2023数据采集与融合技术实践第三次作业
作业①:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码:
单线程
MySpider.py
class MySpider(scrapy.Spider):
name = 'MySpider'
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
src = response.xpath('//img/@src').extract()
img = Work1Item(src=src)
yield img
pipelines.py
class Work1Pipeline2:
def process_item(self,item,spider):
urls = item.get('src')
num = 1
for url in urls:#遍历图片并保存
filename = 'D:/DATASET/images/' + str(num) + '.jpg'
print('第'+str(num)+'张图片:'+url)
urllib.request.urlretrieve(url=url,filename=filename)
num+=1
return item
settings.py
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
IMAGES_STORE = r'D:\DATASET\images'
ITEM_PIPELINES = {
'work1.pipelines.Work1Pipeline2': 300,
}
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36',
}
多线程
在MySpider.py加上如下语句
def __init__(self, *args, **kwargs):
super(MySpider, self).__init__(*args, **kwargs)
self.executor = ThreadPoolExecutor(max_workers=4)
def process_request(self, request, spider):
# 利用线程池异步发送请求
self.executor.submit(spider.crawler.engine.download, request, spider)
在settings.py加上如下语句
DOWNLOAD_DELAY = 0
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
COOKIES_ENABLED = False
输出结果:
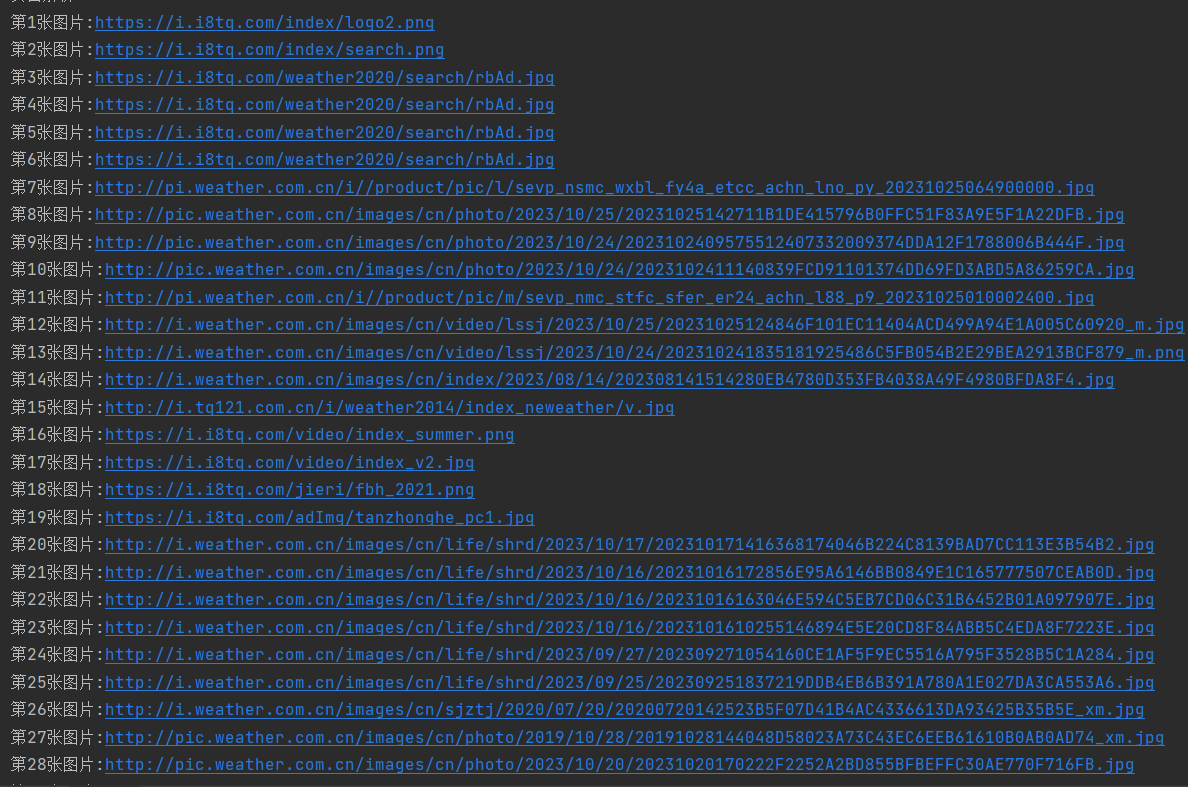
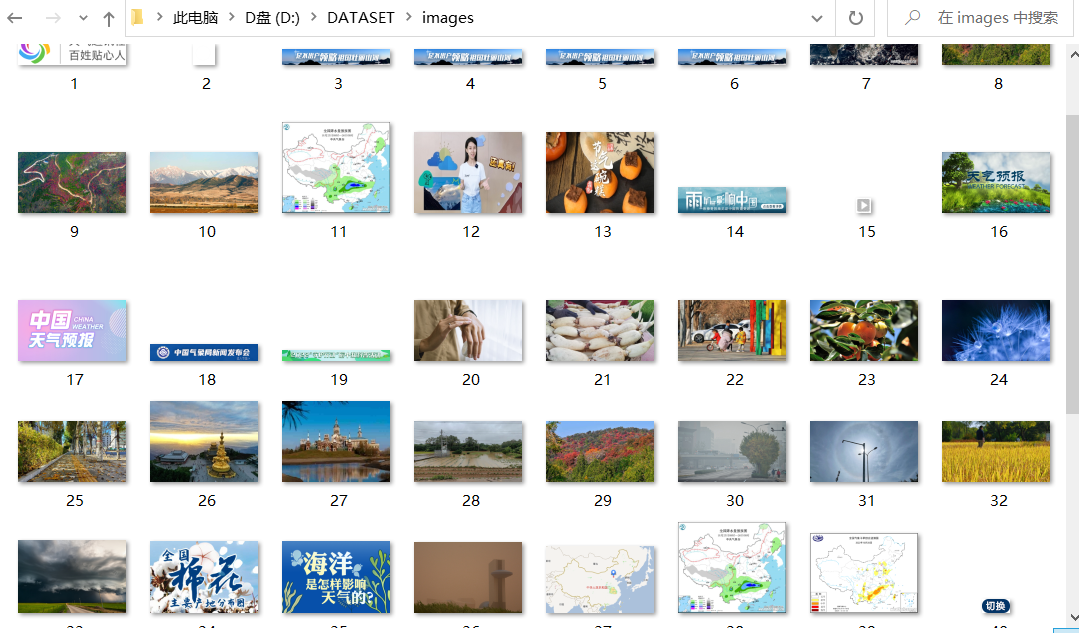
由于天气网整个页面只有48张图片,于是爬取亚马逊网站
代码:
MySpider.py(有修改的部分)
for i in range(1,3):#学号后两位是02,于是爬取两页
url = f"https://www.amazon.cn/s?k=%E4%B9%A6%E5%8C%85&page={i}&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&crid=1RAID9NTPCARM&qid=1698238172&sprefix=%E4%B9%A6%E5%8C%85%2Caps%2C154&ref=sr_pg_{i}"
start_urls.append(url)
def parse(self, response):
src = response.xpath('//img/@src').extract()
#print(src)
img = Work1Item(src=src)
yield img
pipelines.py
class Work1Pipeline2:
def __init__(self):
self.counter=1
def process_item(self,item,spider):
urls = item.get('src')
urls.pop()#去除最后一个元素
urls.pop(0)#去除第一个元素
#print(urls)
for url in urls:
filename = 'D:/DATASET/images/' + str(self.counter) + '.jpg'
print('第'+str(self.counter)+'张图片:'+url)
urllib.request.urlretrieve(url=url,filename=filename)
self.counter+=1
if(self.counter>102):#学号后三位是102,于是爬取102张图片
break
return item
输出结果:
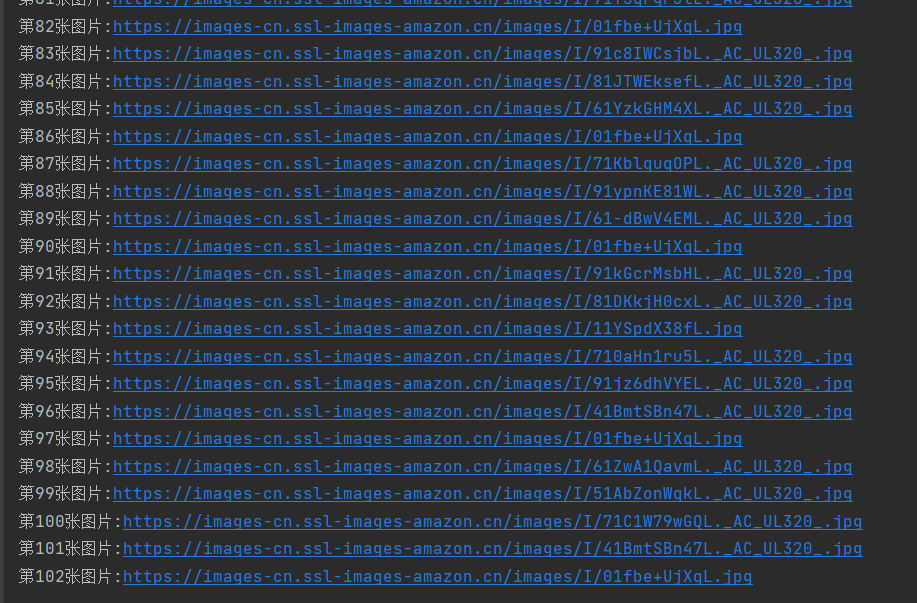
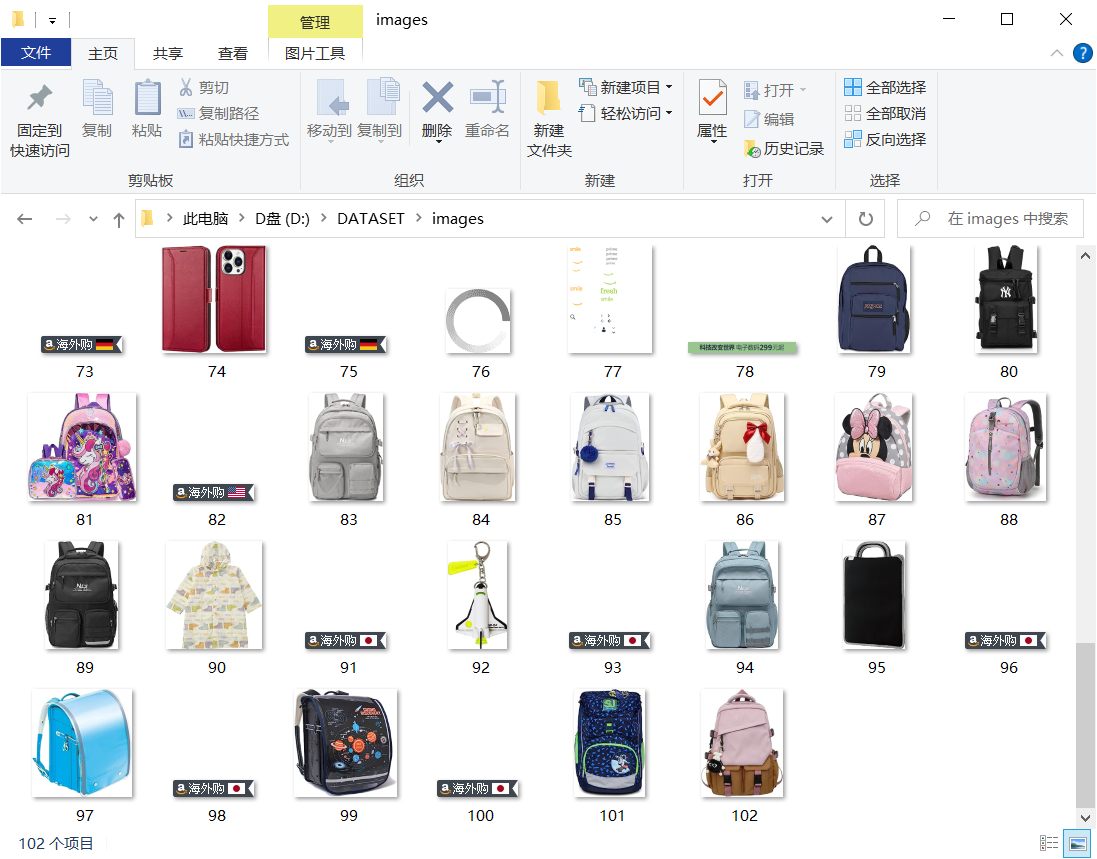
心得和体会:
