


2022CVPR_SNR-Aware Low-light Image Enhancement(SNR)
一. motivation
对于区域含有较高的峰值信噪比(SNR)则可利用局部信息进行图像增强,但是对于区域含有很低的SNR,则无法利用局部信息,此时非局部信息就非常重要
二. contribution
提出(1)一个利用卷积结构设计的短分支方便利用局部信息,一个利用transformer结构设计的长分支方便利用全局信息
(2)在transformer中利用SNR引导的自注意self-attention, 利用SNR进行长短分支的特征融合
三.Network
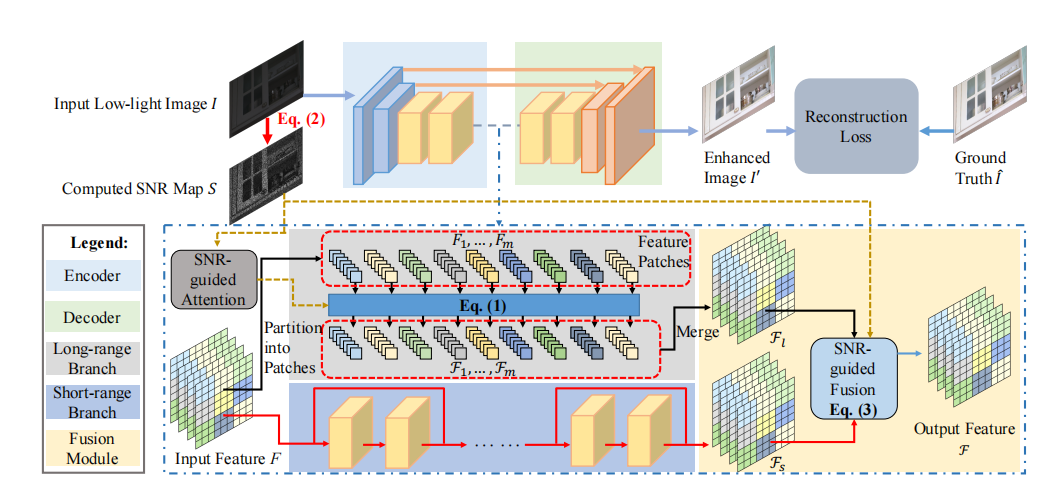
1. 对于低光照的图片首先采用公式2获得SNR Map
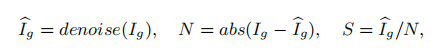
(1)Ig:是低光图片  :是经过cv.blur进行均值滤波后的图像
:是经过cv.blur进行均值滤波后的图像
(2) 对Ig和Ig' 取得灰度图进行绝对值相减得到噪声N
(3)SNR(mask):均值滤波后的图像与噪声相除得到S
2. 先进行浅层特征提取
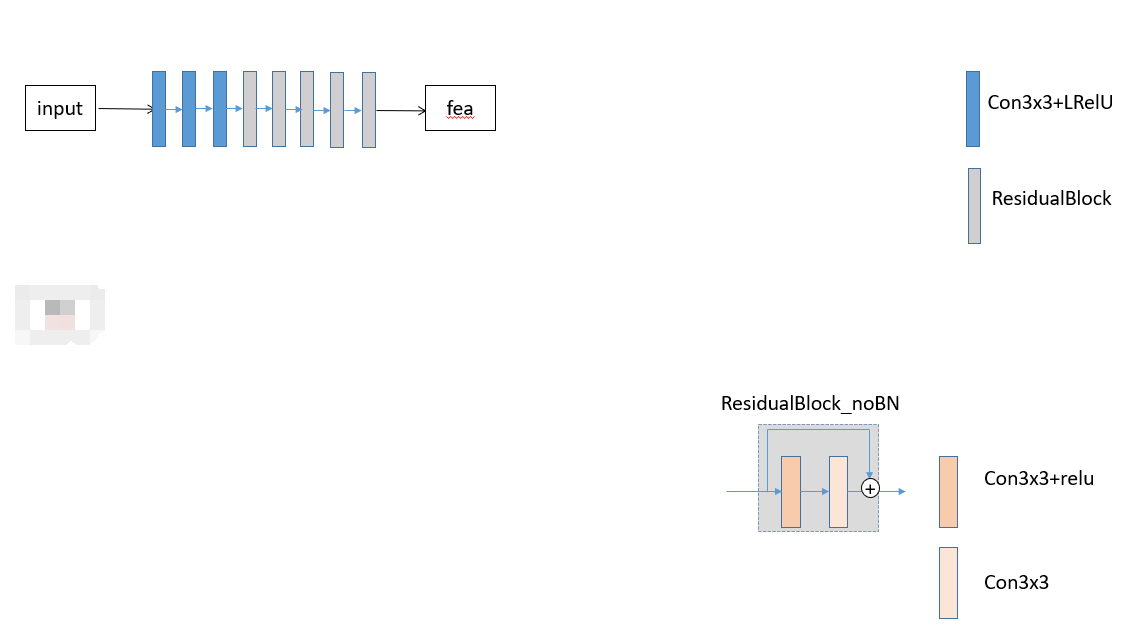
3. 对于fea进行深层特征提取,fea进行两个分支,一个分支(短分支)进行卷积块(更容易捕获局部信息)进行残差连接,另外一个分支(长分支)进行SNR引导的transformer结构(更容易捕获全局信息)
短分支结构:
普通的两个卷积操作+跳连接形成一个残差块,如此循环6次得到经过短分支结构的Fs

