2023数据采集与融合技术实践第四次作业
作业①:
要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
输出信息:
MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头。
代码:
爬取信息
for link in browser.find_elements(By.XPATH,'//tbody/tr'):
count += 1
# 代码
id_stock = link.find_element(By.XPATH,'./td[position()=2]').text
# 股票名
name = link.find_element(By.XPATH,'.//td[@class="mywidth"]').text
# 价格
new_price = link.find_element(By.XPATH,'.//td[@class="mywidth2"]').text
# 涨跌幅
ud_range = link.find_element(By.XPATH,'.//td[@class="mywidth"]').text
# 涨跌额
ud_num = link.find_element(By.XPATH,'./td[position()=6]').text
# 成交量
deal_count = link.find_element(By.XPATH,'./td[position()=8]').text
# 成交额
turnover = link.find_element(By.XPATH,'./td[position()=9]').text
# 振幅
amplitude = link.find_element(By.XPATH,'./td[position()=10]').text
# 最高
high = link.find_element(By.XPATH,'./td[position()=11]').text
# 最低
low = link.find_element(By.XPATH,'./td[position()=12]').text
# 今开
today = link.find_element(By.XPATH,'./td[position()=13]').text
# 昨收
yesterday = link.find_element(By.XPATH,'./td[position()=14]').text
# 插入数据
stockdb.insert(count, id_stock, name, new_price, ud_range, str(ud_num), deal_count, turnover, amplitude, high, low,
today, yesterday)
实现翻页
str = ['hs', 'sh', 'sz']
for i in str:
item = browser.find_element(By.XPATH, '//li[@id="nav_'+i+'_a_board"]')
#print(item)
item.click()
初始化数据库
class stockDB:
def openDB(self):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