爬取天气网时,一开始使用正则表达式抓取图片的url,传输的数据类型在pipelines中下载的时候总是失败,即使用了循环,参数也还是一整个列表。于是转用xpath就便捷很多,可以使用xpath工具判断是否抓取成功。
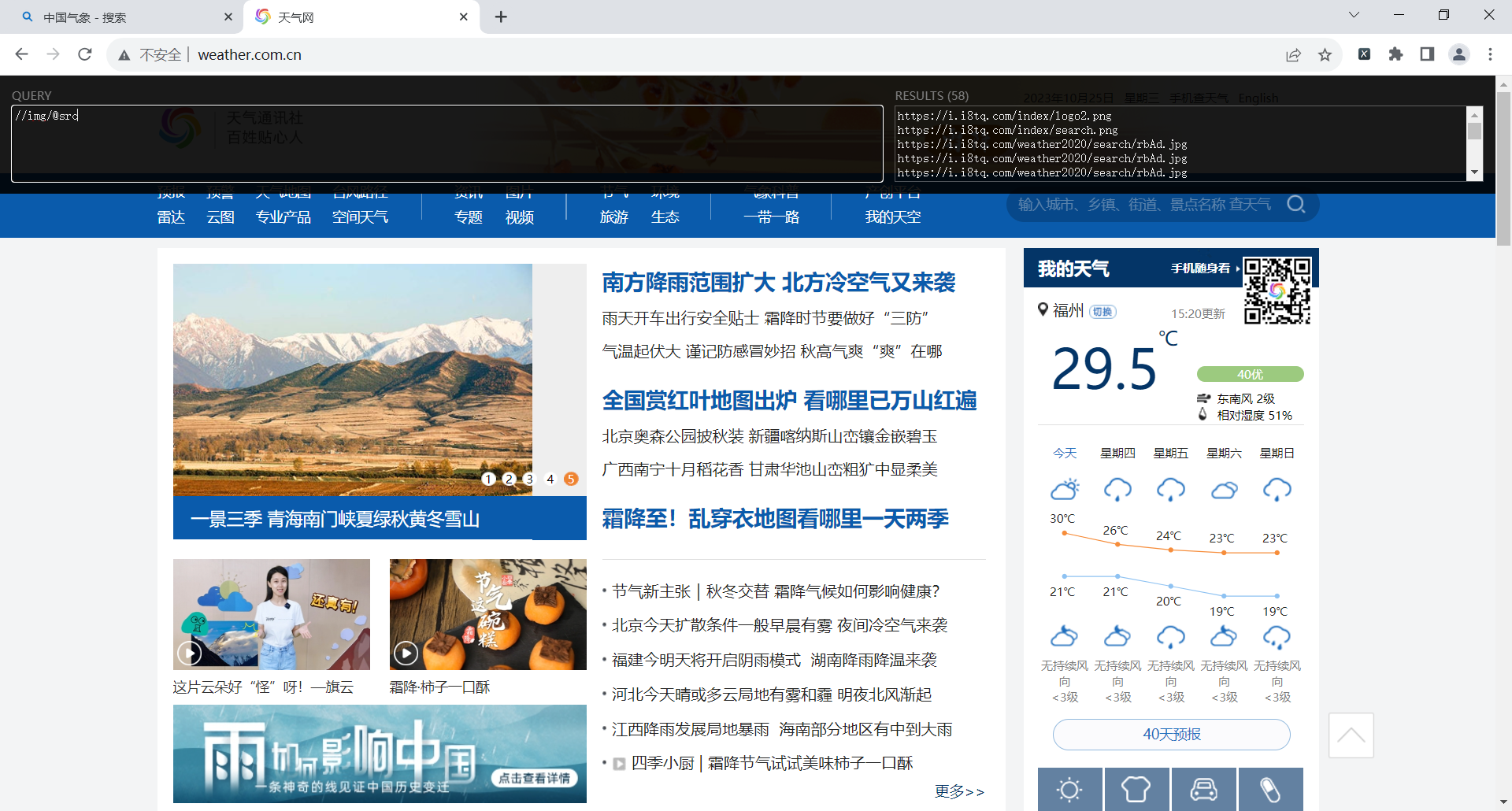
爬取亚马逊网站时,在网页使用插件查找xpath是正确的图片的url,但是在本地运行时第一个元素和最后一个元素很奇怪
于是使用了pop函数去除这两个元素
在第一个代码里直接在循环中定义num在亚马逊网站中不可取,因为翻页过后会重新调用process_item函数,num又会从1开始计数。于是定义了self.counter进行计数。
作业②:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:
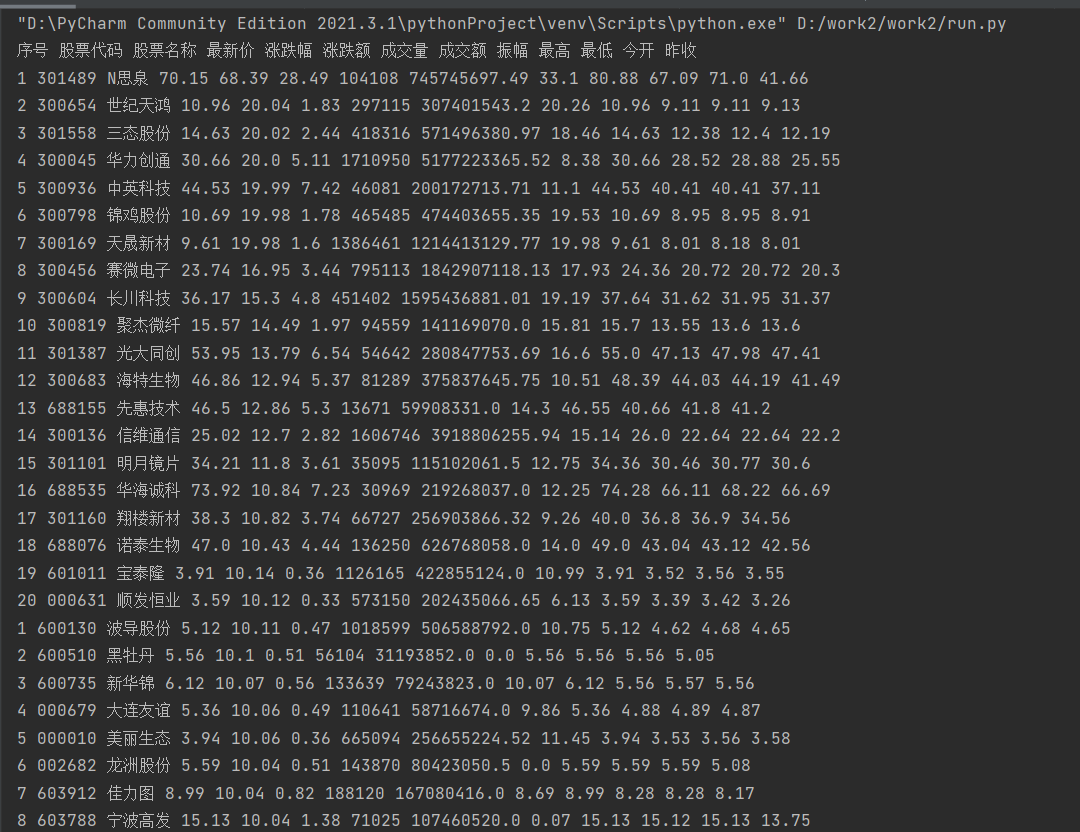
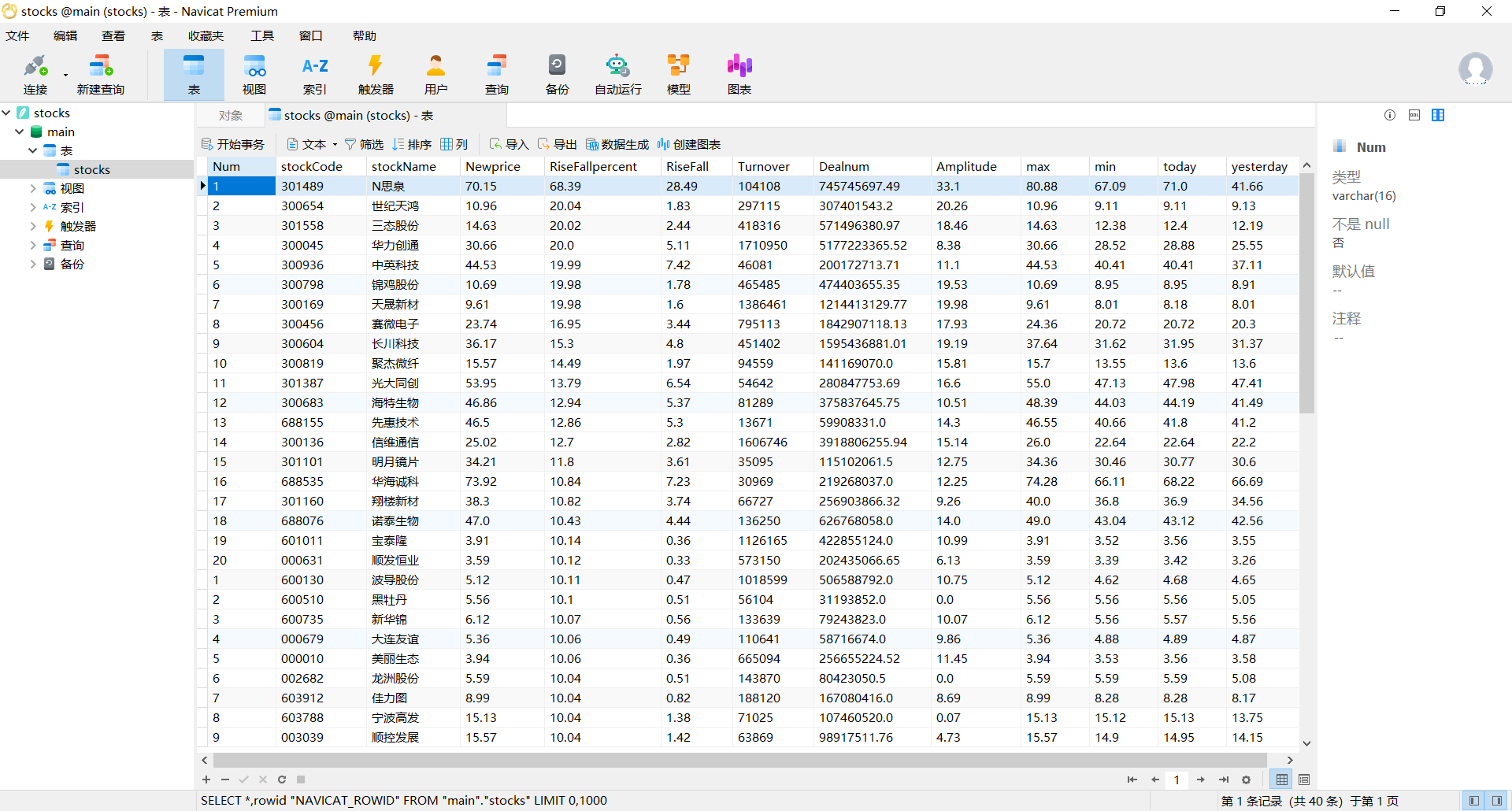
MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
2……
代码:
MySpider.py
class MySpider(scrapy.Spider):
name = 'MySpider'
start_urls = []
for i in range(1,3):
url =f"http://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124030395806868839914_1696659472380&pn={i}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696659472381"
start_urls.append(url)
global num
print("序号", "股票代码", "股票名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收", chr(12288))
def getContent(html):
stocks = re.findall("\"diff\":\[(.*?)]", html)
print(stocks)
stocks = list(eval(stocks[0]))
print(stocks)
num = 0
result = []
for stock in stocks:
num += 1
daima = stock["f12"]
name = stock["f14"]
