


2022CVPR_Toward Fast, Flexible, and Robust Low-Light Image Enhancement(SCI_main)
1. motivation
(1)低光增强不能处理复杂的场景
(2)需要耗费大量的计算
2.contribution
(1)节省计算
(2)发明了自监督的SCI模块(SCI的核心是引入额外的网络模块(自校准照明)来辅助训练,而不是用于测试)
3. Network

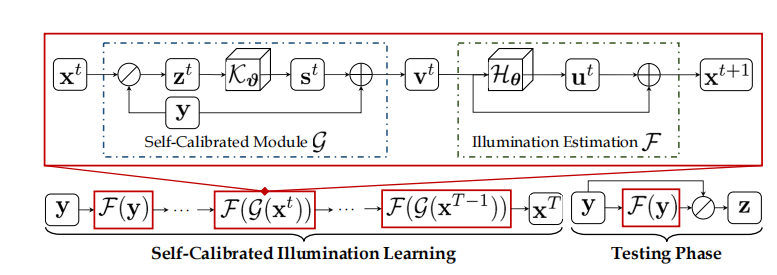
整个结构分为两部分:Self-Calibrated Module(自校正模块)和 Illumination Eastimation(照明估计模块),其中的自校正模块是一个辅助作用模块,用来减轻级联模式的计算负担。
其中
光照估计:

ut:第t阶段的残差------计算残差的方式可以极大的减少计算量和保持稳定,尤其对于曝光控制会有很好的能力。
(感觉就是ResNet思想,在这里的作用就是通过级联网络的形式每个阶段学习一点光照量,最终把整个的光照量学习到。)
Xt:第t阶段的光照
Hθ:光照估计网络,并且Hθ与阶段数无关,即在每一阶段光照估计网络均保持结构与参数共享状态
Self-Calibrated Module:作用使每个阶段的结果收敛到同一状态
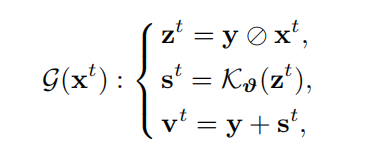

4、损失
保真度损失Lf和平滑损失Ls;α和β是两个平衡参数:
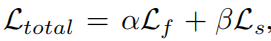
(1)Lf保真度损失(为了是保持像素的一致性):用的是nn.MSELoss()
目的是默认用于计算两个输入对应元素差值平方和的均值
公式表示: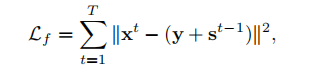 T代表的是校正T阶段的数量
T代表的是校正T阶段的数量
别人解释:Lf用于保证估计照度和每个阶段输入之间的像素级一致性;T为总级数。
xt是t阶段的光照量,括号内部分是经过自校正模块后得到的辅助量v(t-1),自校准模块的作用是想使每个阶段的结果趋于一致,那么就需要保证这两个量在每个阶段应该是非常近似的才行。
括号内部表示的就是 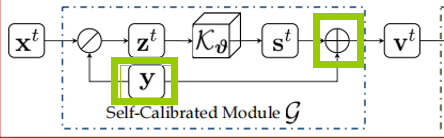
(2)Ls:

对于标题的体现
1、体现fast:
(1)训练时使用两个网络::CalibrateNetwork+EnhanceNetwork
增强网络只使用了3个ConV2d(kernel_size = 3*3)分离光照i和反射r, 校准网络使用了4个ConV2d(kernel_size = 3*3)
(2)测试时仅使用增强网络:EnhanceNetwork
在网络中还使用了学习残差降低了计算难度,保证了性能,也提高了稳定性。所以运算时间大大提升。
2、体现Flexible:
自校准网络:CalibrateNetwork适用于RUAS(cvpr’21)等其他低光增强网络,论文中验证了在RUAS中加入CalibrateNetwork后的视觉效果与性能指标

3、体现Robust:
除了在低光图像增强数据集上进行验证之外,在夜脸检测与夜间语义分割数据集上进行测试。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
2018-05-03 优化apk
2018-05-03 apk打包
2018-05-03 更改软件界面内容(第二章)