


数据采集实践作业1
作业一
(1)实验内容
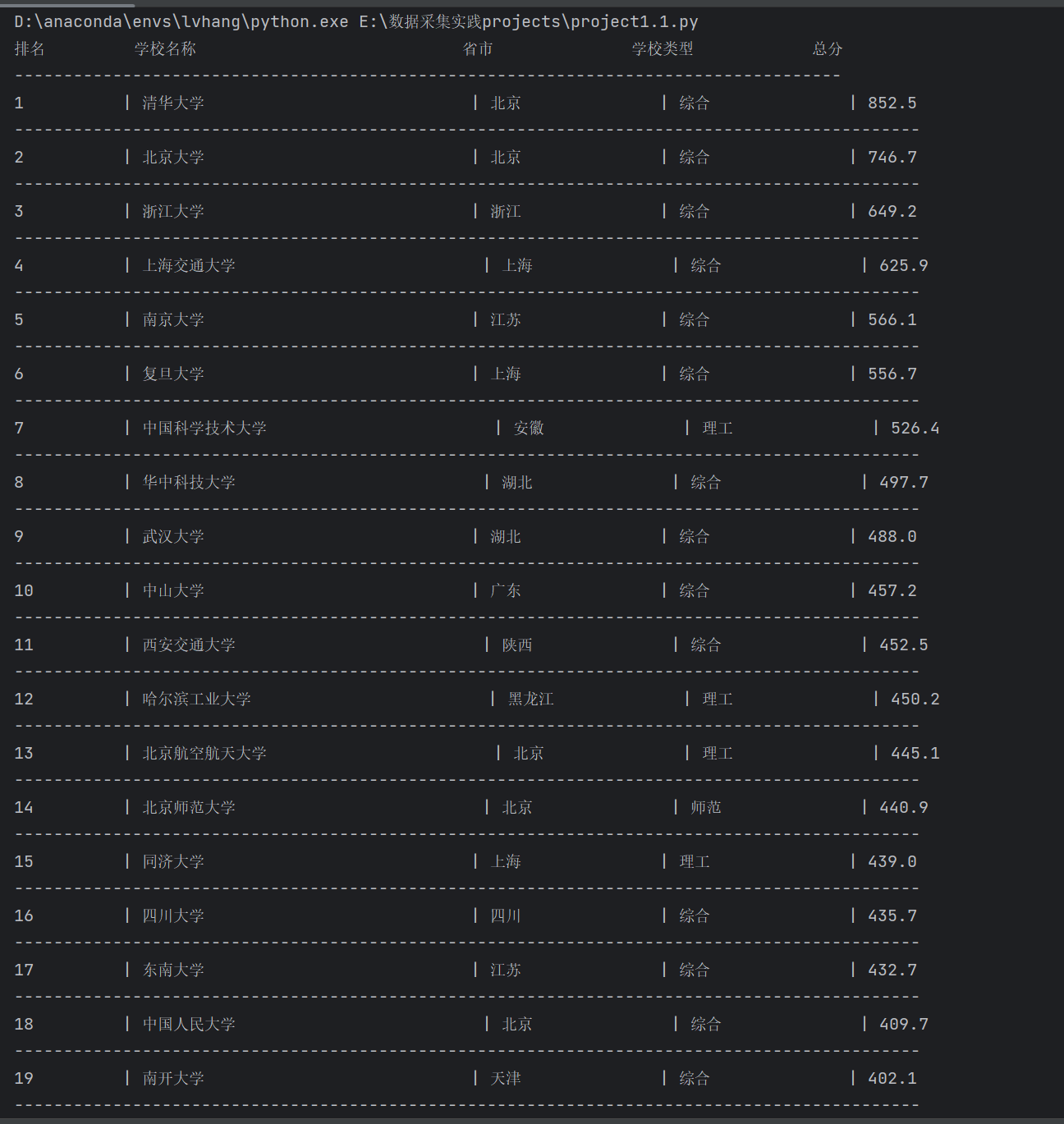
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码如下:
import requests
from bs4 import BeautifulSoup
import re
# 指定要爬取的网址
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 发送GET请求获取网页内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 设置正确的编码
response.encoding = response.apparent_encoding
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到大学排名信息
table = soup.find('table')
# 打印表头
header = f"{'排名':<10} {'学校名称':<30} {'省市':<15} {'学校类型':<15} {'总分':<10}"
print(header)
print('-' * len(header)) # 打印分隔线
# 遍历表格行获取数据
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
if len(cols) >= 5: # 确保有足够的列
rank = cols[0].text.strip() # 获取排名
# 获取学校名称并去除多余信息
university = cols[1].text.strip()
university_cleaned = re.sub(r'\s*(.*?)', '', university) # 去除括号及其内容
university_cleaned = university_cleaned.split()[0] # 取第一个部分
province_city = cols[2].text.strip() # 获取省市
school_type = cols[3].text.strip() # 获取学校类型
total_score = cols[4].text.strip() # 获取总分
# 打印每一行数据
row_output = f"{rank:<10} | {university_cleaned:<30} | {province_city:<15} | {school_type:<15} | {total_score:<10}"
print(row_output)
print('-' * len(row_output)) # 打印分隔线
else:
print(f'请求失败,状态码: {response.status_code}')
结果如下:
(2)心得体会
在编写这段爬虫代码的过程中,我获得了一些重要的心得体会:
- 网页解析的重要性:
- 使用
BeautifulSoup进行网页解析是非常有效的。它提供了方便的方法来查找和提取数据,使得处理HTML结构变得更加直观和简单。
- 使用
- 数据清理的必要性:
- 在提取学校名称时,通过正则表达式和字符串操作对数据进行清理是必不可少的。这不仅提高了数据的准确性,也使得最终输出更加专业和易于理解。
- 格式化输出的技巧:
- 使用格式化字符串(如