newprice = stock["f2"]
diefu = stock["f3"]
dieer = stock["f4"]
chengjiaoliang = stock["f5"]
chengjiaoer = stock["f6"]
zhenfu = stock["f7"]
max = stock["f15"]
min = stock["f16"]
today = stock["f17"]
yesterday = stock["f18"]
result.append(
[num, daima, name, newprice, diefu, dieer, chengjiaoliang, chengjiaoer, zhenfu, max, min, today,
yesterday])
#print(result)
return result
def parse(self, response):
stockdb = Work2Pipeline() # 创建数据库对象
stockdb.openDB(MySpider) # 开启数据库
html = response.text
stocks = MySpider.getContent(html)
print(stocks)
for stock in stocks:
item = Work2Item()
item['Num'] = stock[0]
item['daima'] = stock[1]
item['name']= stock[2]
item['newprice']= stock[3]
item['diefu']=stock[4]
item['dieer']=stock[5]
item['chengjiaoliang']=stock[6]
item['chengjiaoer']=stock[7]
item['zhenfu']=stock[8]
item['max']=stock[9]
item['min']=stock[10]
item['today']=stock[11]
item['yesterday']=stock[12]
print(stock[0], stock[1], stock[2], stock[3], stock[4], stock[5], stock[6], stock[7], stock[8],stock[9], stock[10], stock[11], stock[12], chr(12288))
stockdb.process_item(item,MySpider)
yield item
pipelines.py
class Work2Pipeline:
def openDB(self,spider):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table if not exists stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
except:
self.cursor.execute("delete from stocks")
def process_item(self, item, spider):#插入数据
sql = "insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
params=list()
params.append(item['Num'])
params.append(['daima'])
params.append(item['name'])
params.append(item['newprice'])
params.append(item['diefu'])
params.append(item['dieer'])
params.append(item['chengjiaoliang'])
params.append(item['chengjiaoer'])
params.append(item['zhenfu'])
params.append(item['max'])
params.append(item['min'])
params.append(item['today'])
params.append(item['yesterday'])
self.cursor.execute(sql,tuple(params))
self.con.commit()
return item
def closeDB(self,spider):
self.con.commit()
self.con.close()
输出结果:
心得和体会:
这次试验和前一次做的差不多,因为网站是采用动态加载的,所以需要通过抓包获取资源。难点在于如何在scrapy框架下将数据存入数据库。
和前一次实验比较不一样的地方:
1、pipelines.py中定义创建数据库和关闭数据库的函数需要传入参数spider
2、process_item函数(其实就是插入数据)需要传入数据封装后的item和spider
一开始使用
sql = "insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql % (item['Num'],item['daima'],item['name'],item['newprice'],item['diefu'],item['dieer'],item['chengjiaoliang'],item['chengjiaoer'],item['zhenfu'],item['max'],item['min'],item['today'],item['yesterday']))
会报错TypeError: not all arguments converted during string formatting
查询后是因为:%操作符只能直接用于字符串(‘123’),列表([1,2,3])、元组。
于是将函数修改为:(需要注意params添加的顺序要和sql语句插入的顺序一致,否则会出现错位甚至插入失败的情况)
sql = "insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
params=list()
params.append(item['Num'])
params.append(['daima'])
params.append(item['name'])
params.append(item['newprice'])
params.append(item['diefu'])
params.append(item['dieer'])
params.append(item['chengjiaoliang'])
params.append(item['chengjiaoer'])
params.append(item['zhenfu'])
params.append(item['max'])
params.append(item['min'])
params.append(item['today'])
params.append(item['yesterday'])
self.cursor.execute(sql,tuple(params))
self.con.commit()
就可以正确把数据插入数据库了。
一开始控制台经常没有输出,检查后发现parse函数都没有进入,其实可能是一些书写有问题,可以在run.py中将LOG_ENABLED=False设置为True,以便排查错误。parse函数里有任何错误都可能导致整个函数没有输出。
作业③:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
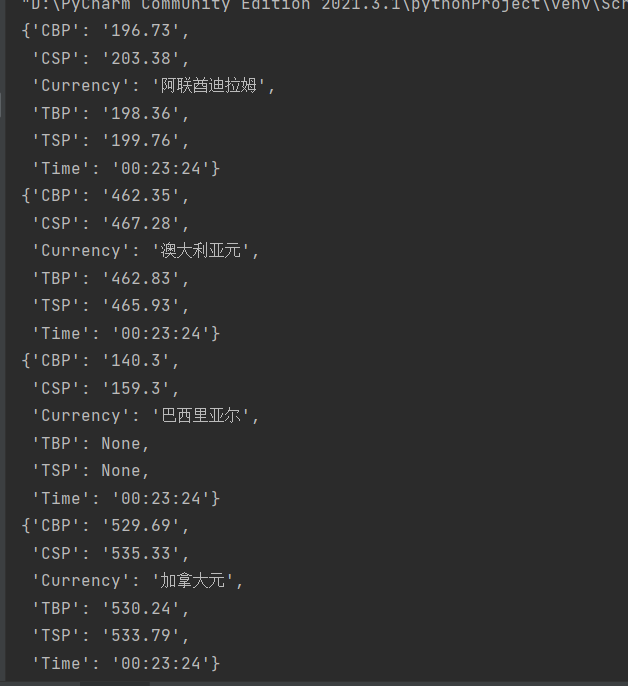
输出信息:
Currency TBP CBP TSP CSP Time
阿联酋迪拉姆 198.58 192.31 199.98 206.59 11:27:14
代码:
MySpider.py
class MySpider(scrapy.Spider):
name = 'MySpider'
start_urls =["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
waihuidb = Work3Pipeline() # 创建数据库对象
waihuidb.openDB(MySpider) # 开启数据库
items = response.xpath('//tr[position()>1]')
for i in items:
item = Work3Item()
item['Currency'] = i.xpath('.//td[1]/text()').get()
item['TBP'] = i.xpath('.//td[2]/text()').get()
item['CBP']= i.xpath('.//td[3]/text()').get()
item['TSP']= i.xpath('.//td[4]/text()').get()
item['CSP']=i.xpath('.//td[5]/text()').get()
item['Time']=i.xpath('.//td[8]/text()').get()
print(item)
waihuidb.process_item(item,MySpider)
yield item
pipelines.py
class Work3Pipeline:
def openDB(self,spider):
self.con = sqlite3.connect("waihui.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table if not exists waihui (Currency varchar(16), TBP varchar(16),CBP varchar(16),TSP varchar(16),CSP varchar(16),Time varchar(16))")
except:
self.cursor.execute("delete from waihui")
def process_item(self, item, spider):
sql = "insert into waihui(Currency,TBP,CBP,TSP,CSP,Time) values (?,?,?,?,?,?)"
