2023数据采集与融合技术实践第二次作业
作业①:
要求:
在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
代码:
核心程序
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")#找到每个单元格
for li in lis:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
if li == lis[0]:#当天气是今天时特殊处理
temp = li.select('p[class="tem"] i')[0].text
else:
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
初始化数据库
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
输出结果:


心得和体会:
时间为当天20:53分时,运行原本的程序报错
点进网页发现今天的天气数据有变化!!!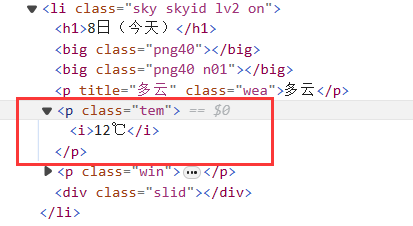
对比其他日期,发现少了一个最高温,也许是当前气温(

于是对今天的气温加了一个特殊判别,就不会报错了。
第一个实验还较为简单,跟之前的操作方法差不多,只需要加上连接数据库的部分就可以了。
作业②:
要求:
用requests和json解析方法爬取股票相关信息。
代码:
核心程序
def getContent(html):
stocks = re.findall("\"diff\":\[(.*?)]",html)
#print(stocks)
stocks = list(eval(stocks[0]))
#print(stocks)
num = 0
result = []
for stock in stocks:
num += 1
daima = stock["f12"]
name = stock["f14"]
newprice = stock["f2"]
diefu = stock["f3"]
dieer = stock["f4"]
chengjiaoliang = stock["f5"]
chengjiaoer = stock["f6"]
zhenfu = stock["f7"]
max = stock["f15"]
min = stock["f16"]
today = stock["f17"]
yesterday = stock["f18"]
result.append([num,daima,name,newprice,diefu,dieer,chengjiaoliang,chengjiaoer,zhenfu,max,min,today,yesterday])
return result
实现翻页和存数据进数据库
for page in range(1,3):