长分支结构
(1)首先利用F.unfold展成n个patch,以后放入transformer中进行计算
(2)transformer结构就是归一化+ 多头 self attention + FFN(前馈网络)组成
(3)SNR主要体现在多头自注意中
softmax:Softmax函数计算每个元素的指数函数和,然后对所有元素求和以得到归一化的概率分布。

σ 是一个非常小的负标量−1e9。当S’为0时 (1-S')σ = σ 此时再进行softmax后就会得到0,这意味着SNR很低的地方不会计算到注意力中,当S'=1,(1-S')σ = 0从而实现SNR引导的自注意计算
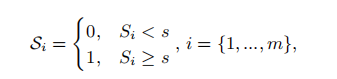
SNR引导的特征融合
再利用mask: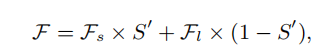 进行特征融合
进行特征融合
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
详解:
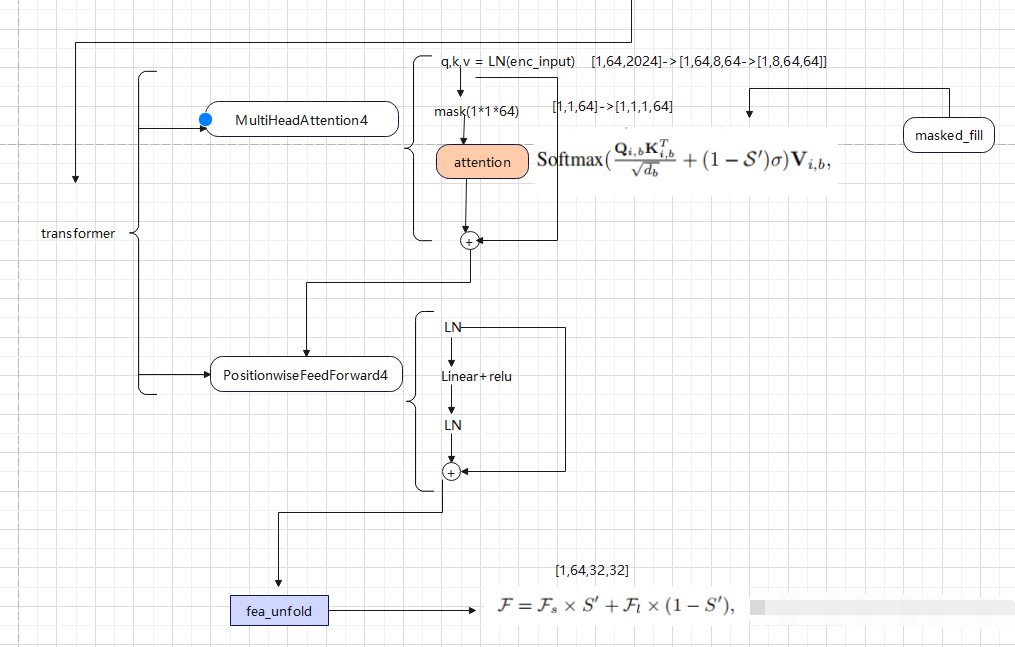