params=list()
params.append(item['Currency'])
params.append(item['TBP'])
params.append(item['CBP'])
params.append(item['TSP'])
params.append(item['CSP'])
params.append(item['Time'])
self.cursor.execute(sql,tuple(params))
self.con.commit()
return item
def closeDB(self,spider):
self.con.commit()
self.con.close()
输出结果:
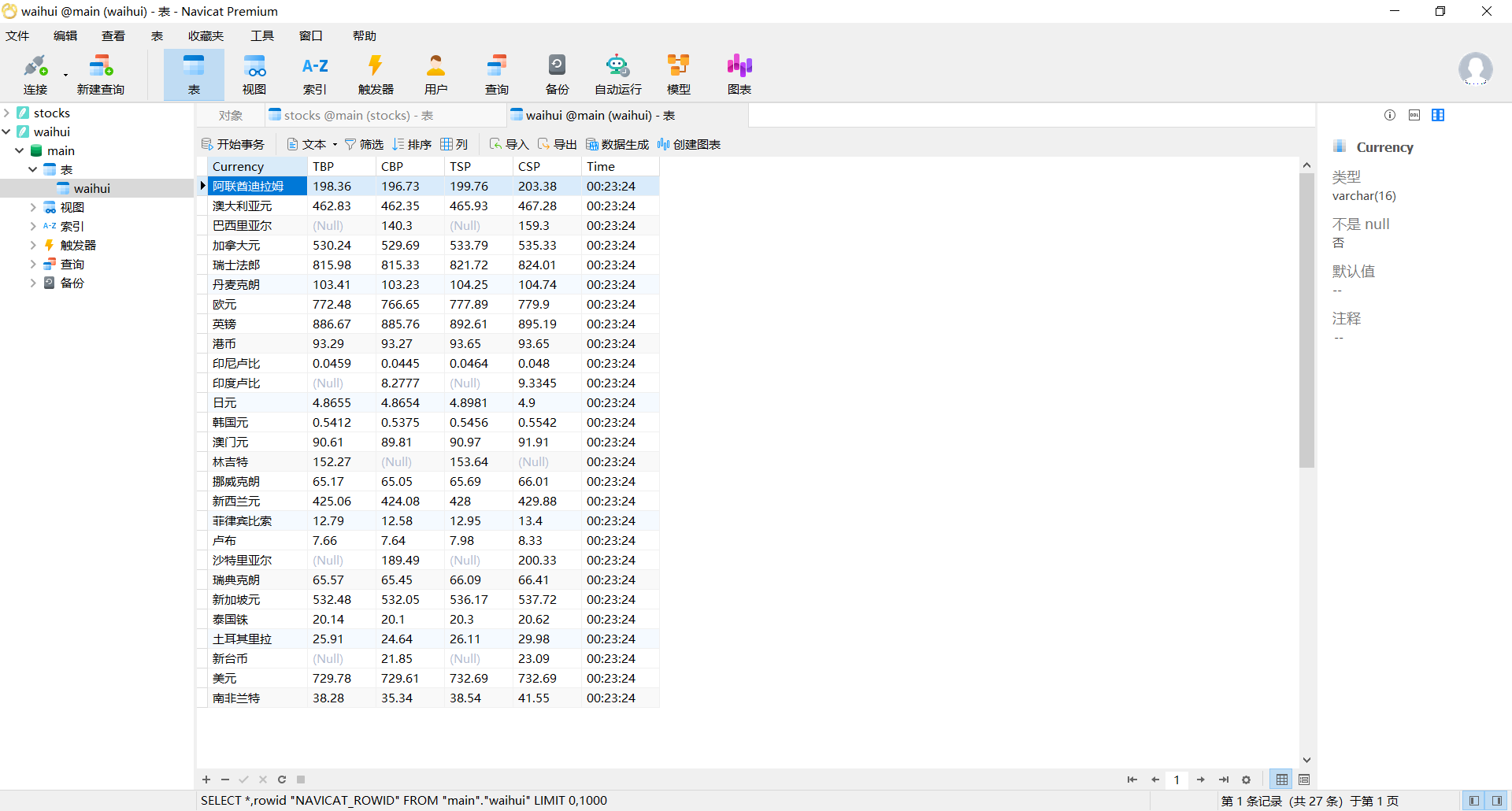
心得和体会:
本实验和第二个实验差不多,但是在这个实验里强化了xpath的使用,需要注意的是可以打开LOG_ENABLED,以免因为xpath写错而导致没有输出结果。
码云链接
本文作者:yyiiing
本文链接:https://www.cnblogs.com/yyiiing/p/17786128.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步