url = "http://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124030395806868839914_1696659472380&pn=" + str(page)+ "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696659472381"
html = getHtml(url)
stocks = getContent(html)
for stock in stocks:
print(s.format(stock[0],stock[1],stock[2],stock[3],stock[4],stock[5],stock[6],stock[7],stock[8],stock[9],stock[10],stock[11],stock[12],chr(12288)))
stockdb.insert(stock[0],stock[1],stock[2],stock[3],stock[4],stock[5],stock[6],stock[7],stock[8],stock[9],stock[10],stock[11],stock[12])#存入数据库
初始化数据库
class stockDB:
def openDB(self):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
except:
self.cursor.execute("delete from stocks")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday):
try:
self.cursor.execute("insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday))
except Exception as err:
print(err)
输出结果:
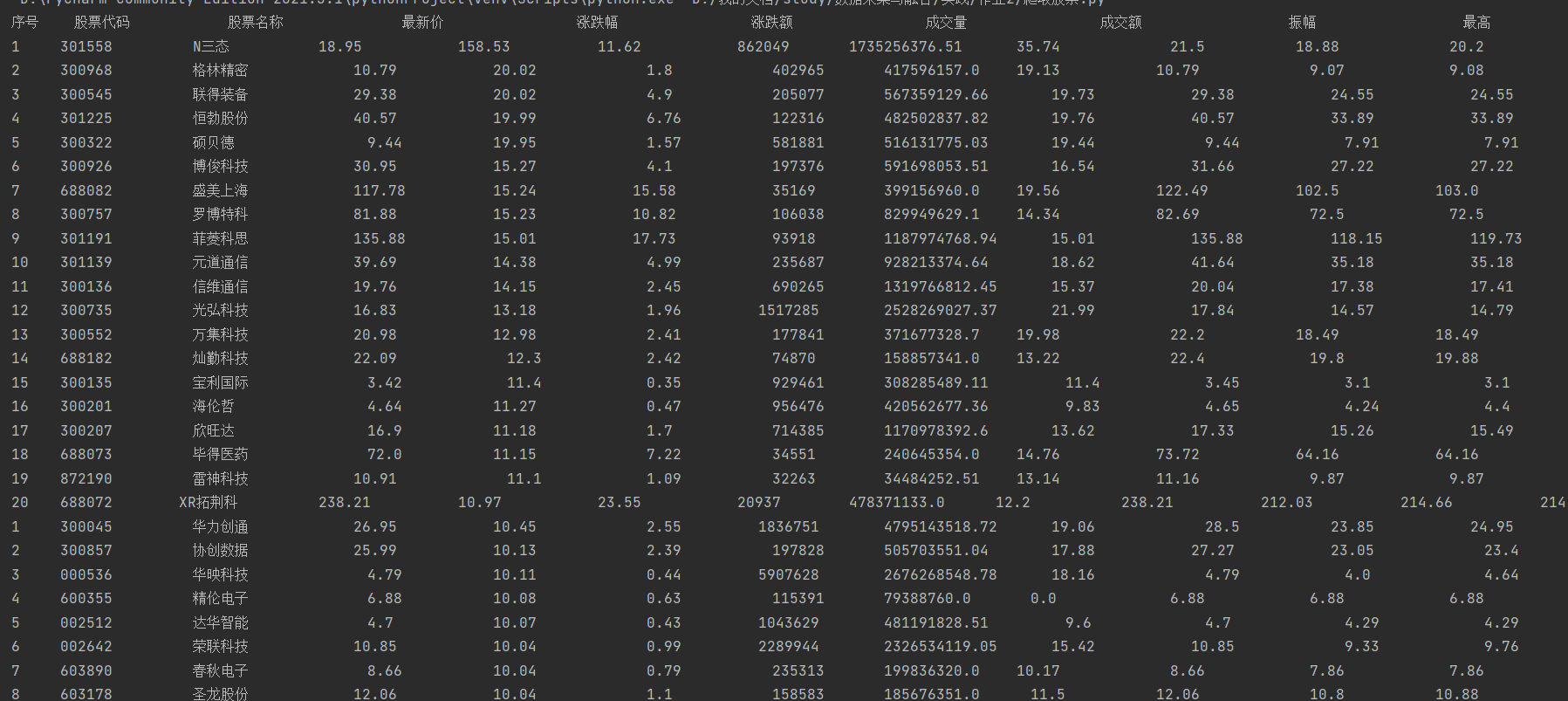

心得和体会:
本实验跟前一个实验大体上差不多,难点在于找到js包
作业③:
要求:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)
所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
GIF:
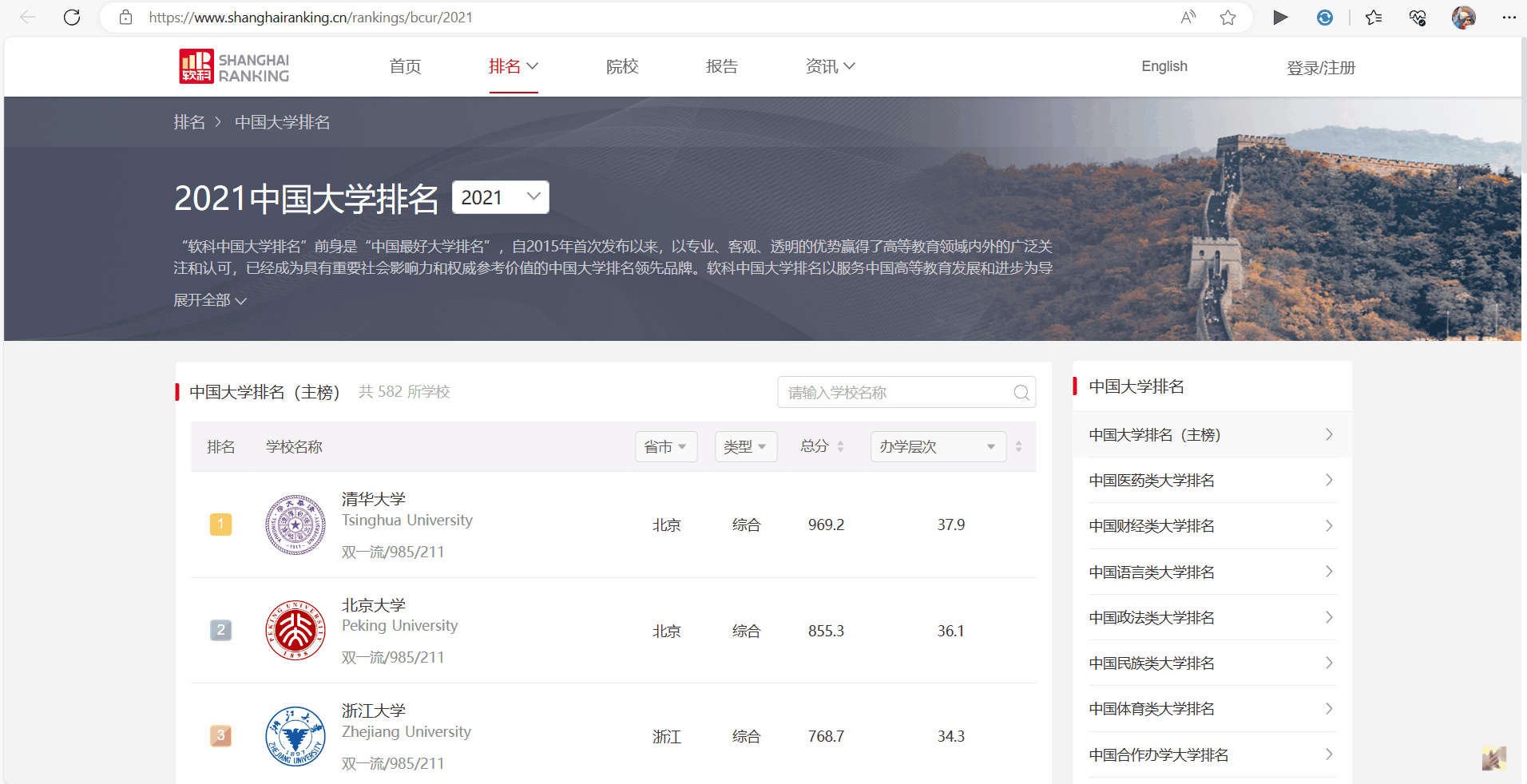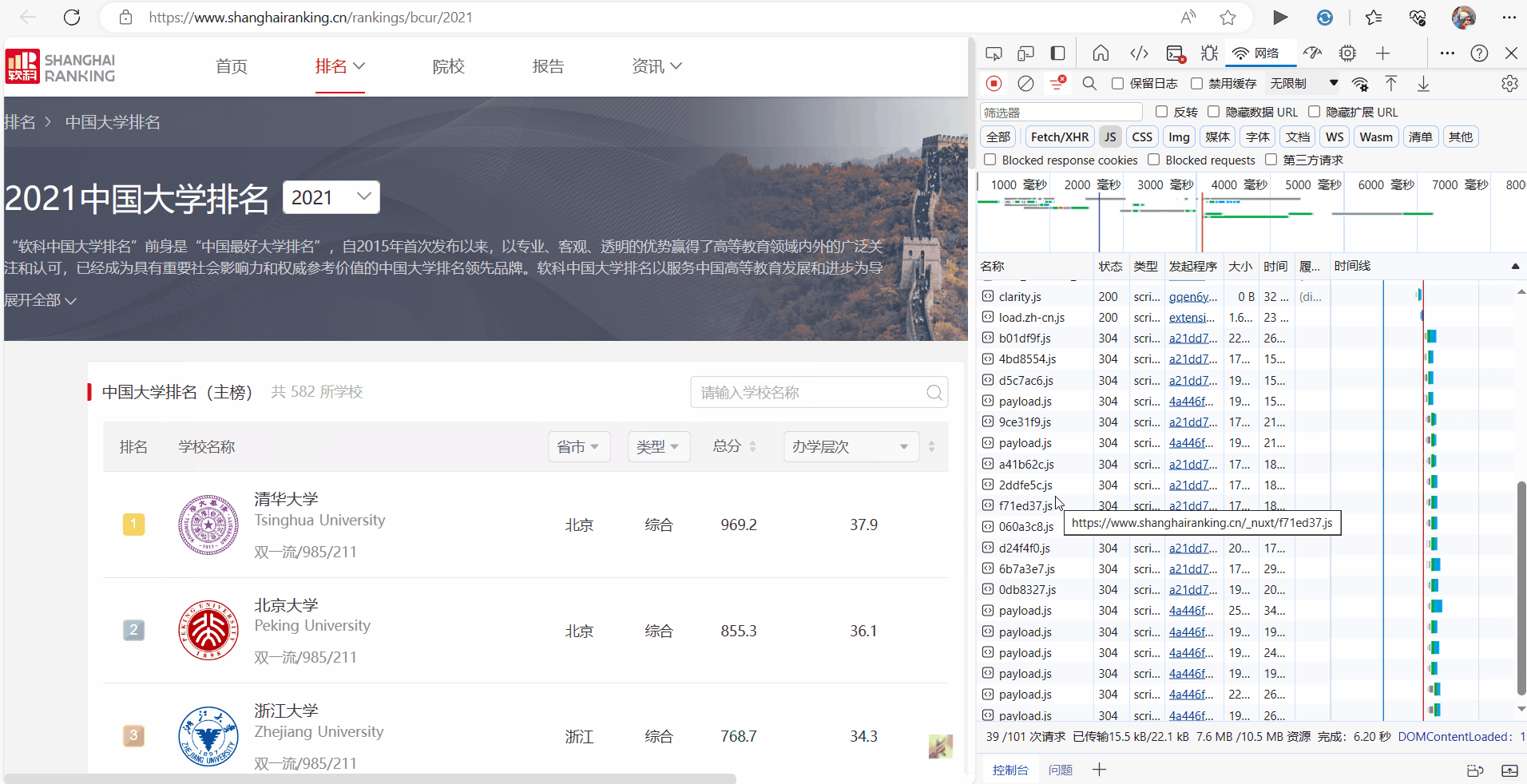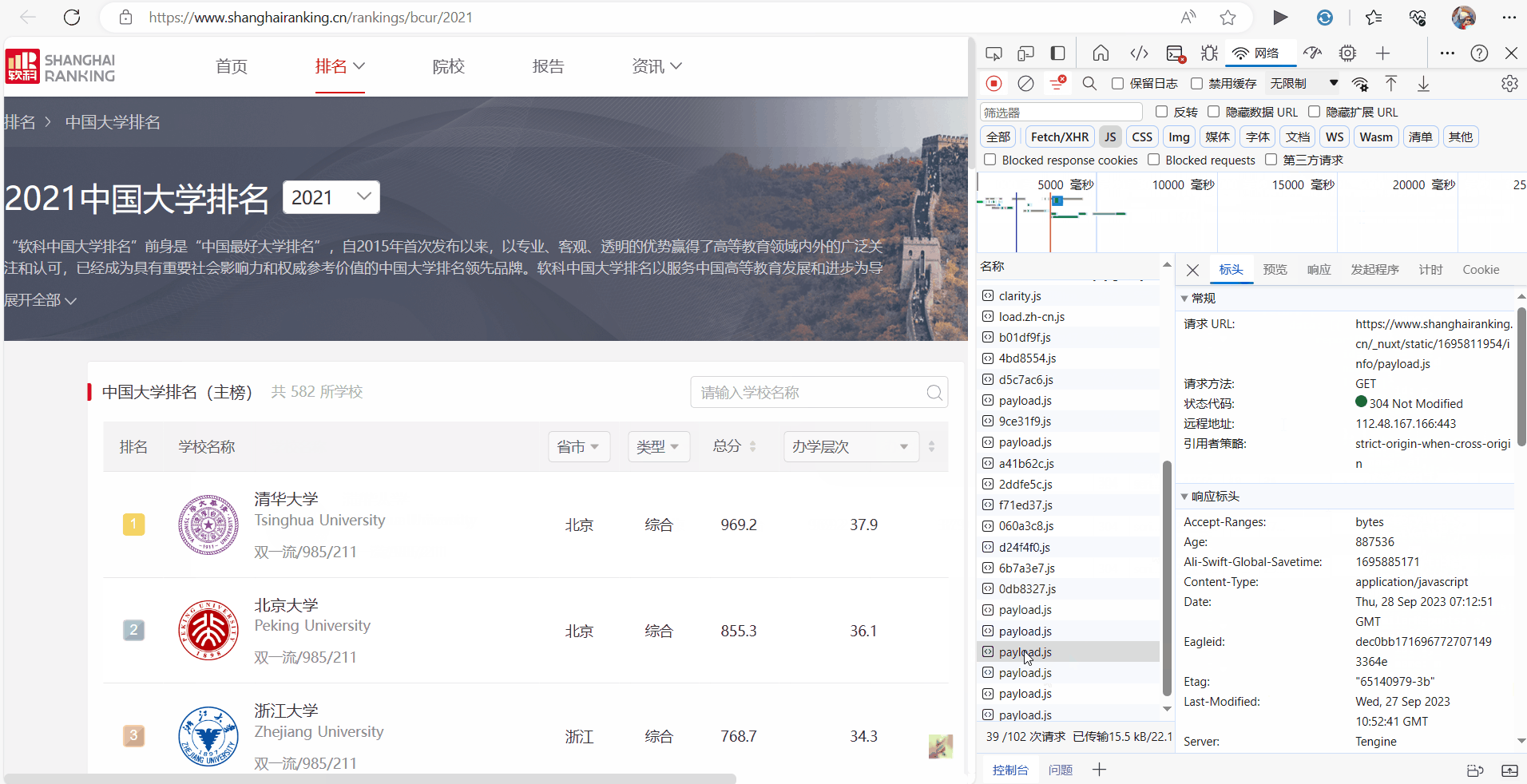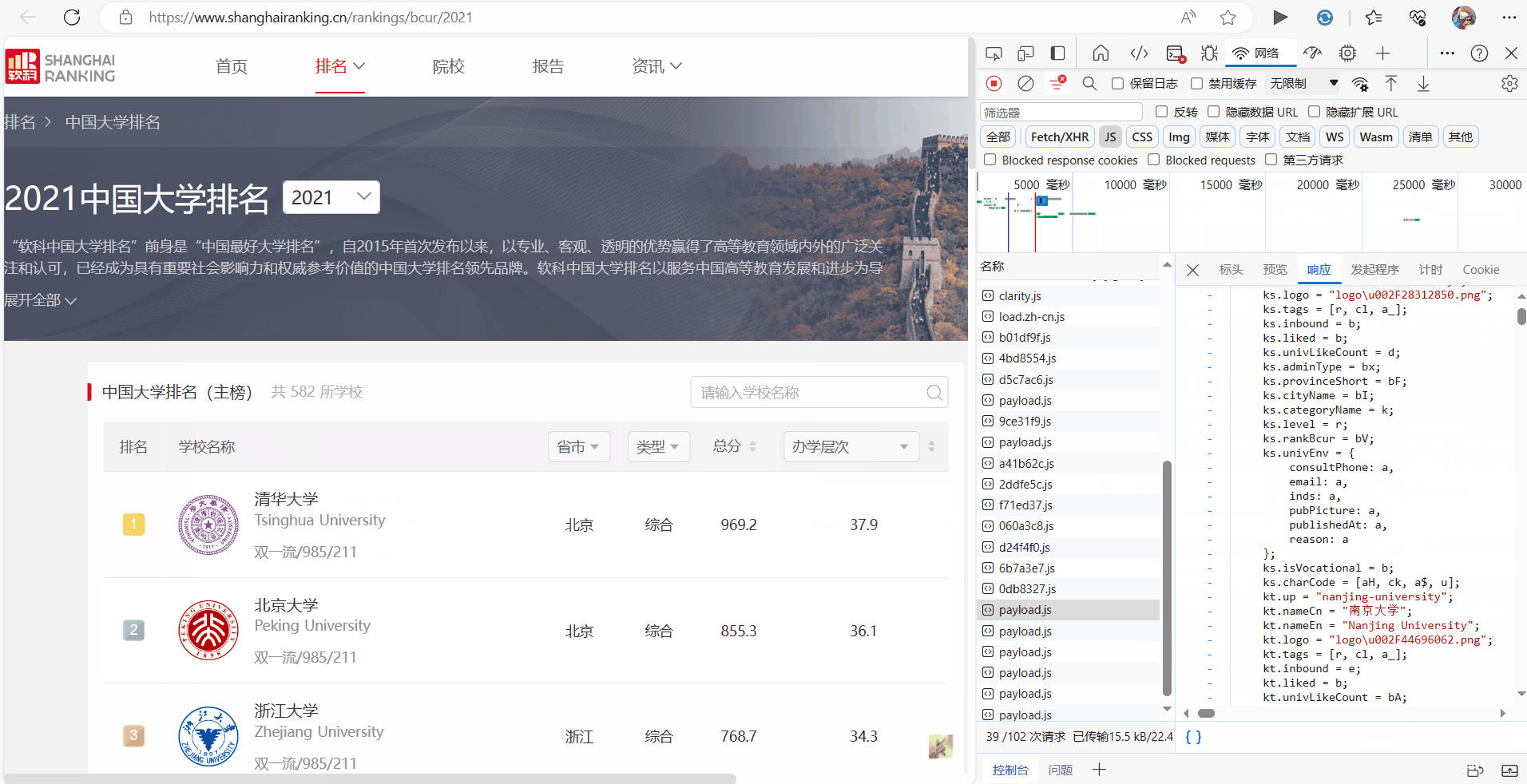
代码:
核心程序
def getContent(html):
namelist = re.findall("'univNameCn': '(.*?)'",html,re.S|re.M)
#print(namelist)
scorelist = re.findall("'score': (.*?),",html,re.S|re.M)
#print(scorelist)