transformer包括Attention和FeedForward
对于Attention,对输入的特征进行归一化分别赋给q,k,v
q*k的转置是查看patch之间的相似度
对于mask的操作: 将mask分成s’个pacth,之后按照dim=2取得了mask的均值,采用公式,如果mask 的均值<0.5 则 取值为0,便于后面attention操作
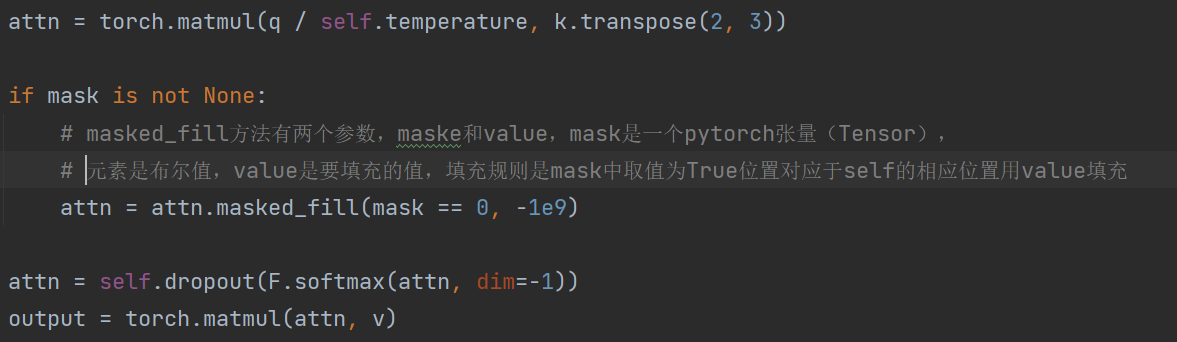
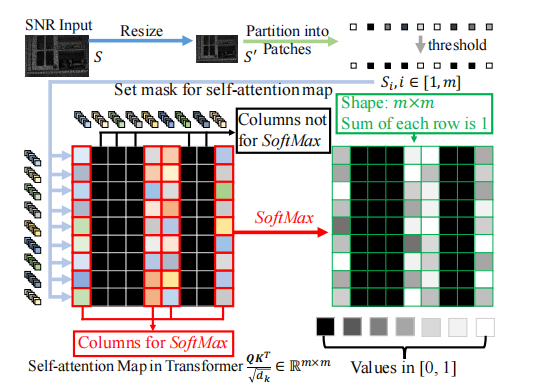
对于mask取值为0的地方,attn中填充为很大的负数,在计算softmax这部分像素值不会发生变化
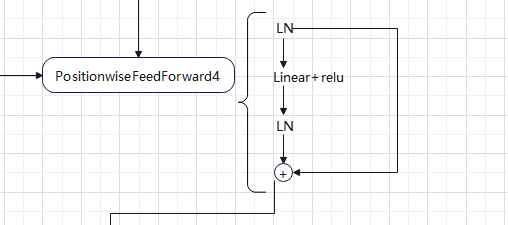
FeedForward: 首先归一化,之后全连接+relu,再归一化,一个跳连接。最后输出经过transformer结构的fea_unfold
再利用mask:进行特征融合
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
四. 两个损失
1.CharbonnierLoss2:用Charbonnier Loss来近似 损失来提高模型的性能
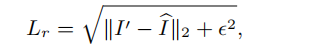
大佬链接:https://blog.csdn.net/weixin_43135178/article/details/120865709

class CharbonnierLoss2(nn.Module): """Charbonnier Loss (L1)""" def __init__(self, eps=1e-6): super(CharbonnierLoss2, self).__init__() self.eps = eps def forward(self, x, y): diff = x - y loss = torch.mean(torch.sqrt(diff * diff + self.eps)) return loss
2. perceptual loss:用VGG19提取特征(关于内容的一个损失)

对于nn.L1Loss中reduction的说明:https://blog.csdn.net/qq_39450134/article/details/121745209
import torchvision class VGG19(torch.nn.Module): def __init__(self, requires_grad=False): super().__init__() vgg_pretrained_features = torchvision.models.vgg19(pretrained=True).features self.slice1 = torch.nn.Sequential() self.slice2 = torch.nn.Sequential() self.slice3 = torch.nn.Sequential() self.slice4 = torch.nn.Sequential() self.slice5 = torch.nn.Sequential() for x in range(2): self.slice1.add_module(str(x), vgg_pretrained_features[x]) for x in range(2, 7): self.slice2.add_module(str(x), vgg_pretrained_features[x]) for x in range(7, 12): self.slice3.add_module(str(x), vgg_pretrained_features[x]) for x in range(12, 21): self.slice4.add_module(str(x), vgg_pretrained_features[x]) for x in range(21, 30): self.slice5.add_module(str(x), vgg_pretrained_features[x]) if not requires_grad: for param in self.parameters(): param.requires_grad = False def forward(self, X): h_relu1 = self.slice1(X) h_relu2 = self.slice2(h_relu1) h_relu3 = self.slice3(h_relu2) h_relu4 = self.slice4(h_relu3) h_relu5 = self.slice5(h_relu4) out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5] return out class VGGLoss(nn.Module): def __init__(self): super(VGGLoss, self).__init__() self.vgg = VGG19().cuda() # self.criterion = nn.L1Loss() self.criterion = nn.L1Loss(reduction='sum') self.criterion2 = nn.L1Loss() self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0] def forward(self, x, y): x_vgg, y_vgg = self.vgg(x), self.vgg(y) loss = 0 for i in range(len(x_vgg)): # print(x_vgg[i].shape, y_vgg[i].shape) loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach()) return loss


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】博客园携手 AI 驱动开发工具商 Chat2DB 推出联合终身会员
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开箱你的 AI 语音女友「GitHub 热点速览」
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(二):用.NET IoT库
· 几个自学项目的通病,别因为它们浪费了时间!
· C#钩子(Hook) 捕获键盘鼠标所有事件 - 5分钟没有操作,自动关闭 Form 窗体
· 特斯拉CEO埃隆.马斯克的五步工作法,怎么提高工程效率加速产品开发?
2018-05-04 五种方式实现点击按钮显示输入的信息