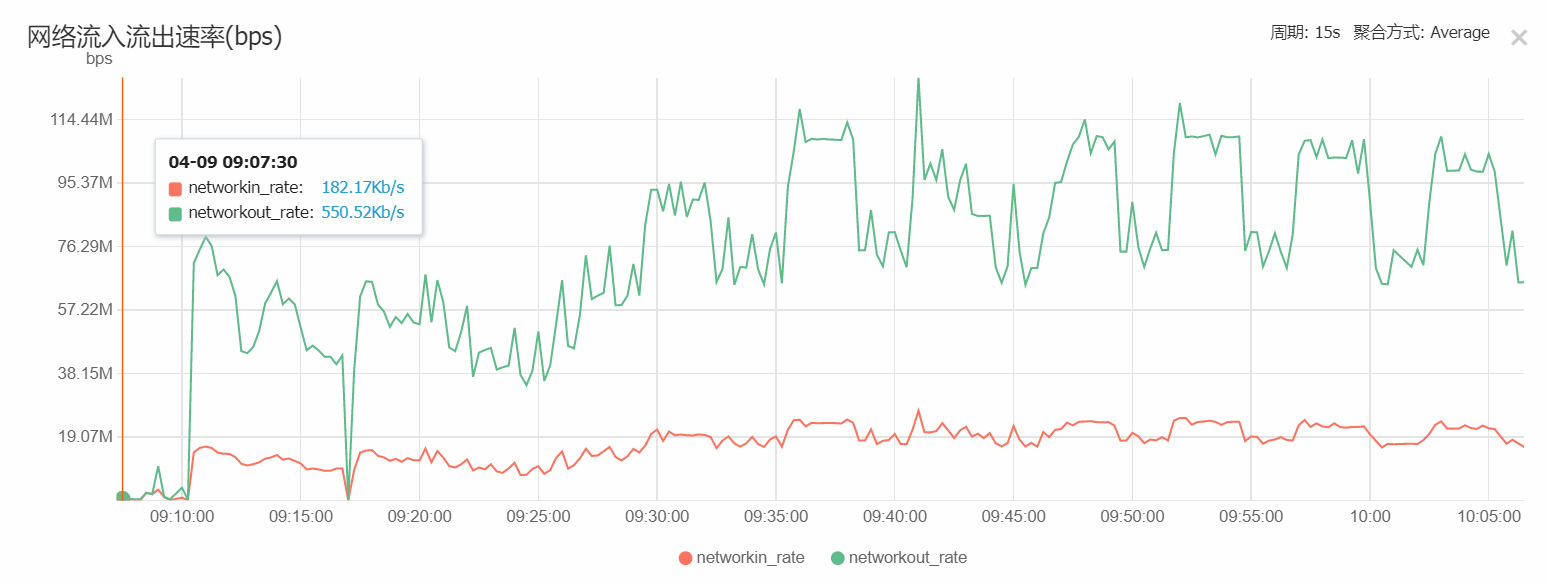
从实际的运行中可以看出,一开始10000台矿机负载时,CPU占用为100%,可以运算出正常的结果,但建了索引优化后的负载为30000台,cpu占用只有7%左右,可见运行优化的重要性。
以下为Redis配置要点,生产环境中不能使用默认配置:
- 是否转存在硬盘?转存时间间隔。
- Redis可以使用的最大内存是多少?
- 当Redis出现故障时是否停止服务?
- 当Redis达到最大内存阀值时的淘汰策略是什么?
- 如果需要转存(持久化),存储的方式是什么?
所有这些都影响Redis的可靠性和可用性,Linux中Redis的配置文件所在目录为:
/etc/Redis/Redis.conf
另外,配置完成后,检查绑定IP地址,检查端口号,检查ufw防火墙设置
集群配置参考链接:
https://www.cnblogs.com/yuanermen/p/5717885.html
https://www.cnblogs.com/wuxl360/p/5920330.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号