2023数据采集与融合技术实践第一次作业
作业①:
要求:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
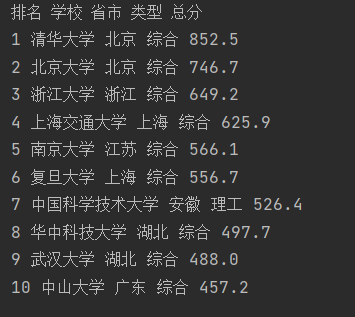
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
代码:
核心程序
soup = BeautifulSoup(html, "html.parser")
list = soup.select("tbody tr") #找到每一行
print("排名\t学校\t省市\t类型\t总分")
for item in list[0:10]:
ls = item.select("td") #排行榜本质是表格,找到每一个单元格
inf = []
for i in ls[0:5]:
if i == ls[1]: #当读取大学名称的时候,只读出xx大学
text = i.find("a").text.replace(" ", "").replace("\n", "")
else:
text = i.text.replace(" ", "").replace("\n", "")
inf.append(text)
print(inf[0],inf[1],inf[2],inf[3],inf[4])
输出结果
心得体会
本质上还是要回归页面源代码,通过F12查看每个元素之间的关系,再通过bs库逐层遍历找到需要的数据。
一开始输出每个单元格数据时没有进行特殊处理,直接用以下代码
text = i.text.replace(" ", "").replace("\n", "")
在输出大学名称的时候会连带着输出英文名+双一流/985/211等一长串丑丑的东西,查看对应元素代码时才发现在该单元格内,大学名称又被藏在了a标签下,于是使用了一个特殊判别~
本来想控制一下输出对齐的,format后发现连输出都没了!!!于是作罢。
作业②:
要求:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
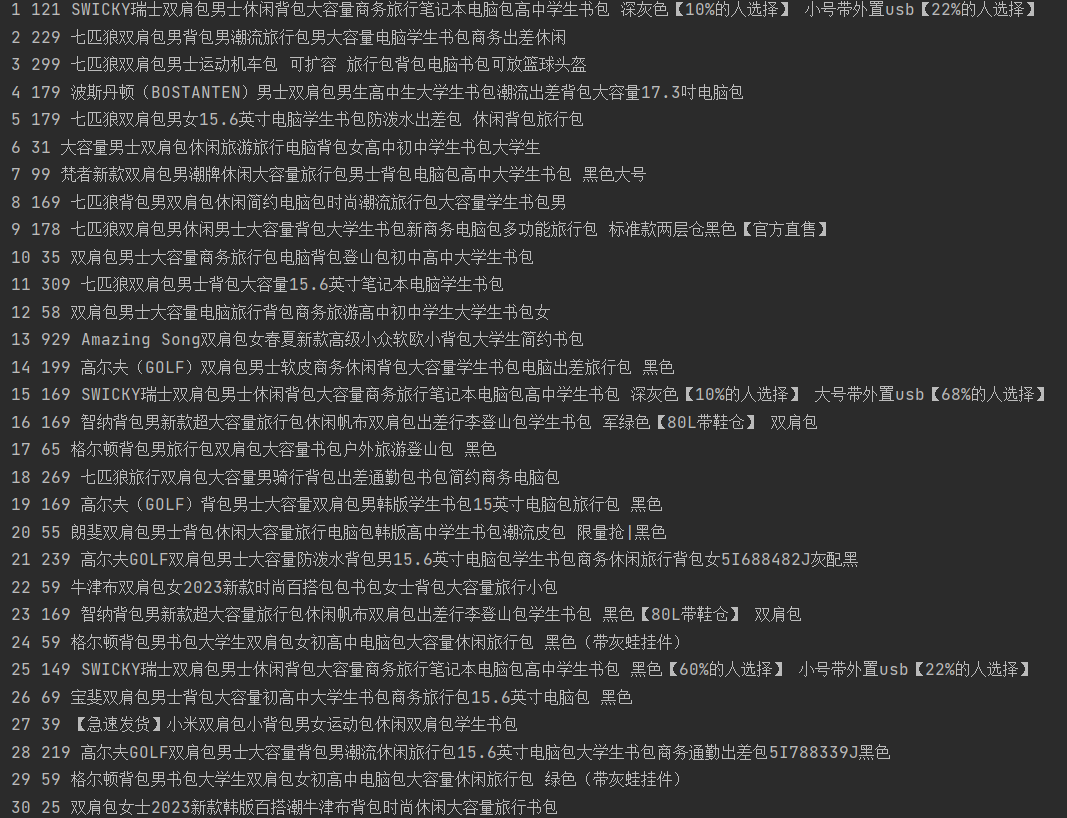
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
代码:
核心程序
def parsePage(data): #取出需要的数据
plt = re.findall(r'data-price="\d+', data) #找到每一个商品的价格
tlt = re.findall(r'class="item-title".+"', data) #找到每一个商品名称
#print(plt)
#print(tlt)
for item in tlt:
item1 = item.split('"')[5] #除去名称前用于定位的表达式
titlelist.append(item1)
for item in plt:
item2 = item.split('"')[1]
pricelist.append(item2)
输出结果
心得体会
先要哀嚎一声正则表达式真的难上手啊(发出尖锐的爆鸣),但是上手之后就会很快速地找到自己想要的东西。
一开始准备爬当当、京东等叫得上名的网站的,结果发现这些网站的商品名称都被拆成了一段一段的,尝试了一番没有输出后转投小网站——(比如淘宝比价网什么的~)
然后又陷入误区,因为商品名称基本是放在a标签里的,就会有一些奇奇怪怪的东西belike:

所以一开始以为要从标签的最开始进行匹配,结果找到了一堆网页最开始的小标题==,然后才意识到可以从唯一标识商品名称的地方开始匹配!在这里就是item-title啦。
代码里用了split来去掉标签里的描述,其实最开始想用replace但是没成功不知道为什么捏,最后就是以为小网站比较没有关系于是肆无忌惮的print结果ip被禁了一会会……(罪过罪过)
555这道题改了好几个小时但是最后输出的时候真的非常有成就感T T
小tips:写正则表达式的时候可以用一些在线检测的网站来查看自己写得对不对!
作业③:
要求:
爬取一个给定网页或者自选网页的所有JPEG和JPG格式文件(https://xcb.fzu.edu.cn/info/1071/4481.htm
输出信息:
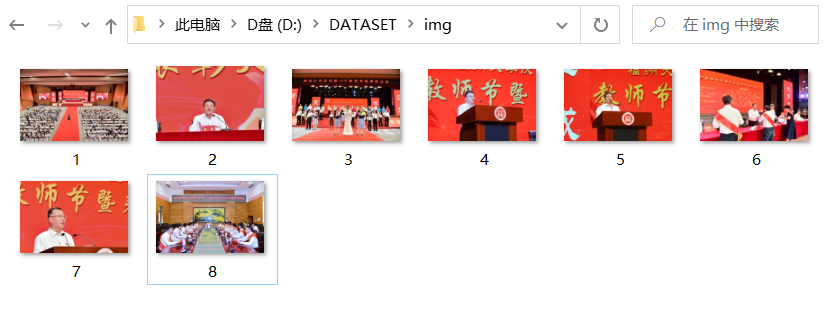
将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码:
核心程序
x = 1
pic = soup.find_all('img')
for i in pic:
imgsrc=i.get('src')
#print(imgsrc)
filename = 'D:/DATASET/img/%s.jpg' %x #保存路径
x+=1
urllib.request.urlretrieve('http://xcb.fzu.edu.cn'+imgsrc, filename)
输出结果
心得体会
爬取图片的时候,路径如果只写到文件夹会报错没有访问权限,必须要具体到每个的文件名。代码里简单粗暴地把所有图片保存为jpg格式对本题适用,但是如果原图是png格式可能会出错,暂时没想到好的解决办法。
码云链接
本文作者:yyiiing
本文链接:https://www.cnblogs.com/yyiiing/p/17723792.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步