except:
self.cursor.execute("delete from stocks")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday):
try:
self.cursor.execute("insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday))
except Exception as err:
print(err)
输出结果:
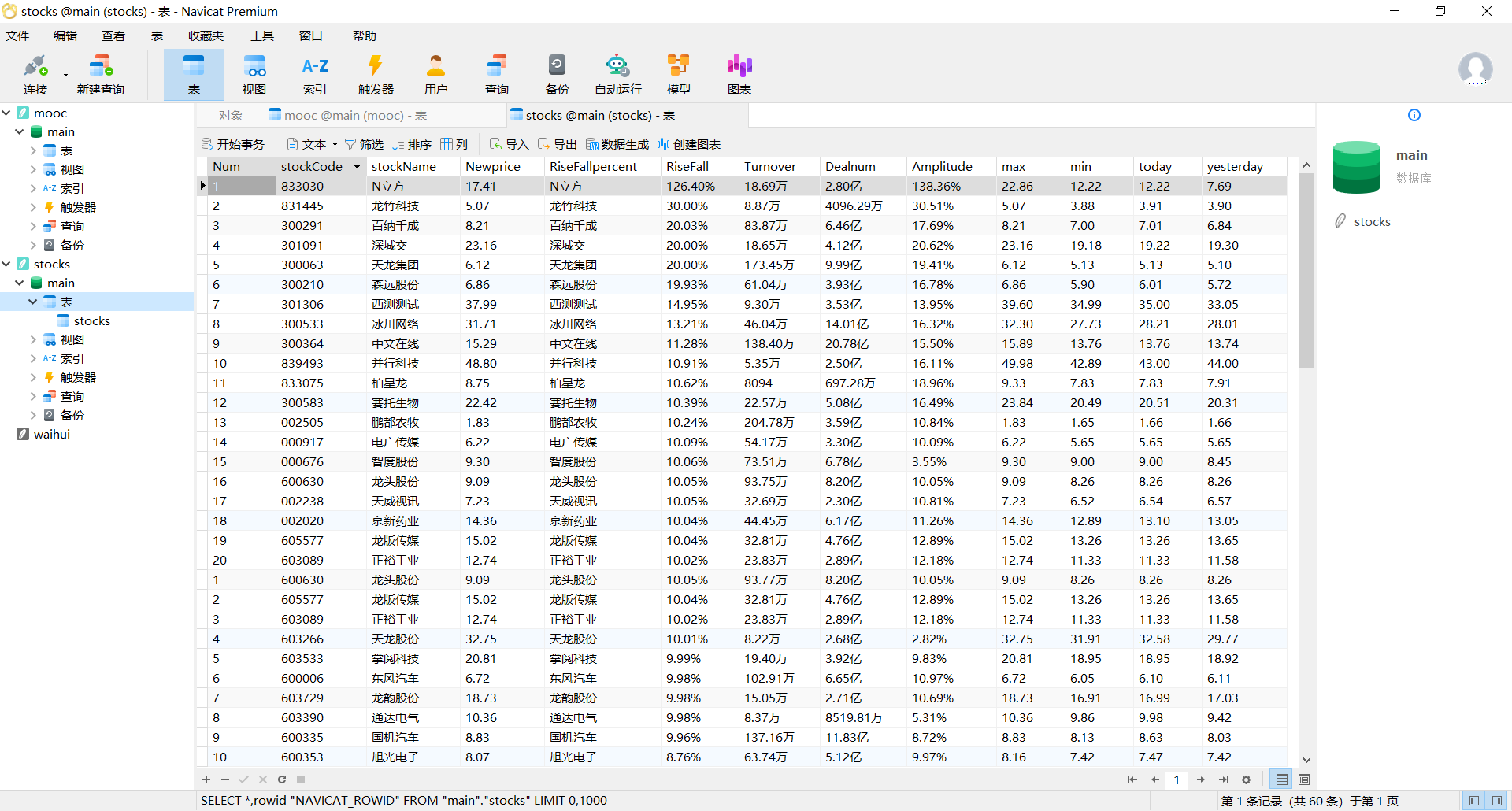
心得和体会:
第一个实验相对简单,关键点在于找到每个数据,并写出正确的xpath表达式。还有注意打开网页后要设置等待一会,不然网页资源还没有加载出来,可能会爬取失败。
作业②:
要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
输出信息:
MYSQL 数据库存储和输出格式
代码:
爬取信息
for link in browser.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
count += 1
try:
name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
except Exception as err:
name = 'none'
try:
school = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
except Exception as err:
school = 'none'
try:
teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
except Exception as err:
teacher = 'none'
try:
team = link.find_element(By.XPATH, './/span[@class="f-fc9"]').text
except Exception as err:
team = 'none'
try:
person = link.find_element(By.XPATH, './/span[@class="hot"]').text
except Exception as err:
person = 'none'
try:
jindu = link.find_element(By.XPATH, './/span[@class="txt"]').text
except Exception as err:
jindu = 'none'
try:
jianjie = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
except Exception as err:
jianjie = 'none'
moocdb.insert(count, name, school, teacher, team, person, jindu, jianjie)
登录
def login():
login = browser.find_element(By.XPATH,'//a[@class="f-f0 navLoginBtn"]')
login.click()
frame = browser.find_element(By.XPATH,'//div[@class="ux-login-set-container"]/iframe')
browser.switch_to.frame(frame)
inputUserName = browser.find_element(By.XPATH,'//div[@class="u-input box"][1]/input')
inputUserName.send_keys("")
inputPasswd = browser.find_element(By.XPATH,'//div[@class="inputbox"]/div[2]/input[2]')
inputPasswd.send_keys("")
LoginButton = browser.find_element(By.XPATH,'//*[@id="submitBtn"]')
LoginButton.click()
time.sleep(5)
翻页
def next():
nextpage= browser.find_element(By.XPATH,'//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
nextpage.click()
初始化数据库
class moocDB:
def openDB(self):
self.con = sqlite3.connect("mooc.db")
self.cursor = self.con.cursor()
try: #count, name, school, teacher, team, person, jindu, jianjie
self.cursor.execute("create table mooc (Num varchar(16), Name varchar(16),School varchar(16),Teacher varchar(16),Team varchar(16),Person varchar(16),Jindu varchar(16),Jianjie varchar(16))")
except:
self.cursor.execute("delete from mooc")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,count, name, school, teacher, team, person, jindu, jianjie):
try:
self.cursor.execute("insert into mooc(Num,Name,School,Teacher,Team,Person,Jindu,Jianjie) values (?,?,?,?,?,?,?,?)",
(count, name, school, teacher, team, person, jindu, jianjie))
except Exception as err:
print(err)
输出结果:
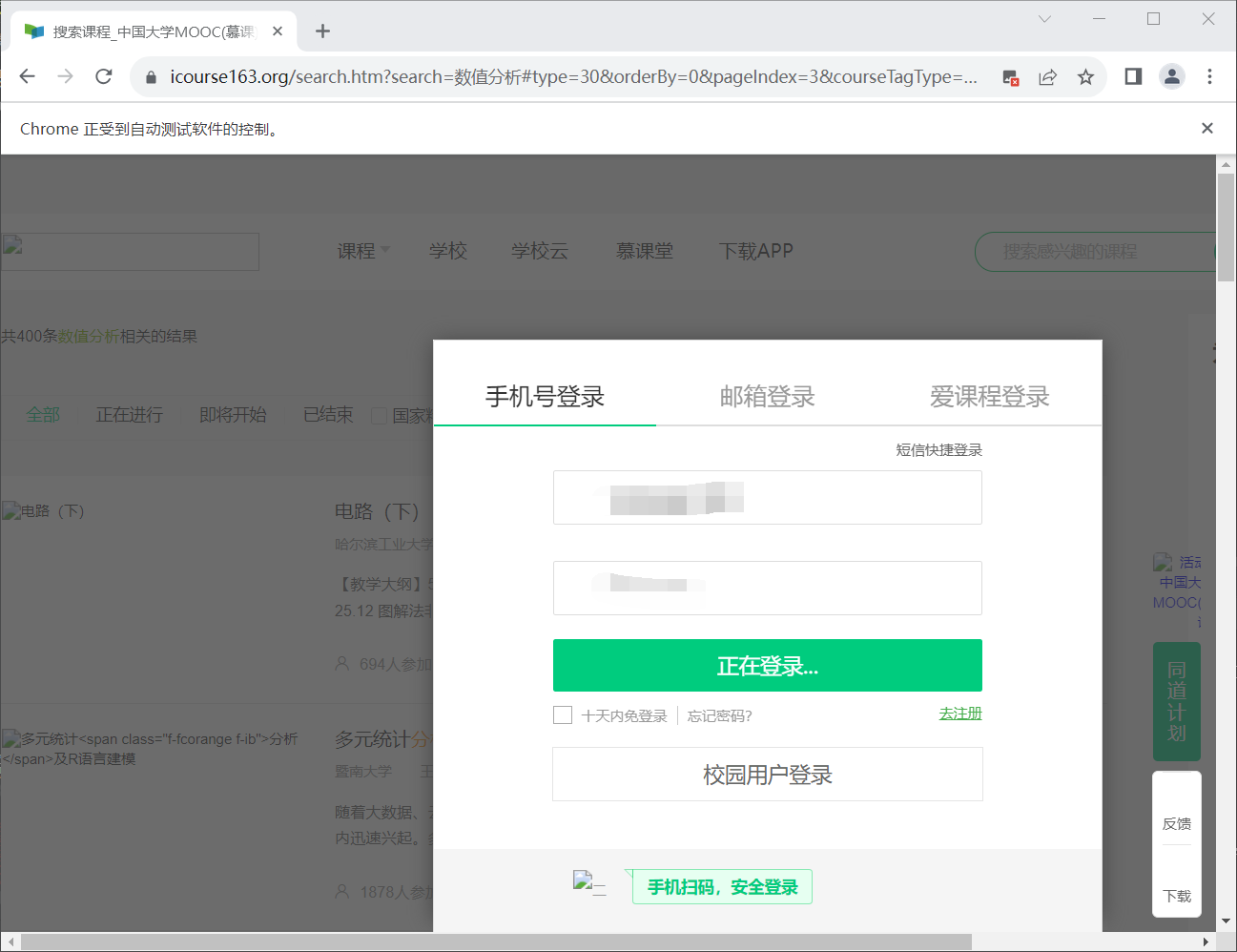

心得和体会:
一开始爬取数据的时候,如果直接复制网页元素的XPATH,是这样的//*[@id="auto-id-1699413824559"],但是爬取的时候总是找不到元素。后面查了才知道id属性是每次刷新都会变化的,所以不能通过这个来查找元素。
登录时,总是查找不到输入框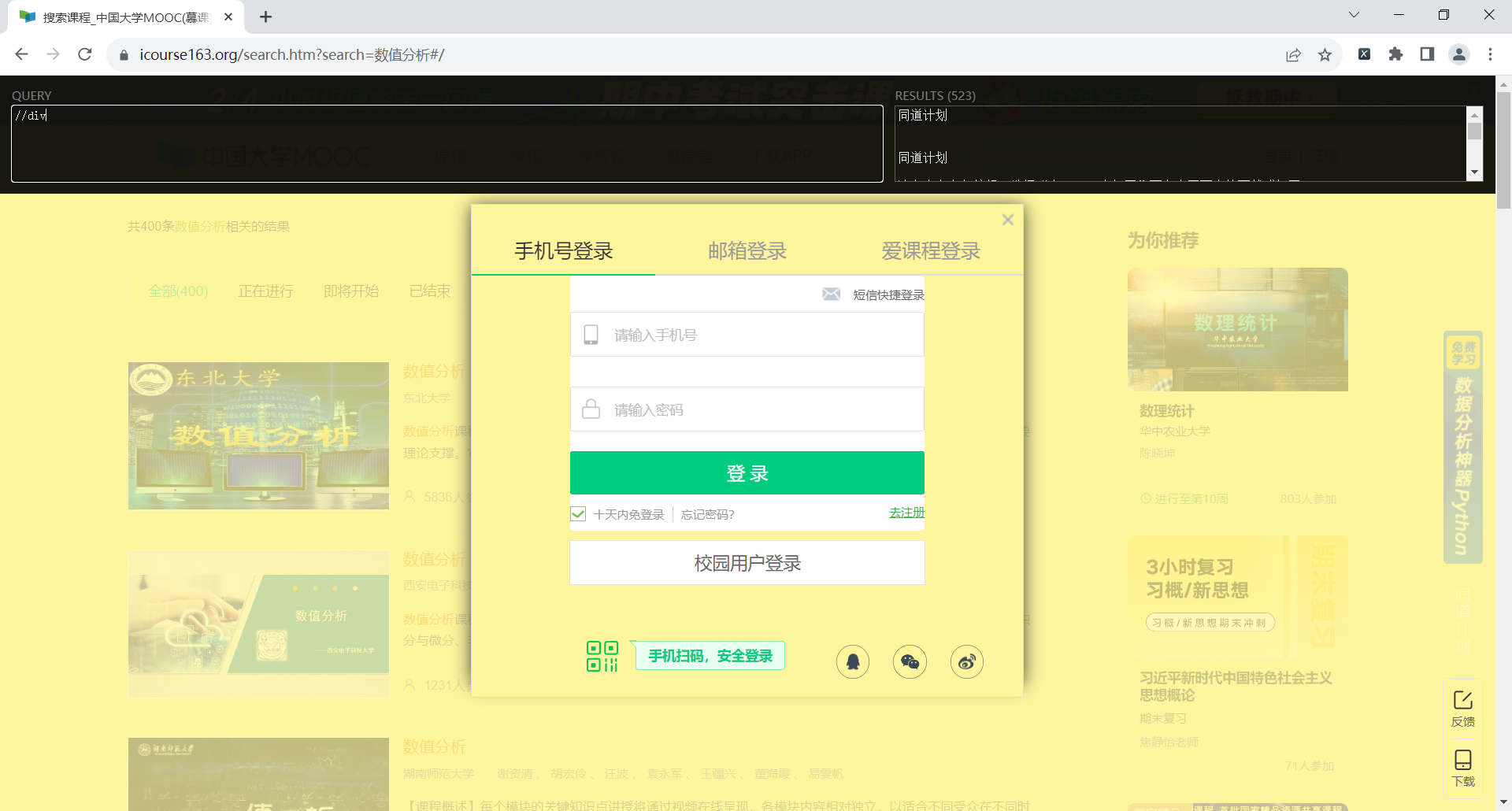
查看源代码发现是登录框被隐藏在新加载的ifame里了
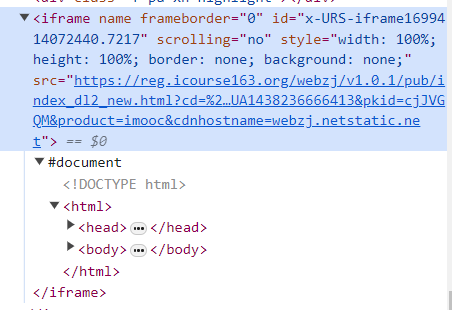
此时需要切换一下:
frame = browser.find_element(By.XPATH,'//div[@class="ux-login-set-container"]/iframe')
browser.switch_to.frame(frame)
但是不知道为什么,登录的函数执行后总是自动把浏览器关掉,所以只能把登录放在最后了。
在爬取信息的过程中,一些课程可能没有学校、没有团队、没有课程进度等,就会直接报错找不到元素,因此给每条语句都加上了try-except语句,将找不到的直接设置为none,保证代码的继续执行。
插入数据库是拿着上一题的代码改的,但是表总是空的,百思不得其解,后面去重新检查才发现改了创建表的表名,忘记改插入表的表名了。。。。