provincelist = re.findall("'province': '(.*?)'",html,re.S|re.M)
categorylist=re.findall("'univCategory': '(.*?)'",html,re.S|re.M)
collegedb = collegeDB()
collegedb.openDB()
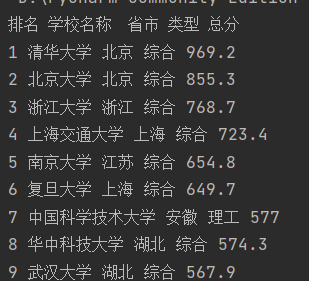
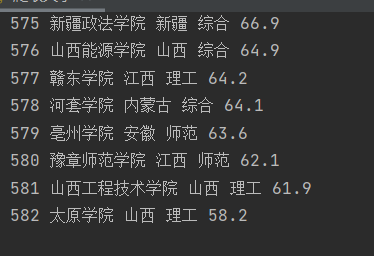
print("排名\t学校名称\t省市\t类型\t总分")
num = 1
for i in range(len(namelist)):
print(num,namelist[i],provincelist[i],categorylist[i],scorelist[i])
collegedb.insert(num,namelist[i],provincelist[i],categorylist[i],scorelist[i])
num += 1
初始化数据库
class collegeDB:
def openDB(self):
self.con = sqlite3.connect("colleges.db") # 连接数据库
self.cursor = self.con.cursor() # 设置一个游标
try:
self.cursor.execute("create table colleges(Rank varchar(10),Schoolname varchar(10),Province varchar(10),Category varchar(10),Score varchar(10))")
except:
self.cursor.execute("delete from colleges")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,rank,schoolname,province,category,score):
try:
self.cursor.execute("insert into colleges(Rank,Schoolname,Province,Category,Score) values (?,?,?,?,?)", (rank, schoolname,province,category,score))
except Exception as err:
print(err)
输出结果:

心得和体会:
这个实验最大的难点是js点进去是全乱码,完全看不懂,直接导致了我爬取的列表是空的!!!一开始完全摸不着头脑,把它解析出来才知道问题出在哪里!!!(这里感谢我的大佬同学提供的代码救我一命!!!!)

正则表达式就差一个空格!!!!!!
把正则表达式写对后面就没什么问题了。
码云链接
本文作者:yyiiing
本文链接:https://www.cnblogs.com/yyiiing/p/17750269.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步