f"{value:<width}")可以轻松控制输出的对齐方式,增强了数据的可读性。同时,通过添加分隔符和横线,使得表格的结构更加清晰,有助于快速定位信息。
- 使用格式化字符串(如
- 错误处理的考虑:
- 在进行网络请求时,检查响应状态码是一个良好的实践。这确保了程序在遇到网络问题或请求失败时能够合理地处理异常情况,而不是直接崩溃。
- 模块化与复用:
- 将不同功能(如发送请求、解析数据、格式化输出)进行模块化处理,使得代码更具可读性和可维护性。在未来的项目中,可以考虑将这些功能进一步封装成函数或类,以实现更好的代码复用。
- 持续学习与实践:
- 爬虫技术与数据处理是一个不断发展和变化的领域。通过实践,可以加深对技术细节的理解,并发掘更多的应用场景,比如数据可视化或分析等。
总的来说,这段代码不仅让我掌握了基本的网页爬虫技术,还让我意识到数据处理和输出格式化的重要性。在未来的项目中,我希望能将这些经验应用到更复杂的爬虫和数据分析任务中。
作业二
(1)实验内容
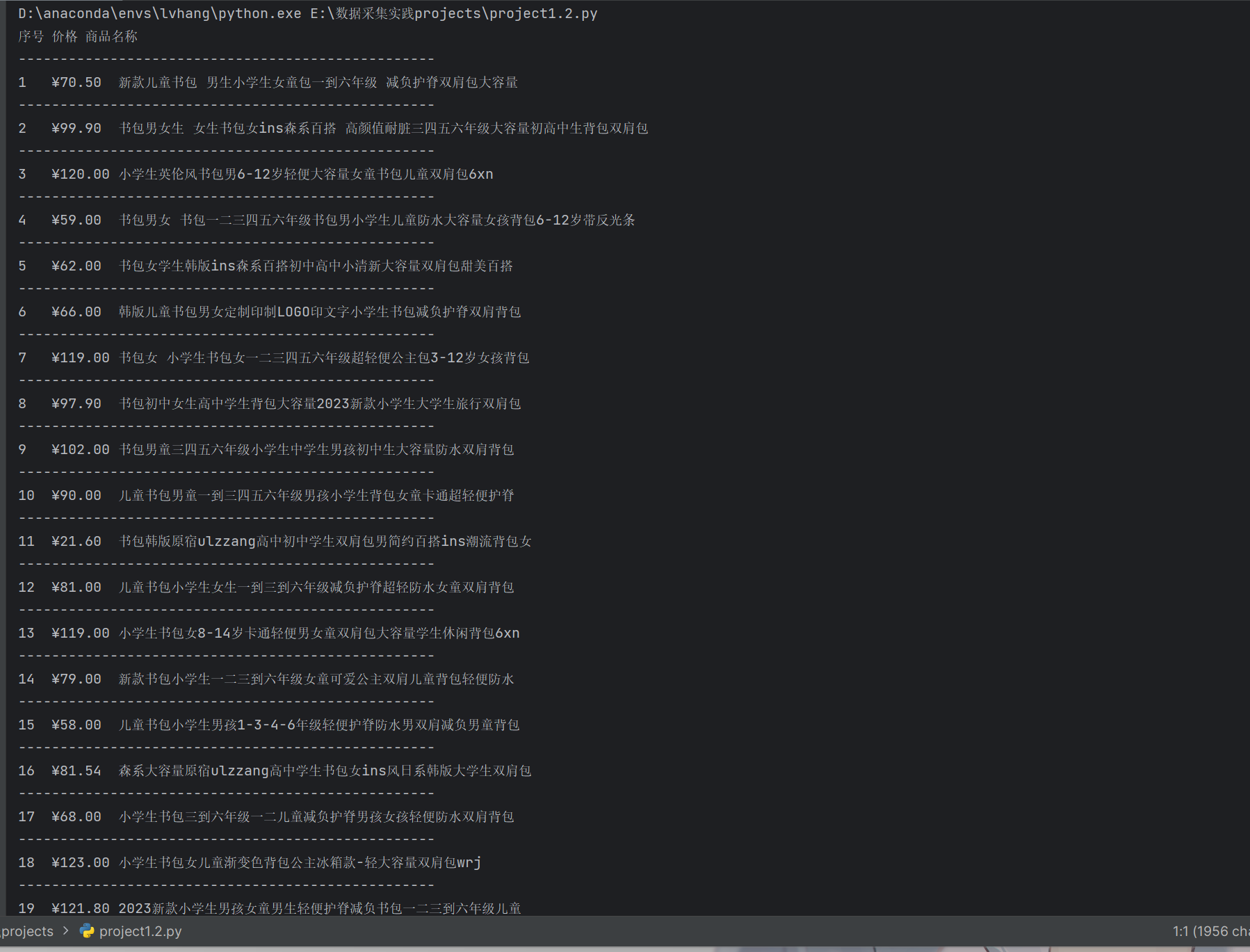
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码如下:
import requests
from bs4 import BeautifulSoup
# 函数:获取指定URL的页面内容
def fetch_page(url, headers):
try:
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status() # 检查请求是否成功
response.encoding = response.apparent_encoding
return response.text
except requests.RequestException as error:
print(f"请求失败: {error}")
return None
# 函数:提取产品名称和价格
def extract_product_details(html_content):
if html_content is None:
return []
soup = BeautifulSoup(html_content, 'lxml')
product_info_list = []
# 查找所有商品列表项
product_items = soup.find_all('li')
for product in product_items:
try:
# 获取产品名称
title_tag = product.find('a', attrs={'dd_name': '单品图片'})
product_name = title_tag['title'].strip() if title_tag else None
# 获取产品价格
price_tag = product.find('span', class_='price_n')
product_price = price_tag.text.strip() if price_tag else None
if product_name and product_price:
product_info_list.append((product_name, product_price)) # 添加到列表
except Exception:
continue # 跳过异常,继续处理下一个条目
return product_info_list
# 函数:打印产品信息
def display_product_info(products):
print('序号\t价格\t商品名称')
print('-' * 50) # 打印分隔线
for index, (name, price) in enumerate(products, start=1):
print(f"{index}\t{price}\t{name}")
print('-' * 50) # 每行后打印分隔线
# 主程序执行入口
if __name__ == '__main__':
search_url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 获取页面内容
content = fetch_page(search_url, request_headers)
# 解析产品详情
products = extract_product_details(content)
# 显示产品信息
display_product_info(products)
结果如下:
(2) 心得体会
1. 理解网络请求
通过使用requests库,我对HTTP请求的基本流程有了更深入的认识,包括如何设置请求头、处理超时和异常情况等。response.raise_for_status()方法的应用,能够有效地捕获请求失败的情况,从而提高代码的健壮性。
2. 数据解析的重要性
使用BeautifulSoup进行HTML解析让我认识到,理解网页的DOM结构是数据提取的关键。能够迅速定位到需要的数据(如产品名称和价格),使我能更高效地提取信息。在实际操作中,熟悉各种查找方法(如find_all、find)也非常重要。
3. 异常处理与容错机制
在提取商品信息时,使用了异常处理来跳过无法解析的条目。这种策略保证了程序的稳定性,使得即使遇到一些问题也能继续处理其他数据。这一点在编写爬虫时尤为重要,因为网页内容可能会不一致或者发生变化。
4. 数据展示的实践
实现display_product_info函数时,我意识到清晰地展示数据对于用户体验至关重要。通过格式化输出,可以让结果更加易读和直观,这对后续的数据分析和展示都非常有帮助。
5. 学习到的工具和库
这个项目让我更加熟悉了Python中的lxml解析器,它提供了更好的性能和灵活性。同时,掌握了如何通过设置User-Agent来模拟真实用户访问,避免因爬虫行为而被网站封禁。
6. 爬虫设计的可扩展性
虽然当前的爬虫仅限于提取商品名称和价格,但我意识到可以通过增加更多的提取逻辑(如产品链接、评分等)来拓展功能。这种模块化的设计思路有助于后续的维护和升级。
总结
整体而言,这次爬虫编写的实践不仅提高了我的编程技能,还让我了解了爬虫开发过程中的各种挑战和解决方案。未来我希望能继续深化对爬虫技术的理解,探索更复杂的爬虫场景,如处理动态网页和反爬虫机制等。
作业三
(1)实验内容
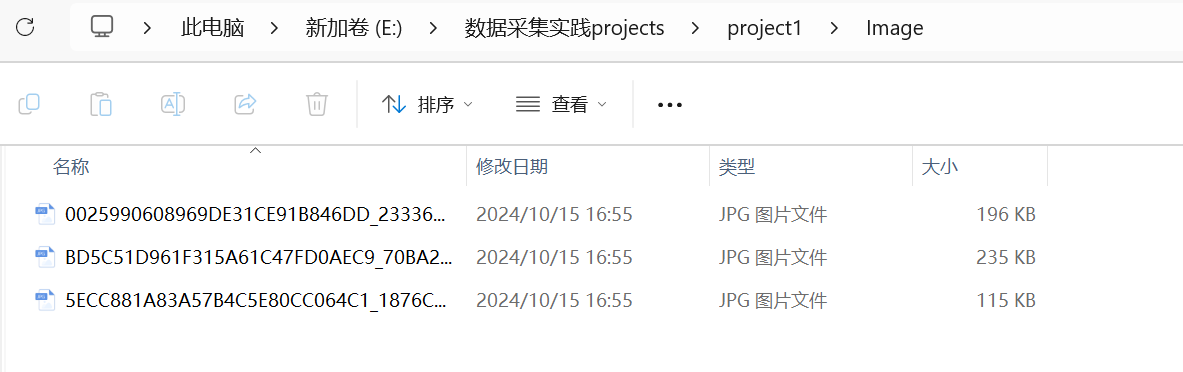
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码如下:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 设置目标网页和保存路径