作业③:
要求:
掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
输出信息:
实验关键步骤或结果截图。
环境搭建:
任务一:开通 MapReduce 服务
申请集群

配置安全组

实时分析开发实战:
任务一:Python 脚本生成测试数据
使用Xshell 7连接服务器:
进入/opt/client/目录,编写Python脚本autodatapython.py

创建目录


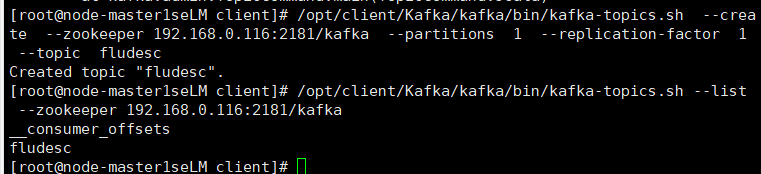
任务二:配置 Kafka

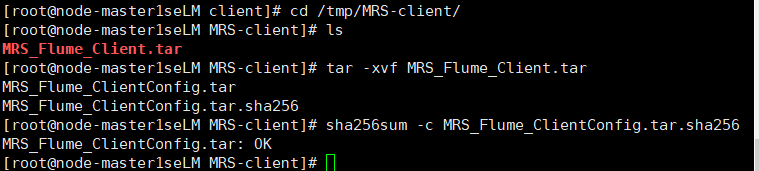
任务三: 安装 Flume 客户端
解压下载的flume客户端文件,校验文件包
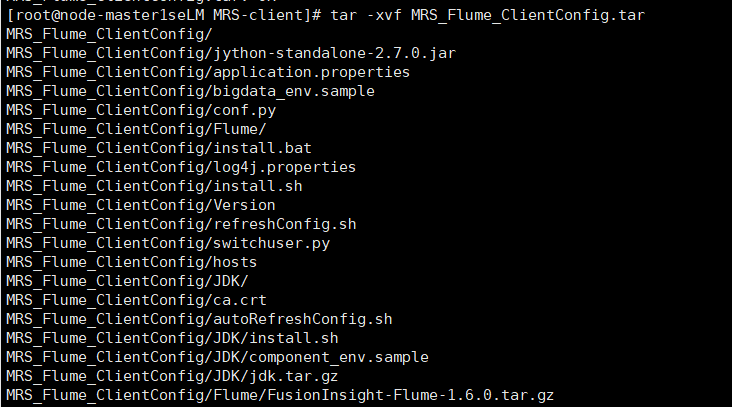
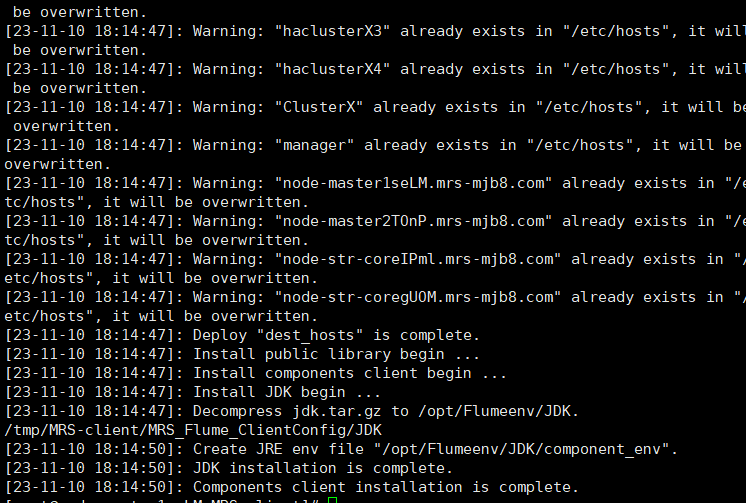
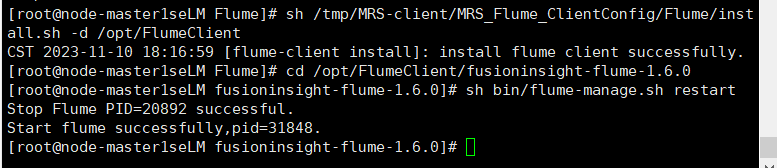
安装Flume客户端

重启Flume服务
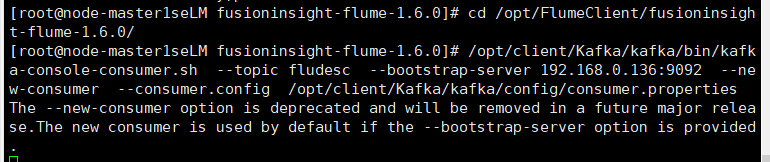
任务四:配置 Flume 采集数据

心得和体会:
跟着实验手册做就没什么问题,但是一开始以为华为云资源只要不开启就不会扣费,结果是从买下开始就在计费。。。结果被扣了好多钱,心累
码云链接
本文作者:yyiiing
本文链接:https://www.cnblogs.com/yyiiing/p/17816889.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步