url = 'https://news.fzu.edu.cn/yxfd.htm'
save_dir = r'E:\数据采集实践projects\project1\Image'
# 创建保存目录(如果不存在)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 函数:下载图片
def download_image(image_url):
try:
response = requests.get(image_url, timeout=30)
response.raise_for_status() # 检查请求是否成功
with open(os.path.join(save_dir, os.path.basename(image_url)), 'wb') as f:
f.write(response.content)
print(f"下载成功: {image_url}")
except Exception as e:
print(f"下载失败: {image_url}. 错误: {e}")
# 获取网页内容
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有JPEG和JPG格式的图片
img_tags = soup.find_all('img')
for img in img_tags:
img_url = img.get('src')
if img_url:
# 确保URL是完整的
img_url = urljoin(url, img_url)
if img_url.lower().endswith(('.jpeg', '.jpg')):
download_image(img_url)
except Exception as e:
print(f"无法访问网页: {url}. 错误: {e}")
结果如下:

(2)心得体会
1. 实践是最好的学习方式
通过实际编写爬虫代码,我对Python的requests和BeautifulSoup库有了更深入的理解。理论知识虽然重要,但实践中的问题和挑战能帮助我更好地巩固所学。
2. 重视错误处理
在爬取网页时,遇到网络请求失败、链接失效或文件下载失败等问题是常见的。因此,良好的错误处理机制至关重要。添加异常捕获可以使程序更加健壮,避免因小错误导致整个程序崩溃。
3. 页面结构的重要性
每个网页的HTML结构可能不同,了解和解析这些结构是成功爬取数据的关键。在分析目标网页时,使用浏览器的开发者工具查看元素的结构,可以帮助快速定位需要抓取的数据。
4. 遵守爬虫规范
在爬取数据时,要遵循网站的爬虫规则,尊重版权和数据使用政策。这不仅是对网站的尊重,也能避免法律风险。
5. 持续学习与优化
在这个过程中,我意识到还有许多可以提升的地方,比如提高爬虫的效率、学习如何处理动态加载的数据(如使用Selenium等工具)等。爬虫技术是一个不断发展的领域,持续学习非常重要。
6. 数据清洗与存储
获取数据之后,如何有效地清洗和存储也是一个重要的环节。对于爬取的图片,考虑如何命名和管理文件,可以让后续的使用变得更加方便。
总结
整体来说,这次爬虫实践让我不仅学到了技术知识,也提高了我的问题解决能力和思维方式。未来在数据采集或分析的工作中,我将更加注重这些经验,并继续探索更多的相关技术和方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY